Pengujian Komponen Xquery – Program xquery memiliki banyak sekali komponen yang sengaja disertakan untuk melengkapi dan memudahkan dalam proses pemrograman dan pembuatan html. Komponen yang diberikan tersebut memiliki manfaat yang cukup besar untuk penggunanya dalam rangka menyusun program html yang jauh lebih sederhana namun sarat akan informasi yang akurat. Komponen-komponen tersebut sengaja diberikan untuk mempermudah proses pemrograman html yang diperlukan. Tanpa adanya komponen-komponen tersebut tentu akan sulit untuk membuat program yang sesuai dengan harapan dan tujuan dari pemanfaatan program. Komponen dalam xquery diberikan sengaja untuk melengkapi kekurangan pada program xquery pada versi sebelumnya. Tujuannya adalah untuk meminimalisir terjadinya kesalahan atau bug pada program html yang dijalankan oleh pengguna.
Komponen yang diberikan di dalam program versi terbaru dari xquery diantaranya adalah program satu baris. Program komponen satu baris memungkinkan pengguna untuk membuat label-lebel dalam satu baris tertentu yang tentu saja akan menghemat ruang penyimpanan. Selain dapat menghemat ruang penyimpanan, komponen satu baris membuat proses labelisasi bisa dijalankan dengan optimal dengan ruang yang minimal. Hal ini menunjukkan kapasitas xquery bahwa xquery mampu menjadi program yang akan mempermudah sekaligus membuat efisien kinerja dari prosesor html yang digunakan. Sebab di dalam menjalankannya tidak diperlukan ruang penyimpanan yang besar untuk menjalankan sebuah hasil kerja program html yang dikerjakan.
Komponen berikutnya yang diberikan adalah komponen literasi. Komponen literasi diberikan secara khusus untuk membuat data yang dimasukkan bisa disertai dengan sumber yang akurat. Pemberian informasi sumber data member judi online sangat penting untuk diberikan, sebab dalam pembuatan html ingin mendapatkan informasi akurat yang diperoleh dari data-data member yang dikumpulkan secara resmi dan juga dikumpulkan secara akurat di dalam program html yang dijalankan. Tanpa adanya sumber informasi dan juga sumber data yang disertakan, maka html menjadi tidak memiliki fungsi untuk memberikan informasi yang sebenar-benarnya. Fungsi literasi pada xquery memberikan ruang dan juga kemudahan untuk pemrogram agar bisa memasukkan sejumlah data akurat untuk melengkapi program yang sedang dijalankan.
Pengujian komponen tersebut dilakukan secara bersamaan. Tanpa adanya pengujian yang dilakukan secara bersamaan, pihak pengguna tidak akan mengetahui apakah semua fungsi dalam komponen xquery bisa digunakan atau tidak. Proses pengujian sengaja dilakukan guna menjamin bahwa program xquery berfungsi sebagaimana mestinya. Sehingga penggunaan program xquery tidak akan mengecewakan. Terlebih dengan adanya tambahan-tambahan fungsi yang benar-benar membantu proses pemrograman html yang diperlukan. Pengujian dijalankan secara bersamaan agar diketahui secara pasti bagaimana posisi komponen-komponen dalam xquery yang menjadi unggulan. Tanpa adanya pengujian yang dilakukan secara bersamaan maka tidak akan diketahui dengan pasti apakah setiap komponen berfungsi seperti yang seharusnya. Tujuannya jelas untuk mempermudah pengguna untuk membuat program html yang sangat diperlukan dan sangat membantu.

Mengintip Populeritas dan Daya Tariknya di Dunia Slot Online
 Peran Game Provider dalam Menghadirkan Variasi Slot Online
Game provider atau penyedia perangkat lunak berperan sentral dalam mengembangkan dan menghadirkan slot online. Mereka bertanggung jawab merancang, mengembangkan dan merilis permainan slot ke kasino online. Dengan begitu banyak game provider beroperasi di pasar, mereka menjalani peran penting dalam memperkaya variasi slot online. Beberapa dari mereka yang paling terkemuka dalam industri ini termasuk:
Microgaming: Microgaming adalah salah satu game provider tertua dalam industri ini. Mereka terkenal dengan permainan slot berkualitas tinggi dan progresif yang memungkinkan pemain untuk memenangkan hadiah besar.
NetEnt: NetEnt atau Net Entertainment, dikenal dengan grafis yang luar biasa dan fitur kreatif dalam permainan mereka. Mereka merilis sejumlah besar slot terkenal dan terkemuka dalam industri ini.
Pragmatic Play: Pragmatic Play adalah game provider yang berkembang pesat dan menawarkan berbagai tema dan mekanisme permainan yang menarik. Mereka terkenal dengan game berkualitas tinggi yang sangat menghibur pemain.
Play’n GO: Play’n GO telah merilis berbagai slot yang menawarkan pembayaran besar dan banyak putaran gratis. Mereka juga dikenal dengan beragam tema, mulai dari petualangan hingga mitologi.
Yggdrasil Gaming: Yggdrasil Gaming menghadirkan slot online dengan kualitas grafis yang luar biasa dan fitur unik seperti bermain slot dengan berbagai tujuan.
Tips Memilih Slot Online yang Sesuai
Ketika memilih slot online yang sesuai, ada beberapa faktor yang perlu dipertimbangkan:
Jackpot dan Hadiah: Jika Anda mengincar kemenangan besar, perhatikan mesin slot dengan jackpot progresif. Mesin-mesin ini dapat memberikan hadiah besar yang terus bertambah seiring berjalannya waktu.
Pilih Tema yang Anda Nikmati: Slot online hadir dalam berbagai tema, mulai dari petualangan hingga fantasi. Pilih mesin dengan tema yang Anda nikmati, karena ini akan membuat pengalaman bermain lebih menyenangkan.
Reputasi Game Provider: Pastikan mesin slot berasal dari penyedia game terkemuka yang terkenal dengan kualitas permainan dan pembayaran yang adil. Penyedia game yang handal akan memastikan Anda mendapatkan pengalaman bermain yang memuaskan.
Atur Anggaran dengan Bijak: Tetapkan batasan perjudian yang sesuai dengan anggaran Anda dan patuhi batasan tersebut. Jangan tergoda untuk melampaui batasan Anda, terutama jika Anda sedang mengalami kerugian.
Slot online telah memikat pemain dari seluruh dunia dengan aksesibilitas, beragam tema dan peluang kemenangan besar. Game provider memainkan peran kunci dalam menghadirkan variasi slot yang menarik. Pemilihan slot yang tepat adalah langkah awal untuk meraih kemenangan dalam perjudian online. Dengan pemahaman tentang RTP, volatilitas dan anggaran yang bijak, pemain dapat meningkatkan pengalaman bermain mereka dan menikmati keberuntungan di dunia slot online yang seru ini.
Tidak hanya itu, para pemain juga dapat memanfaatkan permainan demo yang banyak disediakan oleh kasino online dan game provider. Fitur ini memungkinkan pemain untuk mencoba permainan tanpa harus bertaruh dengan uang sungguhan. Dengan bermain demo, Anda dapat menguji permainan, mengenal fitur-fiturnya dan menilai apakah sesuai dengan selera Anda sebelum Anda mulai bertaruh.
Terkait dengan manajemen bankroll, sangat penting untuk menetapkan anggaran perjudian yang sesuai dengan keuangan Anda. Jangan pernah menggunakan uang yang seharusnya digunakan untuk kebutuhan dasar seperti makanan, sewa atau tagihan penting lainnya. Anggaran perjudian haruslah uang yang Anda siapkan khusus untuk hiburan ini. Ini adalah cara terbaik untuk memastikan bahwa Anda tidak mengalami kerugian finansial yang signifikan dalam perjudian.
Pada akhirnya, slot online telah memikat pemain dari seluruh dunia dengan berbagai keunggulan yang mereka tawarkan. Dari aksesibilitas yang tak tertandingi hingga beragam tema dan peluang kemenangan besar, slot online memberikan pengalaman perjudian yang menarik. Dengan memilih game provider yang andal, memahami konsep RTP, volatilitas dan manajemen bankroll yang bijak, pemain dapat meningkatkan peluang mereka untuk meraih kemenangan besar dalam permainan slot online yang seru ini.
Peran Game Provider dalam Menghadirkan Variasi Slot Online
Game provider atau penyedia perangkat lunak berperan sentral dalam mengembangkan dan menghadirkan slot online. Mereka bertanggung jawab merancang, mengembangkan dan merilis permainan slot ke kasino online. Dengan begitu banyak game provider beroperasi di pasar, mereka menjalani peran penting dalam memperkaya variasi slot online. Beberapa dari mereka yang paling terkemuka dalam industri ini termasuk:
Microgaming: Microgaming adalah salah satu game provider tertua dalam industri ini. Mereka terkenal dengan permainan slot berkualitas tinggi dan progresif yang memungkinkan pemain untuk memenangkan hadiah besar.
NetEnt: NetEnt atau Net Entertainment, dikenal dengan grafis yang luar biasa dan fitur kreatif dalam permainan mereka. Mereka merilis sejumlah besar slot terkenal dan terkemuka dalam industri ini.
Pragmatic Play: Pragmatic Play adalah game provider yang berkembang pesat dan menawarkan berbagai tema dan mekanisme permainan yang menarik. Mereka terkenal dengan game berkualitas tinggi yang sangat menghibur pemain.
Play’n GO: Play’n GO telah merilis berbagai slot yang menawarkan pembayaran besar dan banyak putaran gratis. Mereka juga dikenal dengan beragam tema, mulai dari petualangan hingga mitologi.
Yggdrasil Gaming: Yggdrasil Gaming menghadirkan slot online dengan kualitas grafis yang luar biasa dan fitur unik seperti bermain slot dengan berbagai tujuan.
Tips Memilih Slot Online yang Sesuai
Ketika memilih slot online yang sesuai, ada beberapa faktor yang perlu dipertimbangkan:
Jackpot dan Hadiah: Jika Anda mengincar kemenangan besar, perhatikan mesin slot dengan jackpot progresif. Mesin-mesin ini dapat memberikan hadiah besar yang terus bertambah seiring berjalannya waktu.
Pilih Tema yang Anda Nikmati: Slot online hadir dalam berbagai tema, mulai dari petualangan hingga fantasi. Pilih mesin dengan tema yang Anda nikmati, karena ini akan membuat pengalaman bermain lebih menyenangkan.
Reputasi Game Provider: Pastikan mesin slot berasal dari penyedia game terkemuka yang terkenal dengan kualitas permainan dan pembayaran yang adil. Penyedia game yang handal akan memastikan Anda mendapatkan pengalaman bermain yang memuaskan.
Atur Anggaran dengan Bijak: Tetapkan batasan perjudian yang sesuai dengan anggaran Anda dan patuhi batasan tersebut. Jangan tergoda untuk melampaui batasan Anda, terutama jika Anda sedang mengalami kerugian.
Slot online telah memikat pemain dari seluruh dunia dengan aksesibilitas, beragam tema dan peluang kemenangan besar. Game provider memainkan peran kunci dalam menghadirkan variasi slot yang menarik. Pemilihan slot yang tepat adalah langkah awal untuk meraih kemenangan dalam perjudian online. Dengan pemahaman tentang RTP, volatilitas dan anggaran yang bijak, pemain dapat meningkatkan pengalaman bermain mereka dan menikmati keberuntungan di dunia slot online yang seru ini.
Tidak hanya itu, para pemain juga dapat memanfaatkan permainan demo yang banyak disediakan oleh kasino online dan game provider. Fitur ini memungkinkan pemain untuk mencoba permainan tanpa harus bertaruh dengan uang sungguhan. Dengan bermain demo, Anda dapat menguji permainan, mengenal fitur-fiturnya dan menilai apakah sesuai dengan selera Anda sebelum Anda mulai bertaruh.
Terkait dengan manajemen bankroll, sangat penting untuk menetapkan anggaran perjudian yang sesuai dengan keuangan Anda. Jangan pernah menggunakan uang yang seharusnya digunakan untuk kebutuhan dasar seperti makanan, sewa atau tagihan penting lainnya. Anggaran perjudian haruslah uang yang Anda siapkan khusus untuk hiburan ini. Ini adalah cara terbaik untuk memastikan bahwa Anda tidak mengalami kerugian finansial yang signifikan dalam perjudian.
Pada akhirnya, slot online telah memikat pemain dari seluruh dunia dengan berbagai keunggulan yang mereka tawarkan. Dari aksesibilitas yang tak tertandingi hingga beragam tema dan peluang kemenangan besar, slot online memberikan pengalaman perjudian yang menarik. Dengan memilih game provider yang andal, memahami konsep RTP, volatilitas dan manajemen bankroll yang bijak, pemain dapat meningkatkan peluang mereka untuk meraih kemenangan besar dalam permainan slot online yang seru ini.
Prosesor Intel Terbaik Untuk Mengelola Pekerjaan Kelas Atas
Prosesor Intel Terbaik Untuk Mengelola Pekerjaan Kelas Atas – Saat membangun atau memutakhirkan PC, pemilihan prosesor Intel merupakan keputusan integral yang dapat berdampak signifikan pada keseluruhan performa, efisiensi daya, dan umur panjang sistem.
Prosesor Intel Terbaik Untuk Mengelola Pekerjaan Kelas Atas

zorba-xquery – Sangat penting untuk meneliti dan memilih prosesor dengan kinerja terbaik yang sesuai dengan anggaran seseorang, karena prosesor tersebut akan bertindak sebagai otak dari keseluruhan operasi.
Tidak hanya harus dapat menangani semua tugas dengan mudah, tetapi juga harus hemat daya untuk mengurangi biaya energi dan memberi pengguna nilai yang lebih besar untuk uang mereka. Pada akhirnya, berinvestasi pada prosesor berkualitas akan memastikan bahwa PC Anda tetap andal dan bertenaga untuk tahun-tahun mendatang.
Intel Core i9-13900K
Intel Core i9-13900K adalah prosesor yang sangat bertenaga yang dirancang untuk memberi Anda kemampuan performa yang Anda perlukan untuk tugas intensif apa pun. Menawarkan frekuensi dasar 3,6GHz dan hingga 5,2GHz dengan Intel Turbo Boost, prosesor ini mampu memberikan kinerja yang cepat dan andal. Beli prosesor intel dengan harga terbaik di Amazon.
Intel Core i3-10100F Generasi ke-10
Prosesor Intel Core i3-10100F Generasi ke-10 adalah tambahan yang kuat untuk semua rakitan desktop. Dengan 4 core dan 8 thread dan kecepatan clock hingga 4,3GHz, Anda dapat mengalami multitasking tanpa hambatan dengan kinerja menakjubkan. Cache bawaannya membantu mengurangi latensi sehingga aplikasi Anda diluncurkan dengan cepat sekaligus meningkatkan respons sistem secara keseluruhan.
Intel Core i9-13900K
Intel Core i9-13900K adalah harga prosesor generasi ke-10 dual core yang kuat dan andal dengan harga terjangkau di Amazon . Dengan teknologi mutakhirnya, ia menawarkan kombinasi kinerja dan keterjangkauan yang tak tertandingi.
Baca Juga : Spesifikasi Penting CPU Yang Perlu Kalian Ketahui
Berkat teknologi Pemantauan Termal Komprehensif, prosesor ini menawarkan kinerja yang kuat bahkan di lingkungan daya yang paling berat sekalipun.
Prosesor Desktop i5 4590
Prosesor Intel Core i5 adalah pilihan ideal bagi para profesional yang menginginkan performa dan keandalan maksimal dari perangkat komputasi mereka. Dengan empat inti, kecepatan clock 3,3GHz, dan cache 6 MB, prosesor ini menawarkan kemampuan multi-tugas yang unggul dan kecepatan komputasi secepat kilat yang pasti akan mengimbangi tugas apa pun yang Anda lakukan.
Prosesor Intel Core i7 3rd Gen i7-3770
Prosesor Intel Core i7 3rd Gen i7-3770 adalah prosesor yang sempurna untuk kebutuhan Anda. CPU cpu prosesor i7 berkinerja tinggi ini menghadirkan prosesor quad core yang kuat dan fitur-fitur canggih seperti Intel Hyper-Threading Technology, Intel Smart Cache, dan Turbo Boost 2.0 untuk memastikan Anda mendapatkan performa maksimal dari sistem Anda. Anda akan dapat melakukan banyak tugas dengan mudah dan menikmati peningkatan efisiensi energi untuk pengalaman komputasi yang lebih tenang.
Prosesor Desktop Intel Core i7-12700K
Bersiaplah untuk melakukan tugas apa pun dengan Prosesor Desktop Intel Core i7-12700K ini. Cukup kuat untuk menangani aplikasi yang paling berat, mulai dari streaming video 4K hingga game dan pembuatan konten. Prosesor i7 yang andal menghadirkan performa luar biasa untuk semua kebutuhan komputasi Anda, memungkinkan Anda bekerja lebih cepat dan lebih efisien. Sempurna untuk para profesional yang membutuhkan kecepatan dan keandalan tinggi, Prosesor Intel Core i7 adalah tambahan yang sempurna untuk workstation Anda.
Prosesor Intel® Core™ i5-13400F
Prosesor Intel® Core™ i5 adalah pilihan sempurna untuk kebutuhan komputer Anda. Dengan cpu prosesor i5 yang mengesankan dan fitur-fitur terbaik, CPU ini akan meningkatkan kinerja komputer Anda ke tingkat yang belum pernah terjadi sebelumnya. Nikmati multitasking yang lancar dan andal dengan kecepatan kilat ideal untuk PC game, pengeditan video/foto, atau tugas berat lainnya yang mungkin Anda miliki.
Nilai terbaik untuk uang
Intel Core i7-12700K adalah pilihan sempurna bagi siapa saja yang ingin mendapatkan nilai uang yang sepadan. Dengan 12 core dan 24 thread, prosesor ini menawarkan performa luar biasa tanpa menguras kantong. Menampilkan kecepatan clock hingga 5,1GHz, dan Teknologi Intel Turbo Boost Max 3.0 memberikan peningkatan frekuensi single-core, prosesor ini memastikan kinerja yang sangat cepat apa pun tugas Anda. Dengan pengganda yang tidak terkunci, Anda dapat memeras kinerja maksimum dari sistem Anda dengan mudah.
Produk keseluruhan terbaik
Prosesor Intel® Core™ i5-13400F adalah keseluruhan produk terbaik untuk kebutuhan komputasi Anda. Dengan frekuensi 2 base clock hingga 4.3GHz, Anda mendapatkan performa maksimal dari setiap core dengan efisiensi daya hyperthreading. Ini sempurna untuk bermain game, mengedit video, atau hanya bekerja dengan beberapa aplikasi sekaligus.
Bagaimana menemukan prosesor Intel yang sempurna?
Menemukan Prosesor Intel yang sempurna untuk mengelola pekerjaan kelas atas bisa menjadi tugas yang menakutkan. Dengan begitu banyak model dan spesifikasi yang berbeda, mungkin sulit untuk memutuskan mana yang tepat. Berikut adalah beberapa tips untuk membantu Anda menemukan Prosesor Intel yang sempurna untuk kebutuhan Anda:
1. Analisis Kebutuhan Anda – Sebelum memilih prosesor Intel, penting untuk menilai dengan tepat jenis tugas yang akan Anda perlukan dan fitur mana yang paling penting untuk aplikasi khusus Anda. Pertimbangkan berapa banyak RAM, ruang penyimpanan, kecepatan clock, dan ukuran cache yang Anda perlukan, serta jenis teknologi prosesor mana (seperti Core i7) yang akan memberikan kinerja optimal untuk menjalankan program kompleks atau multitasking dengan beberapa aplikasi terbuka sekaligus.
2. Tinjauan Riset – Mempertimbangkan pengalaman dan umpan balik orang lain tentang produk tertentu dapat memberikan wawasan berharga yang mungkin tidak terlihat hanya melalui lembar spesifikasi. Baca ulasan pengguna dari sumber tepercaya seperti blog teknologi atau ulasan pelanggan Amazon sebelum membuat keputusan pembelian sehingga Anda mengetahui pro dan kontra dari berbagai model yang Anda minati.
![]()
![]()
![]()
![]()
![]()

Spesifikasi Penting CPU Yang Perlu Kalian Ketahui
Spesifikasi Penting CPU Yang Perlu Kalian Ketahui – Jika Anda berada di pasar untuk mendapatkan komputer baru, baik dengan merakitnya atau membelinya yang sudah jadi , Anda perlu memastikan bahwa Anda memilih prosesor terbaik untuk anggaran Anda. Satu hal yang membuat tugas memilih prosesor menjadi sulit adalah semua spesifikasi dan persyaratan CPU yang rumit dan membingungkan.
Spesifikasi Penting CPU Yang Perlu Kalian Ketahui

zorba-xquery – Namun, dengan sedikit pengetahuan tentang spesifikasi CPU yang paling umum, Anda akan memiliki ide bagus tentang cara memilih prosesor terbaik untuk sistem Anda .
Pada artikel ini saya akan melihat tujuh spesifikasi dan istilah CPU yang penting. Setiap istilah penting untuk dipahami dan diketahui saat memilih prosesor.
Ini bukan semua istilah yang berhubungan dengan prosesor, tetapi ini adalah istilah yang akan membantu Anda membuat keputusan sebaik mungkin. Jadi, jika Anda mencari daftar spesifikasi dan persyaratan CPU untuk membantu Anda memilih prosesor, gunakan panduan ini untuk membantu Anda menentukan pilihan.
Multi-Core
Teknologi multi-core mungkin merupakan kemajuan terbaik dalam sejarah awal prosesor.
Karena aturan praktis dengan teknologi adalah ia dimasukkan ke dalam wadah yang lebih kecil seiring berjalannya waktu, aman untuk berasumsi bahwa teknologi multi-inti akan ada di beberapa titik. Namun, itu tidak menghilangkan potensi yang dibawanya ke meja.
Apa itu teknologi multi-core? Untuk memahaminya, pertama-tama Anda harus menyadari bahwa satu prosesor mikro hanya mampu menjalankan satu tugas atau kalkulasi dalam satu waktu.
Teknologi multi-core, kemudian, adalah kemampuan untuk menempatkan beberapa mikro-prosesor (disebut sebagai inti) pada satu chip pemrosesan.
Baca Juga : Prosesor Berperingkat Teratas
Dengan demikian, CPU multi-core diperbolehkan melakukan dua hal sekaligus, daripada harus memproses satu hal dalam satu waktu. Ini secara signifikan meningkatkan kinerja prosesor.
Soket CPU
Seiring kemajuan teknologi pemrosesan, dua produsen CPU utama (Intel dan AMD) terus menerus mengeluarkan seri CPU baru.
Dengan setiap seri, kami melihat arsitektur yang lebih baru dan lebih baik yang mampu memberikan performa lebih.
Baik Intel dan AMD biasanya bekerja pada beberapa seri CPU secara bersamaan.
Misalnya, kedua pabrikan memiliki prosesor utama mereka serta prosesor berorientasi server mereka. Dan, seri CPU yang lebih baru keluar setidaknya sekali setiap beberapa tahun.
Seiring dengan seri prosesor yang berbeda, ada juga soket yang berbeda. Soket CPU adalah tempat prosesor akan dipasang di motherboard .
Beberapa seri CPU dapat menggunakan soket yang sama. Misalnya, semua prosesor AMD Ryzen menggunakan soket AMD4.
Di sisi lain, beberapa rangkaian prosesor menggunakan soket baru saat ditingkatkan ke arsitektur yang lebih baru. Misalnya, seri CPU Intel Core telah melewati banyak soket, termasuk LGA 1155, LGA 1150, LGA 1151, dan yang terbaru, LGA 1200.
Mencocokkan CPU Anda dengan motherboard yang memiliki soket yang benar sangatlah penting. Jika Anda mendapatkan motherboard yang memiliki soket yang tidak kompatibel dengan CPU Anda, maka Anda harus mengembalikan satu atau yang lain karena mereka tidak akan bekerja bersama. Jadi, hal utama yang perlu Anda pahami tentang seri CPU dan jenis soket adalah Anda harus menemukan kombinasi prosesor/motherboard yang memiliki soket yang kompatibel, tetapi juga kombinasi yang menampilkan seri dan arsitektur paling mutakhir sebagaimana adanya.
Chipset Motherboard
Sama seperti Anda harus mengetahui soket apa yang kompatibel dengan CPU yang Anda pertimbangkan, Anda juga harus mencatat berbagai chipset motherboard yang tersedia untuk soket CPU Anda.
Misalnya, prosesor Ryzen baru AMD menggunakan soket AM4. Namun, ada beberapa jenis motherboard AM4 .
Ada motherboard AM4 chipset X470 & X570, dan ada motherboard AM4 chipset B450 dan B550. Motherboard AM4 chipset “X” lebih “tugas berat”, memiliki lebih banyak fitur/port/ dan diarahkan untuk pengguna yang ingin melakukan overclocking serius pada CPU mereka.
Di sisi lain, motherboard B450 & B550 AM4 memiliki lebih sedikit fitur, tetapi harganya jauh lebih murah.
Jadi, banyak memilih chipset yang tepat untuk CPU Anda tergantung pada apa yang Anda inginkan dari sistem Anda. Misalnya, jika Anda ingin melakukan overclock, Anda harus mendapatkan CPU yang dapat di-overclock serta chipset motherboard yang juga mengakomodasi overclocking.
Tidak masuk akal untuk memasangkan CPU yang dapat di-overclock dengan chipset motherboard yang tidak memungkinkan untuk overclocking. Di sisi lain, jika Anda tidak ingin melakukan overclock, Anda bisa mendapatkan CPU yang terkunci (yang artinya tidak dapat di-overclock) dan memasangkannya dengan motherboard yang lebih terjangkau yang tidak dimaksudkan untuk overclocking.
Penting juga untuk dicatat bahwa, di sebagian besar kasus, soket CPU menentukan apakah CPU tertentu kompatibel dengan motherboard tertentu.
Namun, dalam beberapa kasus, chipset juga dapat menentukan apakah CPU tertentu kompatibel dengan motherboard tertentu.
Misalnya, dengan prosesor Intel’s Coffee Lake, meskipun mereka menggunakan soket LGA 1151, mereka tidak dengan motherboard LGA 1151 generasi lama. Prosesor Intel Coffee Lake hanya bisa digunakan pada motherboard LGA 1151 yang memiliki chipset 300-series.
Ini jarang terjadi dan salah satu dari sedikit contoh di mana serangkaian CPU tidak kompatibel dengan motherboard generasi lama pada soket yang sama. Namun, tetap penting untuk diperhatikan dan menjadi pertimbangan sebelum membeli CPU agar tidak berakhir dengan dua komponen yang tidak kompatibel satu sama lain.
Frekuensi Operasi (GHz)
Frekuensi operasi CPU, atau kecepatan jam, (yang diukur dalam hertz) merupakan konsep yang disalahpahami di antara pembuat pertama kali. Banyak pembuat pertama kali menganggap frekuensi operasi sebagai tujuan akhir dari semua penentuan nilai prosesor. Namun, ini tidak bisa jauh dari kebenaran.
Frekuensi pengoperasian prosesor adalah seberapa cepat prosesor dapat menyelesaikan satu siklus kerja. Semakin tinggi frekuensinya, semakin cepat dapat menyelesaikan satu siklus kerja.
Namun, frekuensi operasi yang lebih tinggi tidak sama dengan kinerja yang lebih baik. Ini karena CPU memiliki sejumlah instruksi per siklus clock yang dapat diproses (Intructions Per Clock, atau IPC). Misalnya, jika sebuah prosesor dapat menyelesaikan satu juta instruksi per siklus clock dan setiap siklus clock memiliki frekuensi 4,0 GHz, prosesor tersebut tetap tidak akan bekerja sebaik CPU yang beroperasi pada 3,7 GHz yang menyelesaikan dua juta instruksi per siklus clock.
Namun, jika Anda bisa mendapatkan CPU yang sama yang beroperasi pada 5,0 GHz atau lebih tinggi, maka perbedaan kinerja antara itu dan 3,7 GHz akan menjadi lebih dekat. Inilah mengapa overclocking sangat populer di kalangan penggemar kinerja.
Pada akhirnya, Anda harus mencari CPU yang menghadirkan core terbanyak, frekuensi tertinggi, dan instruksi terbanyak per siklus clock sesuai dengan anggaran Anda.
Hyperthreading (Intel) & Clustered Multithreading (AMD)
Kami telah berbicara tentang pentingnya core dan bagaimana mereka membantu multi-task CPU. Hyperthreading atau Clustered Multithreading adalah teknologi lain yang memungkinkan prosesor menjadi lebih efisien dalam tugas intensif CPU tertentu.
Hyperthreading dan Clustered Multithreading pada dasarnya adalah hal yang sama, tetapi Hyperthreading adalah istilah yang diciptakan oleh Intel dan Clustered Multithreading yang dipilih oleh AMD.
Pada dasarnya, multithreading memungkinkan CPU bekerja pada dua utas yang berbeda (urutan instruksi untuk dijalankan CPU) pada saat yang bersamaan. Tidak seperti teknologi inti, multithreading tidak memungkinkan prosesor mikro melakukan banyak hal sekaligus. Sebaliknya, ini memungkinkan prosesor bekerja pada dua hal berbeda secara bersamaan.
Untuk lebih memahami hal ini, bayangkan bekerja di jalur perakitan di pabrik mainan. Di jalur perakitan Anda, Anda perlu memasang bagian kepala ke badan figur aksi. Sabuk konveyor mengeluarkan figur aksi tanpa kepala baru setiap tiga menit dan Anda membutuhkan waktu sekitar 10 detik untuk memasang kepala.
Itu menyisakan sekitar 2 menit dan 50 detik waktu di mana Anda tidak melakukan apa-apa selain menunggu figur aksi tanpa kepala berikutnya turun. Jika pabrik mainan itu pintar, mereka akan meminta Anda mengerjakan jalur perakitan lain (yang akan ditambahkan di belakang Anda dan Anda akan berdiri di antara dua jalur perakitan).
Di jalur perakitan ini, sabuk konveyor akan menghasilkan boneka mainan setiap tiga menit dan tugas Anda adalah memasang lengan boneka tersebut. Jika jalur perakitan kedua dibuat terhuyung-huyung sehingga memproduksi boneka mainan satu menit dan 30 detik setelah setiap figur aksi tanpa kepala diproduksi, maka Anda akan dapat bekerja secara efektif di kedua jalur perakitan tanpa gangguan apa pun.
Ini, dalam arti tertentu, adalah cara kerja multithreading. Itu tidak memungkinkan CPU Anda untuk melakukan banyak hal sekaligus, tetapi itu mendelegasikan tugas lebih efisien ke titik di mana itu dapat memberikan sedikit peningkatan kinerja dalam skenario tertentu.
Multithreading semakin banyak digunakan dalam pengembangan game. Jadi, jika Anda berada di pasar untuk prosesor game baru, multithreading adalah sesuatu yang perlu dipertimbangkan dan, sebagian besar, sebagian besar prosesor tingkat konsumen akan hadir dengan beberapa tingkat kemampuan multithreading.
![]()
![]()
![]()
![]()
![]()

Prosesor Berperingkat Teratas
Prosesor Berperingkat Teratas – Apakah Anda ingin membangun PC baru dari awal atau ingin memutakhirkan sistem yang ada, CPU adalah salah satu pertimbangan terpenting. Tapi apa saja pilihan CPU terbaik saat ini di tahun 2023?
Prosesor Berperingkat Teratas

zorba-xquery.com – Untuk menjawab pertanyaan itu, tim ahli kami telah meninjau sebanyak mungkin prosesor yang bisa mereka dapatkan. Ini berkisar dari chip ramah anggaran, hingga CPU yang sangat kuat bagi mereka yang mendambakan kecepatan tercepat.
Untuk menguji setiap CPU, kami menggunakan beberapa tolok ukur sintetik, serta pengujian dalam game untuk melihat performa seperti apa yang dapat Anda harapkan. Kami memastikan untuk menjaga komponen yang konsisten untuk rig pengujian kami guna memastikan pengujian yang adil saat membandingkan kinerja prosesor desktop.
Baca Juga : Cara Memilih Prosesor Laptop Terbaik Tahun 2023
Ini tidak semua tentang kecepatan kinerja, karena kami juga memastikan untuk memeriksa fitur yang kompatibel, efisiensi daya, dan kinerja termal. Dan tentu saja, harga eceran selalu menjadi pertimbangan saat memberikan skor dan putusan akhir kepada CPU.
Tetapi sebelum Anda terburu-buru untuk membeli salah satu rekomendasi kami, berhati-hatilah, kami mengharapkan Intel untuk meluncurkan chip baru dalam waktu dekat. Secara khusus, Intel diperkirakan akan meluncurkan CPU desktop Raptor Lake Generasi ke-13 hanya dalam beberapa bulan. Dengan peringatan itu, gulir ke bawah untuk melihat pilihan CPU terbaik kami yang telah kami ulas yang saat ini dijual.
AMD Ryzen 9 7900X
AMD Ryzen 9 7900X adalah salah satu CPU terkuat yang pernah dirilis AMD, menawarkan kecepatan lebih cepat daripada chip Intel Core mana pun yang ada di pasaran saat ini. Seri Ryzen 7000 berjalan pada arsitektur Zen 4 baru AMD yang tidak hanya menghadirkan peningkatan kinerja, tetapi juga dukungan untuk DDR5 dan PCIe 5.0, memungkinkan Anda untuk meningkatkan ke RAM dan SSD terbaru dan terhebat.
AMD mengklaim Ryzen 9 7900X memiliki kecepatan clock boost maksimal 5,6GHz, yang melompati clock boost 5,2GHz Intel Core i9-12900K generasi ke-12 . Satu-satunya bagian yang tampaknya belum ditingkatkan adalah jumlah core dan thread dari gen sebelumnya – masih ada 12 core dan 24 thread.
Spesifikasi tersebut tampaknya tidak menahan kinerja multi-core. Di Cinebench R23, sebuah program yang mensimulasikan tugas-tugas berat dan intensif CPU seperti rendering, chip andalan terbaru AMD berhasil mengalahkan chip Intel Alder Lake teratas (i9-12900K) dengan selisih tertentu.
Kisah yang sama terbukti benar di tolok ukur yang lebih umum seperti dengan PCMark 10 Extended, yang mengevaluasi kinerja seluruh sistem Anda. Di sini, Ryzen 7900X mencapai skor 10.865, sedangkan i9-12900K mencatat skor 10.602, yang merupakan selisih yang wajar.
Dalam pengujian, Ryzen 9 7900X menawarkan kinerja luar biasa dan terbukti menjadi chip desktop paling bertenaga yang pernah kami uji untuk game dan beban kerja kreatif yang intens. Jika Anda menginginkan lebih banyak kecepatan, AMD juga menawarkan Ryzen 9 7950X yang mengemas lebih banyak core, sementara Intel diperkirakan akan meluncurkan chip Raptor Lake baru dalam beberapa minggu mendatang.
Intel Core i5-12600K
Lini Intel Core i5 secara konsisten menjadi chip yang cenderung kami rekomendasikan untuk sebagian besar pembeli. Ini karena mereka biasanya menawarkan nilai terbaik untuk uang, memberikan kinerja dan harga yang kompetitif. Mengikuti serangkaian tes benchmark terbaru kami, ini tetap terjadi pada Intel Core i5-12600K , yang merupakan CPU yang kami rekomendasikan untuk kebanyakan orang.
Chip ini didasarkan pada arsitektur Alder Lake yang sama dengan i9 yang lebih mahal, yang memberikannya dukungan DDR5 dan PCIe 5.0 yang terbukti di masa depan, memungkinkan Anda menikmati kinerja generasi berikutnya dan kecepatan pemuatan yang sesungguhnya.
Tapi apa yang benar-benar mengejutkan kami selama pengujian adalah seberapa bagusnya dalam bermain game. Menjalankan judul-judul besar, seperti Horizon Zero Dawn, Borderlands 3 dan Total War: Warhammer 2, i5 berhasil menawarkan kecepatan yang jauh lebih baik daripada pendahulunya.
Dalam resolusi 1080p, kami secara teratur melihat peningkatan 30fps pada i5 yang lebih lama. Namun yang lebih mengesankan, CPU juga hampir menyamai frame rate gaming i9 yang lebih mahal.
Dan sementara AMD Ryzen 5 7600X mid-range baru menawarkan harga yang sama dan kinerja yang lebih baik, masih belum bisa menandingi i5-12600K untuk kinerja multi-core. Hal ini menjadikan Intel i5 sebagai prosesor dengan nilai terbaik bagi mereka yang berencana menggunakan chip tersebut untuk bermain game dan membuat konten.
Intel Core i5-12600K juga menghadirkan salah satu konsumsi daya puncak terendah dari semua prosesor terbaru yang kami uji, artinya Anda tidak memerlukan PSU berkapasitas tinggi yang sangat mahal untuk menjalankannya dengan lancar. Akibatnya, ini adalah opsi yang sangat hemat biaya.
AMD Ryzen 5 7600X
AMD Ryzen 5 7600X menawarkan keunggulan arsitektur CPU Zen 4 dengan harga terjangkau, mendukung DDR5 dan PCIe 5.0, memungkinkan Anda memanfaatkan RAM dan SSD tercepat. Karena CPU Ryzen 7000 baru ini bekerja dengan soket baru, AM5, Anda juga perlu membeli motherboard baru. Ini akan mahal, tetapi setelah Anda melakukan pengeluaran awal, Anda akan siap untuk masa depan selama beberapa tahun.
Ryzen 5 7600X bersinar dalam performa gaming. Dalam pengujian, ini mengalahkan sepasang prosesor Intel Alder Lake yang tangguh, termasuk andalan i9-12900K. Ini semua berkat kecepatan frekuensi tinggi, mencapai puncak 5,3GHz tanpa overclocking.
Meskipun chip ini mungkin unggul dengan rasio harga-kinerja untuk bermain game, sayangnya hal yang sama tidak dapat dikatakan untuk kinerja multi-inti untuk tugas-tugas seperti rendering. Ini terbukti saat melihat hasil untuk Cinebench R23. Dalam benchmark ini, hasil 7600X menempatkannya di belakang opsi Intel 12th gen ( Intel Core i9-12900K dan Intel Core i5-12600K ).
Namun, dalam tolok ukur komputasi yang lebih umum seperti PCMark 10, 7600X menawarkan skor yang hanya dikalahkan oleh 7900X dan i9-12900K yang lebih mahal, yang menunjukkan bahwa ini sangat murah untuk komputasi dan game umum, meskipun kami menyarankan untuk mencari di tempat lain untuk yang lebih tinggi. mengakhiri pembuatan konten.
Intel Core i9-12900K
Sulit untuk merekomendasikan Intel Core i9-12900K sejak kedatangan AMD Ryzen 9 7900X. Chip AMD lebih terjangkau, sekaligus melihat performa single-core dan multi-core yang lebih baik. Tapi i9 adalah chip yang sangat kuat dengan ketahanan masa depan yang sangat baik, jadi masih merupakan pilihan yang berharga jika Anda lebih memilih untuk tetap setia pada Intel daripada beralih ke AMD.
Selama pengujian benchmark kami, kami menemukan Intel Core i9-12900K menawarkan kecepatan multi-core dan game yang sangat kompetitif. Ini memberikan peningkatan kinerja multi-core hampir 2x lipat dari pendahulunya menurut hasil Geekbench 5 dan Cinebench R23 kami. Kecepatan ini menjadikan Intel i9 sebagai rekomendasi yang mudah untuk power user dan gamer pada umumnya.
Kami juga sangat senang dengan dukungan PCIe 5.0 dan DDR5 baru dari chip yang memungkinkan 12900K bekerja dengan SSD dan RAM terbaru dan terbaik yang tersedia saat ini.
Namun selama pemeriksaan kami, kami menemukan bahwa ini masih merupakan konsumsi daya dan membutuhkan pendingin CPU yang sangat kuat untuk bekerja secara efisien.
Penarikan daya puncak 335,5W yang kami deteksi saat pembandingan juga merupakan peningkatan 100W-plus yang cukup besar pada apa yang kami ukur saat meninjau chip yang lebih umum, seperti Intel i5-12600K dan Ryzen 7 5800X . Tetapi jika Anda mendambakan salah satu chip konsumen yang paling kuat, Anda harus puas dengan penarikan daya yang tinggi.
Namun jangan lupa, Intel akan meluncurkan rangkaian Raptor Lake , yang dapat membuat Intel Core i9-12900K didiskon dalam waktu dekat.
![]()
![]()
![]()
![]()
![]()

Cara Memilih Prosesor Laptop Terbaik Tahun 2023
Cara Memilih Prosesor Laptop Terbaik Tahun 2023 – Seperti halnya dengan desktop, inti dari setiap komputer laptop adalah unit pemrosesan pusat (CPU), yang biasa disebut prosesor atau chip, yang bertanggung jawab atas hampir semua hal yang terjadi di dalamnya.
Cara Memilih Prosesor Laptop Terbaik Tahun 2023

zorba-xquery – CPU yang akan Anda temukan di laptop saat ini dibuat oleh AMD, Intel, Apple, dan Qualcomm. Pilihannya mungkin tampak tak terbatas dan namanya Bizantium. Tetapi memilih satu lebih mudah dari yang Anda kira, setelah Anda mengetahui beberapa aturan dasar CPU.
Panduan ini akan membantu Anda mendekripsi jargon teknis yang menghantui setiap lembar spesifikasi laptop dari hitungan inti hingga gigahertz dan dari TDP hingga jumlah cache untuk membantu Anda memilih yang paling cocok untuk Anda. Dengan hampir tanpa pengecualian, prosesor laptop tidak dapat diubah atau ditingkatkan nanti seperti yang dapat dilakukan beberapa desktop, jadi penting untuk membuat pilihan yang tepat sejak awal.
Beberapa Konsep Dasar CPU
CPU bertanggung jawab atas operasi logika utama di komputer. Ini memiliki andil dalam segalanya: klik mouse, kelancaran video streaming, menanggapi perintah Anda dalam game, menyandikan video rumahan keluarga Anda, dan banyak lagi. Ini bagian terpenting dari perangkat keras di dalamnya.
Baca Juga : Tips Yang Perlu Kalian Ketahui Sebelum Memilih Prosesor
Sebelum kita membahas rekomendasi CPU tertentu, mari bangun pemahaman tentang apa yang membedakan satu chip dari yang lain dengan berfokus pada ciri-ciri utama yang dimiliki oleh semua prosesor laptop.
Arsitektur Prosesor: Dasar-Dasar Silikon
Ditemukan di miliaran perangkat dari smartphone hingga superkomputer, chip ARM hanya terlihat di beberapa Chromebook dan sangat sedikit laptop Windows (berdasarkan CPU Qualcomm) hingga Apple beralih dari Intel ke prosesor M1 berdesain ARM sendiri pada akhir tahun 2020, dan sekarang chip M2-nya pada tahun 2023. Pergantian Apple adalah alasan utama mengapa chip ARM mendapat penerimaan yang lebih luas sebagai alternatif x86 untuk komputasi arus utama.
Pilihan arsitektur Anda ditentukan sebelumnya jika Anda adalah pengguna Apple karena semua laptopnya sekarang menggunakan varian chip M1 atau M2. Tetapi Microsoft Windows, ChromeOS, dan banyak sistem operasi Linux kompatibel dengan ARM dan x86. Berdasarkan ulasan kami tentang beberapa sistem Windows bertenaga Qualcomm saat ini seperti tablet Microsoft Surface Pro X dan Lenovo ThinkPad X13s Gen 1 , x86 tetap menjadi arsitektur yang kami rekomendasikan untuk Windows hingga lebih banyak aplikasi ditulis untuk berjalan secara native di ARM.
Aplikasi yang ditulis untuk x86 dapat beroperasi pada chip ARM melalui emulasi perangkat lunak, tetapi lapisan terjemahan memperlambat kinerja dibandingkan dengan kode yang ditulis untuk dijalankan pada ARM. Demikian pula, CPU ARM sesekali (terutama dari MediaTek) yang terlihat di Chromebook anggaran telah terbukti jauh lebih segar daripada prosesor Intel dan AMD di Chromebook kelas menengah dan premium.
Jumlah Inti dan Benang: Menembak pada Semua (CPU) Silinder
CPU laptop saat ini sebagian terdiri dari dua atau lebih inti fisik. Inti pada dasarnya adalah otak logis. Semuanya sama, lebih banyak inti lebih baik daripada lebih sedikit, meskipun ada batas atas berapa banyak yang dapat Anda manfaatkan dalam situasi tertentu. Analogi yang sangat disederhanakan adalah jumlah silinder dalam mesin mobil.
Untuk tugas-tugas dasar, seperti berselancar di internet, pengolah kata, media sosial, dan streaming video, prosesor dual-core adalah kebutuhan minimum saat ini. (Memang, Anda tidak dapat membeli laptop single-core hari ini, dan bahkan menjadi sulit untuk menemukan dual-core.) Multitasker akan jauh lebih baik dengan CPU enam atau delapan atau bahkan 10-core, dengan empat core sekarang ditemukan bahkan di banyak notebook anggaran.
Untuk bermain game, mengedit video, dan aplikasi intensif prosesor lainnya, delapan core atau lebih sangat ideal. CPU ini biasanya ditemukan di notebook yang lebih besar karena membutuhkan pendinginan ekstra. (Mereka juga cenderung memiliki tingkat CPU yang lebih tinggi; lebih banyak tentang stratifikasi itu sebentar lagi, ketika kita berbicara tentang spesifikasi chip Intel dan AMD.)
![]()
![]()
![]()
![]()
![]()

Tips Yang Perlu Kalian Ketahui Sebelum Memilih Prosesor
Tips Yang Perlu Kalian Ketahui Sebelum Memilih Prosesor – Saat Anda berbelanja komputer, mudah untuk merasa kewalahan dengan semua spesifikasi yang menatap balik pada Anda. Di antara berbagai ukuran layar, resolusi, dan faktor bentuk, ada banyak hal yang harus Anda perhatikan.
Tips Yang Perlu Kalian Ketahui Sebelum Memilih Prosesor

zorba-xquery – Bahkan jika Anda telah mendapatkan semua itu, Anda masih harus mencari tahu prosesor mana yang sesuai dengan kebutuhan Anda, yang dapat menjadi tugas tersendiri mengingat nomor model yang tampaknya tidak dapat dipahami yang tampaknya tidak memberi tahu Anda banyak tentang apa chip sebenarnya dimaksudkan untuk dilakukan.
Kabar baiknya adalah rangkaian angka dan huruf yang panjang itu memiliki arti, dan jauh lebih mudah untuk diurai daripada dibiarkan. Setelah Anda memahami sintaks dan mengetahui apa yang Anda butuhkan, Anda akan dapat mengintip chip apa pun dengan cepat dan mengetahui apakah itu akan berhasil.
Namun sebelum kita masuk ke barang, penting untuk mengetahui satu atau dua hal tentang cara kerja prosesor.
Apa itu CPU?
Unit Pemrosesan Pusat (juga dikenal sebagai CPU, prosesor, atau chip), bertindak sebagai pusat komando komputer Anda, yang mengambil semua tugas sistem Anda dan mendelegasikannya ke komponen perangkat keras yang berbeda. Setiap prosesor memiliki “hitungan inti”, yang memberi tahu Anda berapa banyak inti fisik hub individual yang dapat menangani tugas tertentu, sehingga komputer Anda dapat mendistribusikan beban kerjanya secara lebih merata ada di dalamnya.
Dari sana, banyak hal bisa menjadi sedikit membingungkan. Seiring dengan jumlah inti, prosesor juga memiliki apa yang disebut “jumlah utas”. Jumlah utas akan memberi tahu Anda berapa banyak “inti virtual” yang dipecah menjadi setiap inti fisik, yang memungkinkan setiap inti fisik menangani banyak tugas, bukan hanya masing-masing. Biasanya, jumlah utas dua kali jumlah inti fisik, tetapi tidak selalu.
Baca Juga : Berapa Kecepatan Prosesor Yang Baik Untuk Laptop
Akhirnya, beberapa chip (biasanya untuk laptop) mungkin berisi apa yang dikenal sebagai GPU terintegrasi, atau prosesor grafis berdaya rendah. Itu dibangun langsung ke dalam chip sehingga Anda tidak perlu mengambil ruang ekstra dengan GPU diskrit (AKA standalone).
Jadi ada titik awal yang baik. Dengan itu, berikut adalah cara memilih prosesor yang tepat dari semua produsen chip utama.
Intel
Baik itu dari lonceng “Intel Inside” lama yang masih muncul di kepala Anda dari waktu ke waktu beberapa dekade kemudian atau hanya stiker kecil yang Anda lepaskan dari sudut laptop saat pertama kali boot, Anda mungkin akrab dengan Intel . Prosesor perusahaan memberi daya pada komputer di perpustakaan lokal Anda, laptop yang dikeluarkan untuk pekerjaan Anda, dan server cloud yang tak terhitung jumlahnya.
Sekilas, rangkaian prosesor Intel yang luas tidak akan memberi tahu Anda banyak. Ada sedikit konteks untuk menyimpulkan apa perbedaan antara chip Xeon dan Atom, tetapi struktur penamaan Intel sebenarnya berguna. Setiap chip dimulai dengan nama mereknya Xeon, Pentium, Celeron, atau Core dan masing-masing memberi tahu Anda untuk jenis performa apa mereka dimaksudkan.
Di kelas atas, Anda akan menemukan chip Core, yang hadir dalam varian i3, i5, i7, dan i9. Ini biasanya ditemukan di laptop, 2-in-1, dan desktop kelas atas; varian i5 akan lebih cepat dari i3, dan seterusnya. Saat inti naik, begitu juga jumlah utas: chip i3 dengan dua atau empat inti akan datang dengan empat atau delapan utas, i5 dengan enam inti akan memiliki 12, dan i9 dengan delapan inti akan memiliki 16 utas. Ada beberapa pengecualian, tetapi ini adalah aturan umum.
Setelah pengubah “i”, Anda akan melihat serangkaian angka dan huruf yang akan memberi Anda detail yang lebih baik dari chip yang diberikan. Dua angka pertama akan memberi tahu Anda dari generasi apa chip itu berasal, jadi prosesor Core i7-1065G7 akan menjadi chip generasi ke-10, sedangkan prosesor Core i7-1165G7 akan menjadi generasi ke-11. Dua angka kedua akan memberi tahu Anda seberapa cepat setiap chip dalam barisan tertentu. Jadi, Core i7-1165G7 tidak akan secepat Core i7-1185G7, tetapi angka-angka itu tidak terlalu penting untuk kecepatan sesuai dengan garis Core yang cocok dengan chip tersebut.
Terakhir, di akhir rangkaian panjang itu, Anda memiliki sufiks lini produk, yang akan memberi tahu Anda kemampuan chip dan kasus penggunaan idealnya. Anda dapat menemukan semua sufiks di sini , tetapi ada beberapa sufiks penting yang perlu diketahui sebelum memasukkan komputer apa pun ke keranjang Anda. Jika Anda menginginkan laptop dengan grafik terintegrasi (tanpa GPU terpisah), katakanlah untuk browsing biasa atau hanya menyelesaikan pekerjaan, Anda pasti ingin mencari chip yang memiliki akhiran “G”.
Di sisi lain, laptop dengan sufiks “F” akan memerlukan grafik diskrit, yang berarti kartu grafis terpisah. Chip seri U dan Y dimaksudkan untuk konsumsi energi rendah, sehingga tidak akan sekuat beberapa chip kelas atas, dan ada beberapa lainnya yang mungkin tidak akan Anda temui untuk chip yang lebih spesifik seperti tinggi -power ponsel.
Chip desktop Intel memiliki beberapa sufiksnya sendiri, jika Anda ingin merakit PC Anda sendiri. Misalnya, chip dengan akhiran K “tidak terkunci”, yang berarti Anda dapat melakukan overclock prosesor jika beban kerja Anda sangat berat. Akhiran X juga berarti tidak terkunci, tetapi chip ini akan mengemas lebih banyak keuletan daripada varietas K. CPU dengan akhiran F memerlukan kartu grafis diskrit karena tidak memiliki grafis terintegrasi.
Hal-hal dengan garis prosesor Pentium dan Celeron level awal sedikit lebih sederhana, tetapi tidak terlalu jauh dari klasifikasi chip Core. Chip Pentium dimulai dengan awalan satu huruf, diikuti dengan nomor model empat digit, lalu akhiran. Semakin tinggi angkanya, semakin baik kinerjanya. Chip Pentium Gold akan difokuskan pada kecepatan cepat, sedangkan chip Pentium Silver akan lebih condong ke arah hemat biaya. Intel tidak memberikan banyak info tentang prosesor Celeron, tetapi hal yang sama berlaku semakin tinggi angka untuk chip tertentu, semakin cepat kecepatannya, meskipun prosesor Celeron tidak akan seefisien chip Pentium Silver.
AMD
AMD mungkin tidak ada di mana-mana seperti Intel, tetapi chipnya masih dapat ditemukan di beberapa laptop penting, jadi ada baiknya memahami cara mengklasifikasikan chipnya. Untungnya, ini sedikit lebih ramping dan lebih mudah dipahami daripada milik Intel.
Di kelas atas, Anda memiliki jajaran Ryzen , yang dapat ditemukan di desktop dan laptop. Chip Ryzen terbagi dalam lima kategori: Ryzen 3, 5, 7, 9, dan Threadripper.
Setiap chip disertai dengan nomor model—semakin tinggi semakin baik—untuk mendapatkan gambaran yang lebih baik tentang seberapa cepat setiap chip di kelas tertentu. Tanda X yang ditempelkan di akhir nomor itu berarti sedikit lebih cepat. Misalnya, jika Anda mencari chip anggaran, AMD menawarkan dua opsi: Ryzen 3 3100 dan Ryzen 3 3300X, yang terakhir lebih cepat dari keduanya.
Chip Ryzen 3 , semuanya mengemas empat inti dan hingga delapan utas, sedangkan Ryzen 5 akan memberi Anda enam inti dan 12 utas. Ryzen 7 meningkatkannya hingga delapan inti dan 16 utas, dan chip Ryzen 9 akan membawa Anda ke 16 inti dan 32 utas.
Lalu, ada Threadripper yang diberi nama tepat, yang mengemas pukulan degil dengan opsi inti mulai dari 24 hingga 128 utas, jika kasus penggunaan Anda memerlukan penggilingan yang serius.
Hampir semuanya sama dengan chip laptop AMD, tetapi ada beberapa perbedaan yang harus diperhatikan. Chip apa pun dengan sufiks G akan memiliki kartu grafis AMD Radeon terintegrasi, sedangkan sufiks GE menunjukkan bahwa keduanya berdaya rendah dan memiliki grafis terintegrasi. Jika Anda melihat H di bagian akhir, itu adalah chip ponsel berkinerja tinggi, U untuk ponsel standar, dan M menunjukkan daya rendah.
AMD juga memiliki jajaran CPU anggaran super yang disebut Athlon . Anda akan menemukan sebagian besar prosesor ini di Chromebook, dan ada tiga jenis yang berbeda: Dua “emas” dan satu “perak”. Seperti yang Anda duga, emas lebih cepat dari keduanya—prosesor emas adalah 4-inti/4-utas, dan perak adalah 2-inti/4-utas.
Apel M1
Terakhir, ada prosesor komputer rumahan pertama Apple, M1. Meskipun memiliki jumlah inti yang sama dengan banyak chip Intel dan AMD, ini dirancang berbeda karena didasarkan pada apa yang disebut arsitektur ARM. (Intel dan AMD didasarkan pada apa yang disebut arsitektur x86.) Alih-alih memiliki delapan inti yang mengelola tugas berperforma tinggi dan hemat energi, M1 mendedikasikan empat inti untuk beban kerja yang berat, sedangkan empat lainnya didedikasikan untuk tugas yang lebih ringan. Chip ini digunakan untuk smartphone dan tablet—dan tentu saja mesin lama Apple seperti asisten digital pribadi Newton dan iPod.
Jajaran MacBook dan iMac terbaru Apple semuanya berjalan pada chip M1 milik perusahaan dan cepat. Komputer-komputer ini masih dalam masa pertumbuhan, jadi tidak banyak hal spesifik yang bisa dipelajari, tetapi ada beberapa hal yang harus Anda ketahui sebelum mengambilnya. (Sebagai catatan tambahan, Microsoft Surface Pro X juga dilengkapi dengan chip ARM milik Microsoft.)
Meskipun arsitektur ARM tidak terlalu panas, lebih baik dalam menghemat masa pakai baterai, dan berjalan secepat arsitektur x86, masih ada beberapa keterbatasan. Sebagian besar aplikasi desktop dibangun untuk berjalan pada sistem x86, dan sementara perusahaan telah berupaya untuk mengizinkan chip ARM menjalankan program tersebut secara asli, tidak semua program akan bekerja dengan sempurna. Jika Anda memiliki beberapa alat utama yang Anda andalkan untuk menyelesaikan pekerjaan, Anda harus memeriksa ulang apakah alat tersebut dapat berjalan di chip baru.
Sejak debut chip M1, Apple telah menambahkan beberapa prosesor baru yang lebih kuat ke jajarannya: M1 Pro, M1 Max, dan M1 Ultra. Mereka semua membangun di atas fondasi yang diletakkan oleh M1 asli, tetapi ditingkatkan dengan lebih banyak inti untuk lebih banyak semangat (atau dalam kasus M1 Max dan M1 Ultra lebih banyak inti untuk lebih banyak semangat).
![]()
![]()
![]()
![]()
![]()

Berapa Kecepatan Prosesor Yang Baik Untuk Laptop
Berapa Kecepatan Prosesor Yang Baik Untuk Laptop – Prosesor adalah komponen penting dari sebuah laptop dan juga dikenal sebagai otak laptop. Ada banyak jenis prosesor yang tersedia di pasaran dengan kualitas dan kecepatan yang berbeda dan beragam, karena hal yang paling dituntut dalam kualitas prosesor adalah kecepatan.
Berapa Kecepatan Prosesor Yang Baik Untuk Laptop

zorba-xquery – Terlebih lagi, fitur utama prosesor adalah inti, utas desain termal, dan daya selain kecepatan. Baca artikel ini untuk lebih lanjut:
Apa itu Prosesor
Prosesor alias CPU adalah unit pemrosesan pusat komputer dan merupakan perangkat keras penting dan unit sirkuit terintegrasi. Hal ini memungkinkan komputer Anda untuk berinteraksi dengan semua aplikasi. Prosesor laptop memberikan kekuatan pemrosesan dan instruksi ke periferal untuk menjalankan berbagai tugas. Kecepatan laptop lebih tinggi jika memiliki prosesor yang lebih bertenaga dan diperbarui.
Inti Prosesor dan Kecepatan Jam
Mereka adalah dua fitur prosesor yang berbeda tetapi mereka bergantung satu sama lain. CPU memiliki inti pemrosesan dan setiap inti mampu melakukan tugasnya sendiri. Semakin banyak inti yang dimiliki CPU, semakin banyak instruksi yang dapat dilakukannya.
Setiap inti pemrosesan memiliki kecepatan jam. Kecepatan jam menunjukkan jumlah operasi yang dilakukan oleh inti pemrosesan dalam satu detik. GHz adalah satuan pengukur kecepatan jam, jika prosesor Anda memiliki kecepatan jam yang lebih tinggi dari laptop Anda akan bekerja lebih cepat.
Baca Juga : Seberapa Panas Suhu Yang Dijaga Untuk Sebuah CPU
Mengapa Kecepatan Prosesor Penting
Kecepatan prosesor penting karena meningkatkan pengalaman multi-tasking dan keseluruhan. Saat ini semua orang ingin melakukan tugas mereka dengan cepat dan menghemat waktu. Jika prosesor memiliki kecepatan yang lebih tinggi, maka Anda akan dapat melakukan tugas dengan lebih cepat dan lebih efisien.
Kecepatan Prosesor Bagus untuk Laptop Berbeda
Kecepatan prosesor yang baik bervariasi di laptop yang berbeda. Di bawah ini disebutkan rincian kecepatan yang dibutuhkan atau kecepatan hasil dari berbagai prosesor laptop:
1: Untuk Laptop Normal
Laptop normal digunakan untuk tugas-tugas yang kurang intensif sumber daya seperti mereka tidak digunakan dalam tugas-tugas berat atau bermain game sehingga tidak diperlukan prosesor kelas atas. Kecepatan prosesor untuk laptop semacam itu cukup 2,1 – 2,7 GHz. Misalnya Intel Core i3, Intel Core i5, dan AMD Ryzen 5.
2: Untuk Laptop Kantor
Laptop kantor digunakan untuk browsing serta beberapa tugas berat seperti simulasi. Untuk melakukan banyak tugas, diperlukan lebih banyak kecepatan yang mengarah ke kecepatan pemrosesan yang hebat. Kecepatan 2,10 – 4,10GHz diperlukan pada laptop tersebut. Misalnya generasi terbaru Intel Core i5, Intel Core i7, AMD Ryzen 7, dan Apple M1.
3: Untuk Laptop Gaming
Laptop gaming digunakan untuk bermain game dan melakukan tugas-tugas berat seperti video dan editing grafis. GPU yang lebih besar diperlukan untuk melakukan tugas di laptop gaming. Seiring dengan GPU, kecepatan CPU juga penting karena CPU akan mengirim data ke GPU dan menampilkannya, penundaan di antara keduanya akan memengaruhi pengalaman bermain game secara keseluruhan. Kecepatan 2,6 – 3,9GHz dan prosesor 4 hingga 8 inti diperlukan untuk tugas tersebut. Misalnya Intel Core i7, AMD Ryzen 7.
4: Untuk Laptop Berperforma Tinggi
Laptop berperforma tinggi digunakan oleh para ilmuwan dan insinyur sehingga diperlukan prosesor dengan kecepatan yang baik. Seiring dengan kecepatan prosesor, jumlah inti yang tinggi juga sangat penting. 3,50 hingga 4,2 GHz adalah kecepatan prosesor yang dibutuhkan untuk laptop ini. Misalnya Intel Core i9, AMD Ryzen 9, dan Apple M2.
Fitur Utama Lainnya untuk Prosesor yang Baik
Fitur lain yang mempengaruhi kecepatan prosesor adalah:
- Cache prosesor
- Lebar bis
Cache Prosesor
Cache prosesor menyediakan aliran CPU untuk mengambil data dengan cepat. Saat Anda melakukan banyak tugas secara terus-menerus, data disimpan dalam cache prosesor, ini mengurangi waktu dan energi untuk mengambil data dari memori. Cache prosesor juga dikenal sebagai kumpulan penyimpanan data kecil. Saat ukuran cache prosesor meningkat, prosesor bekerja dengan kecepatan yang lebih tinggi.
Lebar Bis
Lebar bus menentukan bit yang dapat ditransfer dari satu operasi ke operasi lainnya. Semakin besar bus data akan semakin baik kinerjanya dan kecepatan transfer data akan semakin besar. Jika Anda memiliki prosesor 8-bit dan prosesor Anda perlu mentransfer 16 bit data, maka akan ditransfer dalam bentuk 8 bit sekali dan 8 bit pada interval berikutnya. Jika Anda memiliki prosesor 16-bit maka data akan ditransfer sekaligus.
Kesimpulan
Prosesor rata-rata diperlukan untuk mendapatkan kecepatan yang baik dari 3,0 hingga 4GHz dan seiring dengan itu inti CPU juga penting. Bersamaan dengan itu, cache CPU dan lebar bus juga penting. Jika Anda ingin tahu lebih banyak tentang kinerja prosesor, bacalah langkah-langkah yang disebutkan di atas. Selain itu, Anda juga dapat memilih prosesor terbaik sesuai kebutuhan dan pilihan dari faktor-faktor tersebut di atas.
![]()
![]()
![]()
![]()
![]()

Seberapa Panas Suhu Yang Dijaga Untuk Sebuah CPU
Seberapa Panas Suhu Yang Dijaga Untuk Sebuah CPU – Seberapa panas terlalu panas untuk CPU? Secara umum, suhu di atas 27 derajat Celcius berbahaya bagi CPU Anda. Tapi komputer Anda pasti akan rusak jika panas mencapai 75 derajat Celcius secara kebetulan.
Seberapa Panas Suhu Yang Dijaga Untuk Sebuah CPU

zorba-xquery – Mungkin sering terjadi bahwa CPU Anda menjadi sangat panas, komputer Anda tidak dapat menerimanya dan mati di tengah apa pun yang Anda lakukan. Ini mungkin menjadi masalah besar jika Anda melakukan sesuatu yang sangat penting.
Jadi, untuk memastikan kehidupan yang sehat bagi CPU dan komputer Anda, Anda perlu memastikan bahwa prosesor tidak menerima terlalu banyak tekanan dan suhu panas terkendali.
Pada artikel ini, saya akan berbicara tentang semua yang perlu Anda ketahui tentang CPU yang menghasilkan panas dan langkah apa yang harus diambil untuk menghentikannya agar tidak terlalu panas.
Bagaimana CPU Anda Menghasilkan Panas?
Panas umumnya dihasilkan oleh listrik yang mengalir ke komponen. Pada umumnya, apapun yang ada di perangkat listrik entah itu komputer atau mesin, gerakan energi di dalamnya akan dengan mudah menciptakan perpindahan panas.
Baca Juga : Jenis Prosesor Yang Perlu Kalian Ketahui
Tetapi energi tergantung pada jenis tugas yang Anda gunakan untuk komputer. Panas dalam banyak kasus memiliki efek yang besar pada komponen dalam seperti unit pemrosesan pusat (CPU) dan Unit Pemrosesan Grafik (GPU).
Overclocking bisa menjadi salah satu dari banyak alasan CPU Anda menjadi terlalu panas. Ini terjadi ketika Anda mencoba membuat CPU Anda bekerja pada kecepatan clock yang lebih tinggi dari yang direkomendasikan pabrikan.
Dalam hal ini, Anda harus memiliki gagasan yang bagus tentang laju clocking CPU Anda. Overclocking biasanya membuat sistem operasi lebih cepat dan lebih efisien dari sebelumnya. Namun masalahnya terjadi pada voltase tinggi yang digunakan prosesor Anda. Inilah yang menyebabkan CPU Anda menghasilkan lebih banyak panas.
Selain itu, melakukan tugas berat seperti menonton DVD, sering berbagi file besar, atau memainkan game dengan grafis tinggi dapat berdampak besar pada CPU yang dalam banyak kasus menyebabkan panas berlebih.
Beberapa pemilik PC juga mencoba menyelesaikan masalah tersebut dengan menggunakan proses yang disebut underclocking. Ini mengurangi transmisi panas di dalam prosesor dengan mengganti kristal osilator.
Meskipun ini adalah proses yang efektif, ini juga dapat berdampak negatif pada efisiensi sistem. Tidak ada yang bisa bekerja lebih baik daripada mematikan komputer untuk beristirahat.
Cara Mengetahui Jika PC Anda Kepanasan:
Meskipun panas bisa berbahaya bagi CPU Anda, saya yakin komputer Anda tidak terlalu panas setiap hari. Nah, bagaimana cara mengetahui perbedaannya? Salah satu gejala utamanya adalah komputer Anda membeku secara acak saat bekerja.
Selain itu, kipas di dalam PC Anda dapat mulai mengeluarkan lebih banyak suara dari biasanya saat ada banyak tekanan ekstra pada prosesor dan motherboard. Ini terjadi karena kipas kemudian berusaha lebih keras untuk mengeluarkan udara panas dari aksesori menggunakan heatsink.
Selain itu, sebagian besar komputer dilengkapi dengan fail-safe yang mematikan komponen yang terlalu panas untuk mencegah segala jenis kerusakan permanen. Bisa juga terjadi bahwa seluruh komputer Anda mati dan lebih buruk lagi, menolak untuk memulai ulang kecuali jika sudah benar-benar dingin.
Kemudian Anda juga dapat menghindari kemungkinan PC mogok karena beberapa masalah perangkat keras.
Ada cara lain bagi Anda untuk mengetahui apakah CPU Anda terlalu panas. Untuk itu, cabut komputer dari listrik dan coba sentuh perlahan komponennya. Mereka bisa sedikit keras tetapi tidak terlalu panas sehingga Anda tidak bisa menyentuhnya.
Jika kebetulan Anda tidak dapat menyentuh bagian-bagiannya, Anda dapat yakin bahwa komputer terlalu panas.
Ketahui apakah CPU benar-benar kepanasan atau hanya panas:
Meskipun saya sudah menyebutkan cara untuk mengetahui apakah CPU Anda kepanasan, gejalanya tidak selalu muncul karena masalah kepanasan CPU Anda. Nah, tugas berat apapun pasti akan menaikkan suhu prosesor. Dalam kasus ini, komputer Anda umumnya akan menghasilkan panas tanpa menyebabkan kerusakan permanen.
Meskipun kipas Anda bekerja dengan kecepatan yang agak bising sering kali berarti terlalu panas, kipas juga mungkin rusak. Jadi, cara utama untuk mengetahui apakah CPU Anda terlalu panas atau tidak tergantung pada kinerja dan efisiensi PC Anda.
Dalam kebanyakan kasus, komputer Anda akan menjadi sangat lambat saat Anda mencoba melakukan beberapa tugas normal seperti menjalankan dua program sekaligus atau membuka beberapa tab sekaligus. Selain itu, komputer Anda sering mati dan restart tanpa bekerja sehingga menyulitkan Anda untuk melakukan apa pun. Dan jika terjadi Blue Screen of Death, Anda harus mencari solusinya secepat mungkin!
Tetapi sekali lagi, Anda dapat mengesampingkan kemungkinan adanya malware atau perangkat lunak berbahaya untuk merusak kinerja PC Anda. Jadi, lebih baik jika Anda telah mengambil langkah-langkah keamanan yang diperlukan untuk itu.
Sekarang, di sistem operasi Windows, Anda akan memiliki opsi untuk memeriksa aplikasi mana yang paling intensif menggunakan CPU dengan bantuan Resource Monitor. Anda dapat mencari aplikasi di desktop dan mendapatkan daftar aplikasi yang berjalan di latar belakang. Daftarnya bisa sangat panjang!
Kipas yang rusak adalah satu hal. Tetapi aliran udara yang buruk atau aliran udara yang tersumbat karena komponen yang salah tempat dapat menjadi penyebab besar CPU Anda kepanasan. Selain itu, Anda harus selalu menempatkan PC Anda di tempat terbuka karena ruang tertutup dapat memerangkap panas di dalamnya dan menyumbat ventilasi.
![]()
![]()
![]()
![]()
![]()

Jenis Prosesor Yang Perlu Kalian Ketahui
Jenis Prosesor Yang Perlu Kalian Ketahui – Dalam Ragam CPU, CPU diperlebar sebagai unit pemrosesan pusat yang adalah processor khusus dan sentra dalam circuit electronic yang berada dalam mekanisme.
Itu menyelesaikan perintah cocok dengan program computer. Itu membuat nalar aritmatika dasar, operasi input dan output, circuit kontrol yang ikut serta dalam program yang ditempatkan ke computer.
Jenis Prosesor Yang Perlu Kalian Ketahui

zorba-xquery – Istilah CPU dikenali sebagai processor yang terbagi dalam unit kontrol dan unit metode yang menjadi perbedaan komponen utama computer selainnya dari piranti external seperti circuit I/O dan memory khusus. CPU yang tengah trend saat ini ada berbentuk mikroprosesor yang terbagi dalam unit logam-dioksida-semikonduktor di circuit terpadu. Chip terpadu terbagi dalam CPU bersama antar-muka periferal, chip memory, mikrokontroler, dan mekanisme lain pada chip.
CPU ialah komponen krusial yang atur semua penghitungan dan perintah yang ditransfer ke elemen lain dari computer dan periferalnya. Kecepatan cepat CPU patuhi perintah dari program input. Komponen-komponennya tergantung dan kuat saat dikaitkan ke CPU . Maka perlu untuk menetapkan yang pas dan memprogramnya cocok. Pabrikasi CPU terkenal ialah AMD dan Intel. Di periode lalu, processor dipakai untuk temukan processor yang pas dan kuat.
Intel 486 bisa lebih cepat dari 386, tapi sesudah mengenalkan processor Pentium, semua processor dinamakan seperti Duron, Celeron, Pentium, dan Athlon. Bermacam ragam processor dibuat dalam arsitektur yang lain seperti 64 bit dan 32 bit dengan kecepatan maksimal dan kemampuan yang fleksibel. Ragam khusus CPU dikelompokkan sebagai processor singgel-core, dual-core, Quad-core, Hexa core, Octa-core, dan Deca core yang diterangkan berikut ini.
Baca Juga : Prosesor Mana Yang Terbaik Untuk Bermain Game
Singgel-core CPU
Ini merupakan ragam CPU paling tua yang ada dan dipakai di mayoritas computer individu dan sah. CPU singgel-core hanya bisa jalankan satu perintah pada satu waktu dan tidak efektif dalam multi-tasking. Ini mengisyaratkan jika ada pengurangan performa yang bisa diikuti bila lebih satu program digerakkan. Bila satu operasi diawali, metode ke-2 harus menanti sampai yang pertama telah usai. Akan tetapi bila disuplai dengan beberapa operasi, performa computer akan menyusut mencolok. Perform CPU utama tunggal didasari pada kecepatan jamnya dengan menimbang kemampuannya.
Dual-core CPU
Ini merupakan CPU tunggal yang terdiri antara dua utama yang tangguh dan berperan seperti CPU double yang melakukan tindakan seperti satu. Tidak seperti CPU dengan 1 utama, processor harus berpindah bolak-balik dalam array faktor saluran data apabila ataupun lebih utas digerakkan, CPU utama double mengurus multitasking secara efisien. Untuk mengoptimalkan CPU dual-core secara efisien, program yang tengah jalan dan mekanisme operasi harus mempunyai code unik yang disebutkan tehnologi multi-threading berbarengan yang tertancap didalamnya. CPU dual-core bisa lebih cepat ketimbang satu utama tapi tidak sekeras CPU quad-core
Quad-core CPU
CPU quad-core ialah mode yang ditingkatkan dari feature dan design CPU multi-core dengan 4 core pada satu CPU. Serupa dengan CPU dual-core, yang membagikan beban kerja antara core, dan quad-core memungkinkannya multitasking yang efisien. Itu tidak mengisyaratkan operasi tunggal yang 4x bisa lebih cepat ketimbang lainnya. Terkecuali bila program dan program yang digerakkan dengan code SMT akan percepat kecepatan dan jadi tak begitu menonjol. Ragam CPU semacam itu dipakai pada individu yang harus jalankan beberapa program berlainan di saat serupa dengan beberapa gamer, seri komandan paling tinggi yang dimaksimalkan dalam CPU multi-core.
Hexa Core prosesors
Ini merupakan processor multi-core yang lain ada dengan 6 core dan bisa melakukan pekerjaan yang bekerja bisa lebih cepat ketimbang processor quad-core dan dual-core. Untuk pemakai computer individu, processor Hexacore simpel dan saat ini Intel dikeluarkan dengan Inter core i7 di tahun 2010 dengan processor Hexa core. Akan tetapi di sini beberapa pemakai handphone cuma memakai processor quad-core dan dual-core. Sekarang ini, handphone ada dengan processor hexacore.
Octa-core prosesors
Dual-core dibuat dengan 2 core, empat core built-in quad-core, Hexa datang dengan 6 core di mana processor octa diperkembangkan dengan 8 core mandiri untuk melakukan pekerjaan efisien yang efektif serta bekerja bisa lebih cepat dari quad-core. processor utama. Processor octa-core yang tengah trend terdiri antara dua set processor quad-core yang membagikan kegiatan berlainan antara bermacam ragam. Kerap kali, set utama memiliki tenaga minimal dipakai untuk hasilkan pekerjaan tingkat menengah. Jika terdapat kondisi genting atau syarat apa pun itu, empat set utama cepat akan diaktifkan. Persisnya, utama okta diartikan dengan manis dengan utama code double dan menyesuaikan untuk memberi performa yang efisien.
Deca-core prosesor
Processor dengan ganda core terdiri antara dua core, 4 core ada dengan quad core, enam core ada dalam processor hexacore. Deca-core ada dengan 10 mekanisme mandiri yang dikeluarkan untuk menyelesaikan dan mengurus pekerjaan yang sukses dibanding dengan processor yang lain diperkembangkan sejauh ini. Mempunyai PC, atau piranti apa pun itu yang dibangun dengan processor deca-core merupakan opsi terbaik.
Ini bisa lebih cepat dari processor lain dan amat berhasil dalam multi-tasking. Processor deca-core tengah trend dengan feature hebatnya. Mayoritas handphone saat ini ada dengan processor utama Deca dengan mahar rendah dan tak pernah ketinggal jaman. Tentu saja, mayoritas handphone di pasar diperbaharui dengan processor anyar untuk memberi destinasi yang lebih berguna untuk semua orang.
![]()
![]()
![]()
![]()
![]()

Prosesor Mana Yang Terbaik Untuk Bermain Game
Prosesor Mana Yang Terbaik Untuk Bermain Game – Beberapa orang tampaknya menganggap semua yang Anda butuhkan untuk membuat PC gaming terbaik adalah salah satu GPU terbaik. Namun, CPU terbaik dapat membuat banyak perbedaan saat bermain game PC, terutama dengan dunia terbuka yang besar yang menjadi fitur dari banyak game PC terbaik saat ini.
Prosesor Mana Yang Terbaik Untuk Bermain Game

zorba-xquery – Karena, pada akhirnya, CPU terbaik adalah yang memberi makan kartu grafis Anda semua informasi yang diperlukan untuk menghidupkan game favorit Anda. Jadi, semakin baik CPU Anda, semakin baik pula pengalaman bermain game Anda. Selain itu, CPU yang bagus memberi manfaat lebih dari sekadar pengalaman bermain game Anda.
Sama seperti laptop gaming terbaik, CPU kelas atas juga luar biasa untuk pembuatan konten, memungkinkan tugas yang lebih rumit diselesaikan lebih cepat. Dan ketika Anda seorang profesional kreatif, waktu adalah uang.
Namun, jika Anda tidak terbiasa dengan segala hal di dunia komputasi, memilih CPU terbaik untuk kebutuhan Anda benar-benar sulit. Untungnya, saya telah menguji banyak prosesor teratas di pasaran saat ini dan dapat membuat rekomendasi untuk membantu Anda membangun PC impian Anda.
Intel Core i9-13900KS
Cores: 24 | Threads: 32 | Base clock: 3.2GHz (P-Core), 2.4GHz (E-Core) | Boost clock: 6.0 GHz (P-Core), 4.3GHz (E-core) | Cache: 36MB | TDP: 253W
Biasanya ketika saya merekomendasikan seseorang CPU terbaik untuk kebutuhan mereka, saya mencoba menghindari pembicaraan tentang sesuatu seperti Intel Core i9-13900KS. Jelas CPU termahal pada prosesor arus utama akan bagus, tetapi Core i9-13900KS sangat bagus sehingga hampir menggelikan.
Baca Juga : Arti Spesifikasi Penting Tentang Prosesor
Prosesor ini akan memiliki clock hingga 6,0 GHz hingga 2 core di bawah beban kerja yang berat, dan dalam tugas yang paling berat seperti pengeditan video 4K dan rendering aset 3D, prosesor ini akan duduk di 5,4 GHz yang cantik di semua core Performanya, sementara inti Efisien menangani semua yang mungkin mencoba mengganggu.
Tetapi kecepatan turbo maksimum 6,0 GHz plus cache 36MB membuatnya sangat menarik bagi para gamer yang menginginkan frame per detik paling banyak dan tidak ingin menahan GPU terbaik.
CPU ini akan menjadi sangat panas saat dimuat dan Anda memerlukan pendingin yang kuat untuk itu. Tetapi jika Anda menginginkan prosesor kaliber ini, Anda mungkin akan mendapatkan pendingin yang mewah.
Intel Core i5-13600K
Cores: 14 | Threads: 20 | Base clock: 3.5GHz (P-Core), 2.6GHz (E-Core) | Boost clock: 5.1 GHz (P-Core), 3.9GHz (E-core) | Cache: 24MB | TDP: 181W
Sejak Intel membuat comeback dengan prosesor Alder Lake generasi ke-12, AMD terus menjalankannya. Dan, perusahaan sekali lagi dapat mengatakan itu membuat prosesor terbaik untuk bermain game. Dengan 14 inti dan 20 utas yang luar biasa pada CPU kelas menengah, gamer akan bisa mendapatkan kinerja game yang cepat dan kinerja multi-utas yang cepat. Ini berarti Anda tidak perlu berkompromi untuk menyelesaikan pekerjaan hanya untuk memiliki chip gaming yang lebih cepat.
Saya belum membandingkan prosesor ini, tetapi melihat-lihat ulasan tentang PC Gamer dan Perangkat Keras Tom, CPU ini benar-benar melampaui kelas beratnya. Ini mengungguli AMD Ryzen 9 terbaru di banyak game, dan itu adalah prosesor yang harganya sekitar $200 lebih.
AMD Ryzen 9 7900X
Cores: 12 | Threads: 24 | Base clock: 4.7GHz | Boost clock: 5.6 GHz | Cache: 12MB | TDP: 170W
AMD Ryzen 9 7900X adalah prosesor yang saat ini saya jalankan di PC gaming pribadi saya, dan ini sangat cepat. Hal ini tidak hanya memiliki 24 utas yang masing-masing dapat meningkatkan hingga 5.6GHz, algoritme AMD memastikannya berjalan dengan kecepatan penuh lebih sering. Ini berarti bahwa suhu secara teratur akan melonjak mendekati kisaran 95°C, tetapi prosesor dirancang untuk menangani panas semacam itu. Tetap saja, saya sangat mengerti jika Anda tidak nyaman menjalankan chip yang panas di rig Anda.
Apa pun yang saya lakukan dengan prosesor ini, sepertinya tidak ada masalah. Saya telah membuka lusinan gambar di photoshop tanpa berhenti berpikir. Dan, bahkan di sebagian besar game PC dengan CPU berat, kecepatan bingkai sangat mulus. Sekarang, ini adalah CPU yang mahal, tetapi jika Anda menginginkan pengalaman kelas atas, itu sepadan dengan harga tiket masuknya. Apalagi sekarang harga sudah dipangkas untuk Black Friday.
AMD Ryzen 5 7600X
Cores: 6 | Threads: 12 | Base clock: 4.7GHz | Boost clock: 5.3 GHz | Cache: 6MB | TDP: 105W
Jika Anda mencari CPU kelas menengah tetapi tidak ingin menggunakan prosesor Intel, AMD Ryzen 5 7600X secara realistis akan memberikan pengalaman bermain game yang sangat mirip dengan chip Intel. Dan sisi positifnya: sedikit lebih murah. CPU ini mungkin terbatas pada “hanya” 6 inti – ingat ketika prosesor top-end adalah hexa-core – masing-masing inti cukup kuat untuk menghasilkan kinerja inti tunggal yang mengesankan.
Ini benar-benar memberikan pengalaman bermain yang luar biasa untuk uang, terutama jika Anda tidak berencana memasangkan CPU Anda dengan kartu grafis konyol seperti Nvidia GeForce RTX 4080. Ini adalah prosesor kelas menengah bagi siapa saja yang ingin membuat super- build PC yang seimbang dengan kartu grafis yang masuk akal seperti AMD Radeon RX 6700.
Mengapa memercayai rekomendasi prosesor saya?
Saya telah menguji dan membuat PC game selama hampir sepanjang ingatan saya. Dan pada saat itu, saya telah belajar dengan tepat apa yang harus diwaspadai terkait kebutuhan para gamer. Saya menguji dan menguji ulang prosesor beberapa kali selama masa pakainya untuk memastikan bahwa seiring waktu, setiap prosesor dalam daftar ini akan mempertahankan kinerjanya yang tinggi. Masalah apa pun yang muncul, saya pasti akan memberi tahu Anda.
![]()
![]()
![]()
![]()
![]()

Arti Spesifikasi Penting Tentang Prosesor
Arti Spesifikasi Penting Tentang Prosesor – CPU di komputer adalah otak yang melakukan semua pemrosesan. Ini adalah komponen terpenting yang menentukan kinerja komputer Anda. Itu dipasang di soket pada motherboard dan dapat dengan mudah terlihat jika Anda melihatnya.
Arti Spesifikasi Penting Tentang Prosesor

zorba-xquery – CPU juga memiliki heat sink dan kipas yang terpasang tepat di atasnya, karena mereka menghasilkan panas paling banyak dari semua komponen.
Sebagian besar cpu komputer diproduksi oleh Intel atau AMD. Keluarga prosesor Intel Core utama mencakup chip i3, i5, i7, dan i9, sedangkan AMD Ryzen menyertakan Ryzen 3/5/7/9.
Semua cpu tidak sama dalam hal kinerja dan yang paling mahal lebih bertenaga. CPU seri Intel i3/Ryzen 3 adalah entry level dan anggaran rendah sedangkan seri intel i9/ryzen 9 adalah untuk komputer workstation berkinerja tinggi.
Baca Juga : Yang Perlu Kalian Ketahui Tentang XML
Selain nama dan nomor, ada banyak fitur inti atau spesifikasi CPU yang menentukan kinerjanya. Saat memilih CPU, penting untuk memperhatikan setiap detail kecil dalam spesifikasi dan memastikan bahwa komponen lain dalam build Anda kompatibel dengannya.
Spesifikasi dan Fitur CPU
Pada artikel ini kita akan melihat beberapa fitur penting dari sebuah cpu yang mempengaruhi kinerjanya dan juga mempengaruhi pemilihan komponen lain seperti motherboard, ram, psu, pendingin, kartu grafis dll.
Hitungan Inti
Sebagian besar cpu modern memiliki banyak inti mulai dari 4,6,8 hingga 32 dan 64. Setiap inti seperti cpu di dalam cpu yang dapat menjalankan program. Memiliki banyak inti memungkinkan cpu untuk menjalankan banyak program secara bersamaan sehingga membuatnya lebih cepat.
Semakin banyak inti yang dimiliki sebuah prosesor, semakin cepat ia dapat menangani banyak proses, yang penting untuk multitasking atau untuk beban kerja berat yang dapat memanfaatkan banyak inti.
Proses seperti pengeditan video/transcoding dan aplikasi seperti game menggunakan banyak inti untuk menjalankan tugas secara paralel dan melihat peningkatan kinerja yang masif dengan lebih banyak inti. Jika Anda berencana untuk mendapatkan PC atau laptop gaming, carilah laptop dengan minimal 6 core. Untuk pekerjaan pengeditan video profesional, cpu 8 inti akan ideal sedangkan untuk membangun stasiun kerja cari cpu inti 12/16.
Untuk sebagian besar pengguna rumahan dengan persyaratan dasar seperti pengeditan dokumen, penjelajahan web, menonton video, dll., prosesor 4-inti modern sudah cukup.
Dukungan hyper-threading
Fitur Hyper-Threading saat ada pada cpu memungkinkan setiap inti pada cpu bertindak sebagai 2 inti. Dengan kata lain, cpu 4 inti dengan dukungan hyperthreading akan tampak memiliki 4 x 2 = 8 inti. Sekarang ini tidak menggandakan kinerja tetapi menambah beberapa keuntungan.
Jadi cpu 4 core dengan hyperthreading akan lebih cepat dari cpu 4 core tanpa hyperthreading.
Namun cpu 4 inti dengan hyperthreading akan lebih lambat dari cpu 8 inti tanpa hyperthreading.
Perhatikan bahwa Hyper-Threading khusus untuk Intel dan AMD yang setara adalah Simultaneous Multi-Threading (SMT) yang melakukan hal serupa. Istilah yang lebih umum adalah multi-threading.
Sementara jumlah inti mewakili jumlah inti fisik dalam CPU, jumlah utas mewakili jumlah inti virtual yang dapat disimulasikan oleh prosesor. Jadi misalnya prosesor Intel i5-10400 memiliki 6 core fisik dan 12 thread.
CPU Intel menggunakan ‘hyper-threading’ dan CPU AMD menggunakan ‘multi-threading simultan’ atau SMT untuk mencapai ini, dengan kedua teknologi pada dasarnya sama.
Seperti disebutkan sebelumnya, lebih banyak inti dan utas sama dengan efisiensi dan multitasking yang lebih baik karena prosesor lebih mampu menjalankan lebih banyak tugas secara bersamaan.
Tidak semua model cpu memiliki dukungan hyper threading. Untuk memeriksa apakah cpu memiliki dukungan threading, periksa spesifikasinya secara online. Untuk memeriksa mesin, gunakan alat seperti cpu-z dan hwinfo atau Windows Task Manager. Mereka dapat mendeteksi dan melaporkan jumlah inti dan utas cpu.
Dengan dukungan hyperthreading yang tersedia, Windows Task Manager akan menampilkan “Prosesor Logis” dua kali jumlah inti.
Perhatikan bahwa mulai generasi ke-12 intel telah mulai membuat cpu dengan arsitektur hybrid core/thread. Ada 2 jenis core, yaitu Performance core (P-core) dan Efficient Core (E-core) dan hanya performance core yang hyper-threading, sedangkan yang efisien tidak. Seperti yang Anda lihat, jumlah utas (prosesor logis) sama dengan dua kali jumlah P-core ditambah dengan jumlah E-core.
P-core juga memiliki frekuensi turbo dan base clock yang lebih tinggi dibandingkan dengan E-core.
Kecepatan jam
Prosesor digerakkan oleh jam digital yang beroperasi pada frekuensi tertentu yang diukur dalam Hz. CPU dapat melakukan beberapa tugas dengan setiap siklus clock, jadi semakin tinggi kecepatan clock, semakin banyak instruksi yang dapat dieksekusi oleh cpu.
Misalnya, prosesor jam dasar 3,1 GHz berpotensi melakukan 3,1 tugas setiap detik. Yang kami maksud dengan tugas adalah instruksi program.
Semakin tinggi kecepatan clock, semakin banyak tugas yang dapat diselesaikan prosesor, dan umumnya komputer Anda akan semakin cepat berjalan.
Untuk memeriksa frekuensi jam cpu Anda, Anda dapat menggunakan alat seperti cpu-z atau hwinfo. Berikut beberapa contohnya.
Di atas adalah cpu AMD Ryzen 7 5800H yang memiliki kecepatan clock dasar 3,2Ghz dan tingkat peningkatan 4,4Ghz.
Masalah Generasi
Penting untuk diperhatikan bahwa membandingkan kecepatan clock prosesor dari generasi atau pabrikan yang berbeda tidak selalu yang terbaik.
Misalnya, prosesor quad-core lama seperti Intel Core i5-7500 generasi ke-7 yang berjalan pada 3,4 GHz akan dikalahkan oleh Intel Core i5-10500 6-core generasi ke-10 yang berjalan pada 3,1GHz.
![]()
![]()
![]()
![]()
![]()

Yang Perlu Kalian Ketahui Tentang XML
Yang Perlu Kalian Ketahui Tentang XML – Membawa perubahan Agustus tanggung jawab pekerjaan harian saya bersamaan dengan itu datang dengan sejumlah gangguan, termasuk rentang waktu jauh dari membaca milis. Dilihat dari popularitasnya kolom seperti XML-Deviant, banyak pembaca berada dalam kesulitan yang sama.
Yang Perlu Kalian Ketahui Tentang XML

zorba-xquery – Bahkan berkualitas tinggi daftar seperti XML-Dev memerlukan investasi waktu untuk membaca, memproses, memfilter, dan mengekstrak yang berguna bit diskusi.
Karena kolom XML-Deviant telah berevolusi, itu telah bergeser dari surat murni daftar ringkasan untuk sesuatu yang lebih terfokus pada analisis dan observasi. Namun, ringkasan dasar sesekali mengisi peran penting. Mengejar hal-hal sering menimbulkan diskusi baru atau mengungkap hubungan yang menarik antara berbagai hal, jadi mari kita mulai.
Dimulai dengan diskusi khas XML-ish, Bryan Rasmussen bertanya-tanya dengan lantang tentang perbedaan antara validasi tipikal (di mana kesalahan terkecil menyebabkan lengkap kegagalan) dan pemrosesan hypermedia tipikal, katakanlah di browser (di mana kesalahan kecil diabaikan dan hidup terus berjalan, mungkin dengan indikator gambar yang rusak atau semacamnya). Meskipun tidak persis sebuah teori, Len Bullard menjawab dengan : “Jika wiper kaca depan Anda tidak berfungsi, sebaiknya mobil Anda menolak mulai?” Tampaknya masuk akal bagi saya, dalam banyak situasi. Dalam pemeriksaan QA terakhir sebagai kendaraan meninggalkan pabrik, bagaimanapun, mengembalikan mobil akan lebih baik daripada melanjutkan ke a dealer, meskipun mungkin aku hanya pilih-pilih.
Apakah itu cocok dengan apa yang terjadi dengan XHTML 2.0? Draf Kerja tidak datang keluar sebagai secepat yang diinginkan beberapa orang, meskipun mereka sedang dilihat. Milis dan individu blogger beramai-ramai membahas bagian kesesuaian dari May Working Draft, yang mengklaim ke membutuhkan sebuah xsi:schemaLocationatribut. Telusuri cukup jauh, dan Anda akan menemukannya Henri Sivonen Pesan , dijelaskan oleh Uche Ogbuji. Banyak blogger lain melompati ini, dengan nada umum, “Apa yang terjadi mereka minum ketika mereka menulis ini?” Untungnya, cerita ini memiliki akhir yang bahagia. Seperti diberitakan , ini adalah a kasus kesalahan ketik RFC 2119, HARUS yang benar-benar dimaksudkan untuk mengatakan MUNGKIN.
Baca Juga : Cara XQuery Untuk Mengambil Data Dari Layanan Web
XML yang tangkas
Jim Fuller memulai utas yang menarik, memodifikasi Manifesto asli untuk pengembangan perangkat lunak Agile agar sesuai dengan XML, poin nilai utama adalah:
- Pemrosesan XML melalui pemrosesan teks (batch, make, dll…)
- REST atas SOA (SOAP et al)
- RelaxNG melalui Skema XML
- XPath dan XSLT melalui XQuery
Melanjutkan: “Artinya, meskipun ada nilai pada item di sebelah kanan, kami menghargainya item di sebelah kiri lagi.”
balas Michael Champion (dalam pesan yang sepertinya lolos dari arsip retak):
Tidak jelas bagi saya bagaimana REST lebih gesit daripada SOA, RELAX lebih gesit daripada XSD, dll. Tentu saja pengembang XML yang gesit akan siap menggunakan RELAX NG dalam sebuah skenario untuk yang lebih tepat daripada XSD jika itu meningkatkan pelanggan kolaborasi, interaksi individu, dll.
Selain itu, Champion membuat analogi yang diterima dengan baik untuk alat perbaikan rumah, terkait pada akhir artikel ini.
Dalam beberapa jam setelah diskusi itu dan tanpa koneksi yang jelas ke Agile XML benang, Joe Fawcett tanya tentang pernyataannya bahwa “pertumbuhan layanan Web (XML) didorong oleh kebutuhan ke pisahkan konten dari presentasi.” Seseorang yang baru saja keluar dari utas sebelumnya mungkin Baca pertanyaannya, seberapa besar pengaruh kelincahan, khususnya dalam pemisahan konten dari presentasi, telah pada pengembangan layanan web? Michael Kay menjawab bahwa situasi “lebih didorong oleh kebutuhan untuk mengirimkan data XML ke aplikasi yang membawa keluar logika bisnis menggunakan data, bukan hanya melakukan presentasi.” Lainnya, termasuk Jim Fuller dan Anne Thomas Maines setuju.
“Pemisahan konten dari presentasi” adalah poin penting dalam semua jenis presentasi berurusan dengan XML, tetapi poin yang jarang dilihat dengan mata kritis. Xasima Xirohata Poin ini, mengatakan, “Sejauh yang saya tahu terlalu berbahaya untuk mengatakan pemisahan itu konten dari presentasi adalah keuntungan dari XML atau itu kebutuhan utama yang memaksa penampilan XML.” Pemisahan yang ketat sering memiliki manfaat, tetapi di lain waktu, kontennya adalah presentasi. Doug Rudder membidik poin kunci, bahwa pilihan desain “akan berdampak keluaran, mencari, mengindeks, menautkan, menggunakan kembali, dll. Dalam kebanyakan kasus, mendefinisikan konten untuk apa ini, bukan seperti apa (dalam contoh keluaran tertentu) yang penting.” Yang kembali ke Orang-orang XHTML 2.0, dan mengapa mereka sangat berhati-hati untuk memperbaikinya.
Prosesor Skema yang Meledak
Roger Costello menyarankan bahwa dalam Skema XML W3C, menggunakan maxOccurs=’unbounded’adalah tidak diinginkan, menggambar perbandingan dengan loop tak terbatas perangkat lunak. Joe English keberatan dengan ini berlatih dengan alasan bahwa memilih beberapa nilai untuk batas atas adalah sewenang-wenang: “dengan sangat beberapa pengecualian, setiap upaya untuk menyusun batas atas yang cocok untuk nilai ‘maxOccurs’ apa pun adalah terikat untuk melibatkan tebak-tebakan liar.” Sudut lain yang tidak mudah terlihat adalah bahwa algoritma umum yang digunakan untuk mengimplementasikan mesin negara dari pameran tata bahasa benar-benar miskin kinerja memori dalam menghadapi nilai maxOccurs yang besar tetapi tidak terbatas. Praktis pengalaman menunjukkan bahwa nilai di atas sekitar 1.000 mulai menimbulkan masalah.
Rick Jelliffe mendapat ke detail yang lebih teknis, berspekulasi bahwa masalahnya terletak pada tata bahasa tempat pertama, dan teknik validasi berbasis jalur itulah yang dibutuhkan selanjutnya.
Tapi Michael Kay mungkin menjelaskannya lebih jauh singkatnya: “komputer seharusnya tidak membatasi orang.”
Bisakah kita menarik hubungan apa pun di antara topik-topik ini? Pertama, banyak diskusi telah dilakukan secara bertahap naik ke tingkat yang lebih tinggi. Alih-alih mencari tahu bagaimana seharusnya Skema XML ke bekerja, orang-orang berbicara tentang strategi validasi keseluruhan, dan menuntaskan yang terbaik praktik untuk pemodelan skema. Diskusi juga tentang Agile XML menunjukkan peningkatan tingkat kesadaran diri di antara para peserta.
Agustus biasanya merupakan bulan yang lambat di milis, dengan semua liburan Euro berlangsung pada, tapi tahun ini hal-hal yang cukup hidup. Banyak diskusi segar dan informatif berlanjut pada. Tentu saja, beberapa lalu lintas adalah materi permathread, atau konten gratis. Untuk contoh, saya belum merangkum utas apa pun di “Web 2.0”; mencoba mencari tahu baik definisi untuk itu, atau menjelaskan bagaimana itu benar-benar hanya sebuah sikap, atau kontras buatan sendiri teknologi dengan orang-orang dari badan standar. Saring kebisingan dari percakapan itu dan tidak ada yang tersisa. Mungkin kesadaran itu sendiri yang penting mengambil jauh dari ringkasan diskusi.
![]()
![]()
![]()
![]()
![]()

Cara XQuery Untuk Mengambil Data Dari Layanan Web
Cara XQuery Untuk Mengambil Data Dari Layanan Web – Freeform SQL Editor dapat digunakan untuk terhubung ke layanan web pihak ketiga untuk mengambil dan melaporkan data. Namun, Anda tidak dapat menggunakan SQL untuk melaporkan layanan web. Sebagai gantinya, Anda harus menggunakan pernyataan XQuery.
Cara XQuery Untuk Mengambil Data Dari Layanan Web

zorba-xquery – XQuery adalah bahasa yang digunakan untuk mengambil data dari dokumen atau sumber data yang dapat dilihat sebagai XML. Karena Anda membuat pernyataan XQuery Anda sendiri untuk membuat laporan dengan Freeform SQL Editor, pemahaman tentang cara membuat dan menggunakan pernyataan XQuery sangatlah penting. Beberapa teknik dasar cara membuat pernyataan XQuery disediakan di bawah ini.
Anda juga dapat menggunakan Editor dan Generator XQuery (XEG) untuk menghasilkan pernyataan XQuery untuk mengkueri sumber data tertentu. Untuk langkah-langkah menggunakan XEG, lihat Membuat Pernyataan XQuery dengan XQuery Editor and Generator (XEG) .
Pernyataan XQuery, yang digunakan untuk membuat laporan di MicroStrategy untuk melaporkan data yang diambil dari layanan web, dapat dipisahkan menjadi dua bagian logis. Kedua bagian logis ini memisahkan tugas menghubungkan ke data dan mengembalikan data sehingga dapat diintegrasikan ke dalam MicroStrategy.
Baca Juga : Memahami Alat Bantu XQuery Untuk Pengarsip
Menghubungkan ke layanan web dan meminta data: Bagian pertama dari pernyataan XQuery mencakup semua definisi dan informasi yang diperlukan untuk terhubung ke layanan web.
Ini termasuk menentukan fungsi apa pun yang diperlukan untuk pernyataan XQuery, menentukan apakah akan menggunakan arsitektur REST atau protokol SOAP, membuat permintaan untuk mengambil data dari layanan web, dan seterusnya. Definisi ini disorot dengan kotak merah dengan batas tegas pada contoh pernyataan XQuery di atas.
Definisi yang diperlukan di bagian XQuery ini bergantung pada layanan web yang Anda akses dan data yang ingin Anda ambil.
Anda juga dapat menggunakan fungsi REST atau SOAP yang disediakan oleh vendor pihak ketiga lainnya seperti Zorba. Namun, MicroStrategy hanya secara aktif menguji dan mendukung fungsi MicroStrategy yang tercantum di atas.
Menerapkan keamanan: Dalam contoh pernyataan XQuery yang ditunjukkan di atas, tidak diperlukan informasi login untuk mengakses layanan web. Namun, layanan web dapat memerlukan berbagai jenis informasi login dan protokol keamanan untuk mengakses data. Untuk informasi tentang penerapan keamanan dalam pernyataan XQuery dan bagaimana hal ini dapat mengubah sintaks permintaan XQuery, lihat Menerapkan Keamanan Dalam Pernyataan XQuery .
Mengembalikan data dari layanan web agar dapat diintegrasikan ke dalam Strategi Mikro: Bagian kedua dari pernyataan XQuery menentukan cara mengembalikan data yang diambil dari layanan web agar dapat diintegrasikan ke dalam Strategi Mikro. Definisi ini disorot dengan kotak biru dengan batas putus-putus pada contoh pernyataan XQuery di atas.
Anda harus mengembalikan data dalam format tabel, itulah sebabnya pernyataan XQuery yang ditampilkan di atas dimulai dengan return
. Ini memastikan bahwa data dalam format yang dapat dipahami dalam MicroStrategy.Bagian pernyataan menentukan kolom data yang disertakan dalam tabel. Pernyataan XQuery yang ditunjukkan di atas membuat kolom untuk data kota, negara bagian, kode pos, kode area, dan zona waktu. Kolom ini menjadi atribut dan metrik laporan MicroStrategy.Data untuk kolom ini kemudian diambil di bagian pernyataan. Cara Anda membuat pernyataan XQuery untuk mengembalikan data bergantung pada struktur layanan web pihak ketiga, serta apakah Anda berencana untuk memanipulasi data menggunakan XQuery sebelum mengintegrasikannya ke dalam MicroStrategy.Menerapkan Keamanan Dalam Pernyataan XQueryLayanan web dapat memiliki berbagai persyaratan keamanan untuk mengakses data yang disediakan oleh layanan web. Dukungan MicroStrategy untuk pengambilan data dari layanan web menggunakan pernyataan XQuery mendukung sebagian besar mekanisme keamanan layanan web yang tersedia. Layanan web dapat memerlukan autentikasi HTTP, Keamanan Layanan Web, atau persyaratan keamanan nama pengguna dan kata sandi standar, yang semuanya dijelaskan di bawah ini:Otentikasi HTTP menyediakan otentikasi menggunakan salah satu dari beberapa mode otentikasi. MicroStrategy mendukung penggunaan autentikasi HTTP dasar dan intisari untuk fungsi REST, dan hanya autentikasi HTTP dasar untuk fungsi SOAP. Nama pengguna dan kata sandi yang Anda berikan sebagai bagian dari login database secara otomatis digunakan oleh MicroStrategy untuk menyelesaikan autentikasi HTTP apa pun yang diperlukan oleh layanan web.Membuat login database adalah bagian dari langkah-langkah yang diperlukan untuk membuat instans database untuk mengakses layanan web, yang dijelaskan dalam Mengizinkan Koneksi ke Layanan Web di Proyek. Login database default dikaitkan dengan layanan web yang Anda sambungkan. Anda juga dapat menggunakan pemetaan koneksi untuk menentukan login database yang digunakan untuk setiap pengguna MicroStrategy. Untuk informasi tentang mengonfigurasi pemetaan koneksi, lihat Bantuan Administrasi Sistem . Jika layanan web menggunakan autentikasi HTTP, Anda tidak dapat menggunakan autentikasi Keamanan Layanan Web, yang dijelaskan di bawah ini.Contoh yang diberikan dalam Using XQuery to Retrieve Data from a Web Service adalah contoh penggunaan fungsi REST dengan parameter URI. Dalam contoh tersebut, parameter URImenyediakan URL untuk mengakses layanan web serta menentukan data yang akan dikembalikan. Parameter ini mendukung autentikasi HTTP dasar dan intisari.
![]()
![]()
![]()
![]()
![]()
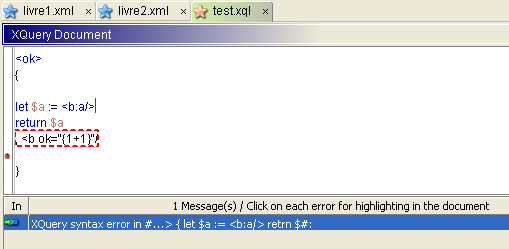
Memahami Alat Bantu XQuery Untuk Pengarsip
Memahami Alat Bantu XQuery Untuk Pengarsip – XQuery adalah bahasa scripting yang sederhana, namun kuat, yang dirancang untuk memungkinkan pengguna tanpa pelatihan pemrograman formal untuk mengekstrak, mengubah, dan memanipulasi data XML.
Memahami Alat Bantu XQuery Untuk Pengarsip

zorba-xquery – Apalagi, bahasanya ialah standard yang diterima dan referensi W3C seperti standard saudaranya, XML dan XSLT. Dengan ugkap lain, raison d’etre XQuery amat pas dengan keperluan arsiparis sekarang ini. Berikut merupakan ialah rangkuman singkat, pragmatis, XQuery untuk pengarsip yang hendak memungkinkannya pengarsip dengan pengetahuan yang tajam mengenai XML, XPath, dan EAD untuk memulai melakukan eksperimen dengan merekayasa data EAD memakai XQuery.
Pengarsip tak perlu dilego dalam XML repositori di semua negeri sudah jadi pengadopsi awalnya tehnologi semenjak 1990-an. Pada intinya semua standard data arsip sudah diperkembangkan untuk XML (EAD) atau diadaptasi untuk pemakaiannya (MARC).
Transparansi, standarisasi, elastisitas sistematis, dan keringanan pemakaian sudah menunjukkan jika XML ialah alat yang baik dan sentra untuk pengarsip era ke-21. Akan tetapi, sedangkan arsiparis sudah lama simpan alat tolong penelusuran di EAD, ada ketidaksamaan ketrampilan khusus di antara menyandikan alat tolong penelusuran dan betul-betul membuat apa dengan data itu.
Baca Juga : Yang Perlu Kalian Ketahui DataDirect XQuery
Langkah umum yang dipakai arsiparis untuk memakai data XML ialah melewati helai style XSLT, sering untuk tampilkan data dalam tabel yang panjang dan bisa digulir. Belum lama ini, ada pergerakan untuk meningkatkan mekanisme info kearsipan yang lebih hebat dan gampang dipakai.
Apalagi, arsip yang sudah banyak melakukan investasi dalam meningkatkan alat tolong penelusuran EAD akan gembira hati membuat otomatis pemakaian ulangi data ini untuk akses yang lebih gampang, kegiatan penjangkauan, dan banyak. Simpelnya, merekayasa dan memformat ulangi data XML sudah jadi ketrampilan yang berarti untuk pengarsip dan XQuery sediakan sistem yang simpel dan gampang didalami untuk melakukan.
Ini benar-benar bukan pengantar yang mendalam untuk XQuery – alhasil, pengarsip perlu cari lebih beberapa sumber daya tradisionil sebagaimana yang disiapkan pada akhir artikel ini. Akan tetapi, mengawali dengan study XQuery yang panjang dan mendalam hanya bisa tunda pengetahuan langsung dan membuat patah arang individu yang tak sabar. Pengarsip barangkali berasa lebih gampang untuk mempelajari dan melakukan eksperimen dalam bahasa itu saat sebelum cari pengetahuan yang bertambah luas. Apa yang diperlukan arsiparis ialah tutorial yang simpel dan gampang dijangkau untuk mengawalinya. Bila Anda mendapat masalah saat memakai tutorial ini, coba mencari problem Anda di Stack Overflow atau mungkin dengan mesin perayap kesukaan Anda.
XQuery dan XSLT
Saat ini, untuk pengarsip yang mempunyai pengetahuan dengan XSLT, XQuery kedengar amat serupa dengan alih bentuk helai style XML ini. XSLT dapat dipakai untuk membarui dan merekayasa data XML, dipakai secara luas jauh saat sebelum XQuery, dan mempunyai keuntungan dikompilasi oleh browser situs. Ini memiliki arti data XML bisa diolah disebelah server dengan XSLT dan browser sekarang ini tak dapat membaca XQuery tanpa add-on atau jalan keluar khusus.
Pengarsip tidak harus belajar dan menyesuaikan diri dengan piranti lunak anyar untuk coba XSLT – mereka belum lama ini melakukan eksperimen dengan alih bentuk stylesheet dengan memakai browser situs yang mereka mengenal. Ini barangkali kenapa XSLT semakin banyak dipakai dalam komune arsip. Sekolah pascasarjana biasanya mengajari XSLT dan banyak arsiparis sudah habiskan beberapa waktu untuk pelajari standard itu. Belum,
Kenapa XQuery?
Jadi kenapa memakai atau pelajari XQuery? Yang paling penting, ini lebih simpel dan tidak berbelit-belit dibanding XSLT, yang dicatat dalam XML tersebut. Ini membuat XSLT memerlukan semakin banyak watak untuk memperlihatkan sikap serupa ketimbang XQuery (saksikan tambahan untuk perbedaan). Walau ini tidak terlihat seperti keuntungan yang besar, sejatinya demikian. Skrip XQuery lebih bersih, lebih simpel, sering bisa lebih cepat untuk dicatat, serta lebih gampang untuk dipiara.
Ini membuat pemakai lebih barangkali untuk betul-betul memakai bahasa itu dan mengoptimalkan data XML mereka lebih efisien. Sebagaimana yang disebutkan oleh Steve Krug mengenai pengetesan manfaat: bila satu pekerjaan berat maka dijauhi, dan bila satu pekerjaan lebih gampang, makin besar peluangnya akan dilancarkan seringkali. Pengarsip yang menjauhi mengupdate file XSLT besar yang datang dari buku masak EAD asli tentu akan bersimpati.
Ke-2 , XQuery lebih tangguh dari XSLT. Itu bisa membuat semakin banyak peranan dan membuat beberapa tugas kompleks jadi lebih gampang. Peranan amat krusial untuk ke-2 bahasa anggaplah mereka sebagai ugkap ajaib yang sudah diprogram awalnya yang menolong pemakai untuk secara mudah memperlihatkan sikap kompleks dengan data mereka. Di XQuery, pemakai tingkat menengah bahkan juga bisa menulis peranan mereka sendiri lebih gampang ketimbang di XSLT.
Walau XSLT 3.0 sudah mengenalkan semakin banyak peranan, ini tak dapat dibanding dengan XQuery yang mempunyai 225 peranan bawaan yang bisa secara mudah mengecek apa satu komponen ada atau berisi data, mengubah string watak secara sulit, tentukan status relatif komponen, dan banyak semakin banyak alat yang memungkinkannya pemakai memetik hasil optimal dari data mereka.
Maka XQuery memungkinkannya pengarsip untuk melakukan perbuatan semakin banyak dengan data mereka, dan membuat mereka lebih barangkali untuk melakukan. Akan tetapi, keuntungan paling besar barangkali memaksakan mereka untuk menyebut file EAD sebagai data bukan sebagai tabel atau index. Tidak seperti XSLT, XQuery direncanakan untuk kueri XML ini direncanakan supaya pemakai bertanya data apa yang diinginkan dan bagaimana mereka inginkannya.
Ini bakal memaksakan arsiparis untuk menyaksikan deskripsi mereka sebagai unit info yang terpisah. Deskripsi tak hanya mempunyai komunikasi kontekstual dengan deskripsi sekelilingnya yang sampaikan posisi asli, tapi juga bermanfaat untuk kembalikan deskripsi diskrit sebagai hasil penelusuran atau membuat ulangi data untuk tampilkan info secara berlainan (dan barangkali lebih gampang dijangkau). Dengan begitu, EAD bakal menjadi penyimpan data deskripsi arsip sedangkan antar-muka tambahan atau mekanisme info menanyakan ketimbang membarui atau memformatnya kembali.![]()
![]()
![]()
![]()
![]()
Yang Perlu Kalian Ketahui DataDirect XQuery
Yang Perlu Kalian Ketahui DataDirect XQuery – DataDirect XQuery adalah komponen Java berkinerja tinggi yang mengimplementasikan XQuery dan XQuery untuk Java API, yang digunakan untuk membuat kueri XML dan data relasional secara bersamaan. Ini mendukung sebagian besar basis data relasional, berjalan pada platform Java apa pun, dan mudah disematkan ke hampir semua program Java.
Yang Perlu Kalian Ketahui DataDirect XQuery

zorba-xquery – DataDirect XQuery bekerja dengan semua Server Aplikasi J2EE, meskipun tidak diperlukan server aplikasi. Stylus Studio semakin menyederhanakan integrasi data relasional dan XML dengan menyediakan dukungan alat XQuery tingkat lanjut untuk membangun aplikasi XQuery dengan DataDirect XQuery.
Edit dan Desain Aplikasi DataDirect XQuery
Editor Stylus Studio XQuery dan mapper XQuery memberikan dukungan terintegrasi untuk mengembangkan aplikasi XQuery yang didukung oleh DataDirect XQuery. Integrasinya mulus cukup tulis kode Anda menggunakan alat XQuery produktif Stylus Studio seperti yang biasa Anda lakukan. Klik tombol properti skenario dan pilih DataDirect XQuery sebagai prosesor default Anda, seperti yang diilustrasikan di bawah ini:
Properti skenario adalah berbagai pengaturan yang Anda tentukan untuk menjelaskan konfigurasi XQuery Anda. Misalnya, Anda dapat menentukan prosesor mana yang ingin Anda gunakan, serta parameter lain seperti opsi validasi dan pemrofilan.
Baca Juga : Apa itu Kecepatan Prosesor dan Mengapa Penting?
Mengakses Data Relasional dan XML
Manfaat utama menggunakan prosesor DataDirect XQuery dibandingkan prosesor dalam memori konvensional lainnya, dan prosesor XQuery berpemilik lainnya adalah Anda dapat memperluas aplikasi XQuery untuk mengakses basis data relasional apa pun. Mengakses data relasional dan XML menggunakan XQuery dan Stylus Studio sangatlah mudah, menggunakancollection function, bagian penting dari standar XQuery untuk mengakses tabel dan sumber data lainnya.
Untuk mengonfigurasi koleksi XQuery Anda, buka jendela properti skenario XQuery dan alihkan ke tab “Umum” seperti yang diilustrasikan dalam tangkapan layar berikut. Di area “Defined Collections”, buat koleksi baru dan wizard koneksi database akan memandu Anda melalui proses pembuatan string koneksi ke sumber data Anda. Setelah selesai, Anda dapat mengakses data relasional dari dalam XQuery seolah-olah itu adalah file XML di sistem file lokal!
Memetakan Data Relasional dan XML secara visual
Setelah Anda menentukan sumber database relasional sebagai koleksi XQuery, Anda dapat menggunakannya di mapper XQuery Stylus Studio seolah-olah itu hanyalah file XML lain di Sistem file lokal. Integrasi data sangat mudah cukup muat sumber data Anda, format output target Anda, dan gambar garis dari input ke output.
Kode XQuery yang diperlukan untuk mengimplementasikan berbagai operasi pemetaan dibuat secara otomatis untuk Anda. Menggunakan kedua alat DataDirect XQuery dan XQuery Stylus Studio bersama-sama adalah cara termudah untuk membangun aplikasi yang perlu mengakses data relasional dan XML.
Pembuatan Kode Terintegrasi
Setelah Anda membangun dan menguji aplikasi integrasi data Anda menggunakan Stylus Studio, mudah untuk kemudian mengambil kode XQuery dan menyebarkannya ke lingkungan produksi Anda menggunakan Java Code Generator terintegrasi (lisensi DataDirect XQuery runtime diperlukan untuk ini). Untuk menjalankan generator kode Java, pilih “XQuery” -> “Hasilkan Kode Java”, seperti yang diilustrasikan di bawah ini.
Stylus Studio secara otomatis membuat semua file yang diperlukan untuk menjalankan XQuery Anda dari dalam aplikasi Java apa pun. Menggunakan Java IDE terintegrasi , Anda dapat mengkompilasi dan menjalankan aplikasi Java yang dihasilkan hanya dengan satu klik mouse.
Memperluas DataDirect XQuery untuk Mengakses Data Non-Relasional
Perlu mengintegrasikan data relasional, XML, dan warisan? Tidak masalah. Pengonversi XML DataDirect menyediakan cara yang andal dan berbasis standar untuk memperluas DataDirect XQuery lebih jauh, memungkinkan akses ke semua format data lama termasuk EDI , X12, EDIFACT , data biner, TSV, CSV, DBASE, dan banyak lagi! Stylus Studio menyediakan ribuan konverter bawaan untuk format file lama yang paling umum, dan menggunakan Konversi ke XML, mudah untuk menentukan secara visual definisi pengonversi XML kustom untuk format data kepemilikan apa pun.
Semua alat yang dibahas sebelumnya dalam artikel ini (pengeditan XQuery, pemetaan, pembuatan kode, dll.) berfungsi dengan sumber data lama Anda seolah-olah itu hanyalah file lain di sistem file lokal. Singkatnya, Stylus Studio, DataDirect XML Converters, dan DataDirect XQuery menyediakan alat & komponen yang diperlukan untuk mengembangkan dan menerapkan aplikasi integrasi data apa pun.
Mengapa DataDirect XQuery?
DataDirect XQuery ideal untuk aplikasi yang melakukan penerbitan XML, Penulisan Laporan XML , Integrasi Data , pemrosesan XML untuk SOAP dan Layanan Web , atau situs Web Dinamis . Menggunakan DataDirect XQuery secara signifikan menyederhanakan pengembangan aplikasi dengan mengurangi jumlah pengembang kode yang menulis dan memelihara untuk menggunakan XML dan data relasional secara bersamaan. Untuk informasi selengkapnya tentang Stylus Studio dan DataDirect XQuery, tonton demonstrasi video informatif ini .
![]()
![]()
![]()
![]()
![]()

Apa itu Kecepatan Prosesor dan Mengapa Penting?
Apa itu Kecepatan Prosesor dan Mengapa Penting? – Teknologi telah maju, dan produktivitas diharapkan meningkat dengan peningkatan kecepatan internet dan spesifikasi perangkat. Orang terbiasa mendapatkan hasil secara instan dengan mengklik tombol.
Apa itu Kecepatan Prosesor dan Mengapa Penting?

zorba-xquery – Jadi, inilah mengapa kecepatan prosesor penting dalam perangkat ini karena mereka harus mengikuti semua kemajuan ini untuk memberikan hasil yang cepat dan berkinerja tinggi.
Prosesor dianggap sebagai “otak” dari perangkat ini, jadi penting untuk bekerja dengan baik untuk memastikan umur panjang dan fungsionalitas perangkat Anda. Artikel ini akan menjelaskan apa yang dilakukan oleh prosesor yang lebih cepat , dan cara menerapkannya saat membeli perangkat baru.
Apa itu prosesor PC dan apa fungsinya?
Unit pemrosesan pusat perangkat Anda, lebih dikenal sebagai CPU, adalah komponen perangkat keras utama yang memungkinkan perangkat Anda berinteraksi dengan semua program dan aplikasi di perangkat untuk membuatnya berfungsi.
Ini dilakukan dengan menginterpretasikan perintah program dan mengeksekusi keluaran yang muncul di antarmuka perangkat. Kecepatan terjadinya seluruh proses ini pasti dapat memengaruhi pengalaman penggunaan Anda, yang dengan jelas menunjukkan pentingnya kecepatan prosesor .
Baca Juga : Apakah CPU Dan GPU Sekarang Menjadi Terlalu Boros Energi?
Prosesor vs. kecepatan
Dua komponen CPU utama yang memengaruhi kecepatan ini adalah inti prosesor dan kecepatan jam. Untuk memahami apa itu kecepatan prosesor pada komputer , dan seberapa penting kecepatan prosesor pada laptop /desktop, penting untuk memahami kedua komponen ini terlebih dahulu.
Inti prosesor adalah unit pemrosesan mini di dalam CPU, seperti unit saraf di dalam otak. Ketika inti prosesor menerima perintah dari tugas komputasi, dengan cepat memproses informasi yang diterima dan menyimpannya dalam memori akses acak (RAM). Banyak perangkat memiliki banyak inti prosesor yang memungkinkan Anda melakukan banyak tugas secara bersamaan. Di zaman di mana multi-tasking pada perangkat Anda diberikan, penting untuk memiliki prosesor yang dapat mengimbangi. Perangkat dengan banyak inti prosesor pasti akan meningkatkan produktivitas dan output perangkat.
Kecepatan jam prosesor perangkat menentukan seberapa cepat CPU dapat menerima dan menginterpretasikan instruksi dari perintah program komputer. Semakin cepat kecepatan jam, semakin cepat tugas diselesaikan. Kecepatan jam diukur dalam gigahertz (GHz). Semakin tinggi GHz, semakin cepat keluarannya.
Meskipun kedua komponen ini sangat berbeda, keduanya bekerja menuju tujuan akhir yang sama. Mereka bekerja bersama untuk memastikan bahwa perangkat bekerja pada kecepatan terbaiknya. Memiliki kecepatan clock tinggi dengan inti tunggal atau ganda berarti perangkat Anda akan dapat memuat dan berinteraksi dengan satu aplikasi dengan cepat, sementara memiliki banyak inti prosesor dengan kecepatan clock lebih sedikit akan memungkinkan Anda melakukan banyak tugas tetapi perangkat akan berjalan lebih lambat.
Jenis prosesor
1. Prosesor game – prosesor ini menggunakan 1-4 inti, dan banyak gamer profesional menggunakan perangkat yang menggunakan lebih banyak prosesor. Game memanfaatkan teknologi multi-core ini dengan grafis, audio, dan pengalaman bermain yang disempurnakan. Kecepatan clock yang baik untuk komputer game umumnya antara 3,5 GHz hingga 4,0 GHz.
2. Prosesor yang digunakan sehari -hari – Biasanya datang dalam dual core, memungkinkan pengguna untuk melakukan banyak tugas dan mengurangi waktu tunggu aplikasi untuk memuat dan berfungsi.
3. Prosesor komputasi berkinerja tinggi – Prosesor ini biasanya digunakan pada perangkat yang terlibat dalam program yang sangat kompleks dan padat data. Penggunaannya membutuhkan banyak program untuk dijalankan secara bersamaan, dengan pertukaran data yang terjadi terus-menerus. Penggunaan semacam ini membutuhkan prosesor canggih dengan kecepatan clock tinggi.
Bagaimana memilih prosesor perangkat terbaik
Berapa kecepatan prosesor komputer yang baik untuk penggunaan Anda? Semua orang tahu untuk apa mereka menggunakan perangkat mereka, dan apa yang mereka butuhkan dalam hal program dan pengalaman. Memahami kebiasaan penggunaan merupakan faktor kunci dalam menentukan perangkat yang paling cocok untuk Anda. Bagi mereka yang menggunakan banyak aplikasi sekaligus, atau memainkan game yang kompleks, perangkat prosesor 4 atau 8 inti cocok.
Pengguna dasar akan menemukan bahwa prosesor dual-core sudah cukup untuk kebutuhan mereka. Mereka yang perlu melakukan tugas seperti mengedit video atau bermain game profesional ingin melihat perangkat dengan kecepatan clock lebih tinggi hingga 4,0GHz, sementara pengguna dasar tidak memerlukan kecepatan clock yang sangat canggih. Oleh karena itu, penting untuk menentukan gaya penggunaan Anda sebelum melihat inti prosesor atau kecepatan jam, karena tidak semua orang membutuhkan tingkat kecepatan atau inti pemrosesan yang sama.
![]()
![]()
![]()
![]()
![]()

Apakah CPU Dan GPU Sekarang Menjadi Terlalu Boros Energi?
Apakah CPU Dan GPU Sekarang Menjadi Terlalu Boros Energi? – Setiap beberapa tahun, prosesor komputer generasi baru diluncurkan. Untuk waktu yang lama, CPU tampaknya bertahan pada tingkat daya yang sama, sedangkan GPU hanya meningkat dalam jumlah yang relatif kecil. Namun belakangan ini tampaknya model kelas atas dari semua vendor merilis model yang membutuhkan daya dalam jumlah besar.
Apakah CPU Dan GPU Sekarang Menjadi Terlalu Boros Energi?

zorba-xquery – Apakah 250W untuk CPU dan 450W untuk GPU terlalu tinggi? Apakah produsen bahkan peduli tentang ini? Dalam artikel ini, kita akan mengupas heatsink untuk melihat kebenaran di balik figur daya dan melihat dengan tepat apa yang terjadi.
Mengapa chip membutuhkan daya dan menjadi panas
CPU dan GPU diklasifikasikan sebagai sirkuit Integrasi Skala Besar (VLSI) kumpulan besar transistor, resistor, dan komponen elektronik lainnya, semuanya berukuran mikroskopis. Chip semacam itu membutuhkan listrik untuk mengalir melaluinya untuk melakukan tugas yang dirancang untuk dilakukan. Unit logika aritmatika melakukan matematika dengan mengganti sejumlah transistor, untuk mengubah berbagai voltase di tempat lain di sirkuit.
Baca Juga : Rumor Intel Dan AMD Menunjukkan Rencana CPU Yang Mengecewakan Untuk Tahun 2023
Prosesor modern menggunakan jenis transistor yang disebut FinFET (Fin Field-Effect Transistor). Pikirkan ini seperti jembatan antara dua pulau, di mana penerapan voltase kecil menurunkan jalan, memungkinkan arus mengalir dari satu tempat ke tempat lain.
Jelas, ini melibatkan arus yang melewati pulau-pulau dan melalui jembatan, maka kebutuhan tenaga listrik tanpanya, chip tidak akan melakukan apa-apa. Tapi mengapa mereka kemudian menjadi panas? Sayangnya, semua komponen tersebut memiliki hambatan terhadap aliran listrik ini. Jumlah sebenarnya sangat kecil, tetapi mengingat jumlah transistor dalam CPU dan GPU mencapai miliaran, efek kumulatifnya sangat terasa.
Sebuah CPU tipikal mungkin hanya memiliki resistansi internal total selusin atau lebih miliohm, tetapi begitu memiliki 80A atau lebih arus yang mengalir melaluinya, energi yang hilang karena resistansi akan lebih dari 90 joule setiap detik (atau watt, W).
Energi itu ditransfer ke bahan yang membentuk keseluruhan chip, itulah sebabnya setiap prosesor menjadi panas saat sedang bekerja. Keripik besar perlu didinginkan secara aktif untuk mencegah suhunya naik terlalu tinggi, jadi semua panas itu perlu dibuang ke tempat lain.
Ada faktor lain yang memengaruhi jumlah panas yang hilang, seperti kebocoran arus, tetapi jika prosesor ‘kehilangan’ energi (dalam bentuk panas), prosesor harus terus ‘mengkonsumsinya’, agar tetap berfungsi. Dengan kata lain, jumlah panas yang hilang hampir sama dengan peringkat daya chip. Jadi mari kita mulai dengan melihat unit pemrosesan pusat dan melihat bagaimana kebutuhan daya mereka telah berubah selama bertahun-tahun.
Kebenaran tersembunyi di balik angka kekuatan CPU
Selama bertahun-tahun, vendor CPU telah menyatakan konsumsi daya prosesor mereka melalui angka sederhana: Thermal Design Power atau TDP. Angka ini telah melalui berbagai definisi, sayangnya, karena desain chip telah berevolusi.
Definisi Intel saat ini adalah:
“Pengurangan daya rata-rata waktu yang divalidasi oleh prosesor agar tidak melebihi selama pembuatan saat menjalankan beban kerja kompleksitas tinggi yang ditentukan Intel pada Frekuensi Dasar dan pada suhu sambungan maksimum”
Dengan kata lain, jika CPU Intel Anda memiliki frekuensi dasar 3,4 GHz dan suhu maksimum 95 °C (203 °F), maka peringkat dayanya akan sama dengan TDP selama chip beroperasi pada batas tersebut. Jadi mari kita lihat beberapa contoh CPU selama 17 tahun terakhir. Kami telah mengambil model desktop yang paling haus daya yang dirilis setiap tahun, selama periode itu, mengabaikan model yang ditujukan untuk workstation dan sejenisnya.
Terlepas dari beberapa kasus yang terisolasi, seperti AMD FX-9590 dari tahun 2013 (dengan TDP 220W!), CPU tampaknya sangat konsisten dalam kebutuhan dayanya. Sekilas, sepertinya tidak ada tanda-tanda mereka semakin rakus akan kekuasaan, yang jelas merupakan hal yang baik. Kemajuan yang dibuat dalam pembuatan semikonduktor, serta desain sirkuit terintegrasi yang optimal, harus menjadi alasannya.
Satu-satunya masalah dengan itu adalah hampir setiap CPU di pasaran dapat berjalan dengan kecepatan yang jauh lebih tinggi daripada frekuensi dasarnya. FX-9590 yang disebutkan di atas memiliki frekuensi dasar 4,7 GHz, tetapi dapat meningkatkan kecepatan clock hingga 5,0 GHz. Jadi apa yang terjadi kemudian?
Anda mungkin berpikir itu jawaban sederhana: itu akan menghilangkan lebih banyak daya, menarik jumlah arus yang lebih tinggi dari motherboard. Sayangnya, itu tidak selalu terjadi, karena tergantung pada pengaturan apa yang telah diaktifkan di BIOS motherboard. Baik Intel maupun AMD memiliki sejumlah opsi, semuanya dapat diaktifkan atau dinonaktifkan (tergantung apakah ada opsi untuk melakukannya, di BIOS) yang memungkinkan CPU mengatur daya dan frekuensinya sendiri.
Tetap berpegang pada Intel sejenak, sistem utama untuk melakukan ini disebut Teknologi Turbo Boost. Mengesampingkan nama gaya 1980-an, yang dilakukan adalah secara aktif mengontrol berapa banyak daya yang dapat dihamburkan CPU untuk beban tertentu, selama jangka waktu tertentu. CPU Intel biasanya memiliki dua batasan daya seperti itu, PL1 (a.k.a. TDP) dan PL2, meskipun tersedia lebih banyak…
Perhatikan bagaimana kurva daya oranye dapat melonjak ke level yang jauh lebih tinggi dari PL1 dan naik ke PL2 untuk jangka waktu tertentu. Di sini, CPU beroperasi di atas frekuensi dasarnya, tetapi belum tentu pada kecepatan clock maksimumnya.
Karena Intel menonaktifkan PL3 dan PL4 secara default, kita dapat menganggap PL2 sebagai konsumsi daya maksimum CPU yang sebenarnya, mungkin hanya untuk beberapa detik (atau tergantung pada pengaturan BIOS, ini bisa berjalan seperti itu selamanya), tetapi itu masih watt tertinggi mungkin.
Jadi berapa PL2 lebih tinggi dari PL1? Nilai ini berfluktuasi dengan setiap model prosesor baru, tetapi mari kita periksa beberapa tahun terakhir dari bagan TDP kami di atas. Tujuh tahun yang lalu, dengan Core i7-8700K, hanya ada perbedaan 30W antara PL1 dan PL2, tetapi sekarang lebih dari 100W secara efektif menggandakan kebutuhan daya, dalam beberapa kasus. AMD tidak menggunakan label dan definisi yang sama dengan Intel, tetapi CPU mereka juga dapat menghabiskan lebih banyak daya daripada batas TDP.
Batas atas diberikan sebagai Pelacakan Daya Paket (PPT) daya maksimum yang dapat dihamburkan CPU di bawah beban yang diberikan. Untuk semua prosesor desktop Ryzen dengan TDP 95W atau lebih, PPT sama dengan 1,34 x TDP. Jadi satu hal yang jelas sekarang: CPU kelas atas pasti telah meningkat dalam kebutuhan daya maksimum absolutnya selama beberapa tahun terakhir, meskipun TDP relatif statis.
Namun, vendor motherboard memperburuk keadaan, dengan mengesampingkan batas daya dan batasan waktu standar Intel, dan menetapkan nilai mereka sendiri di BIOS. Dengan kata lain, CPU di satu motherboard mungkin maksimal 120W, tetapi mencapai 200W di motherboard lain. Tetapi kita harus mengambil stok pada titik ini, karena semua angka yang ditampilkan sejauh ini adalah untuk model top-end yang memiliki kecepatan clock tertinggi dan jumlah inti terbanyak.
Untungnya, CPU kelas menengah dan anggaran tidak banyak berubah, hanya karena mereka selalu memiliki inti yang jauh lebih sedikit daripada penghenti acara. Turun ke ujung bawah pasar CPU desktop, Intel Core i3-12100F yang populer memiliki TDP 58W (dan PL2 89W), sedangkan AMD Ryzen 3 4100 diberi peringkat TDP 65W hampir sama dengan lini produk tersebut selalu begitu. Namun, AMD Ryzen 7600X kelas menengah terbaru memiliki TDP 105W, empat puluh lebih banyak dari pendahulunya, 5600X. Dan Intel Core i5-12600K memiliki TDP chip kelas atas: 125W.
Semua ini menunjukkan bahwa ada konsumsi daya yang jelas merayap, sebagian besar menuju model kelas atas tetapi tidak secara eksklusif. Jika Anda menginginkan CPU yang memiliki jumlah inti terbanyak dan kecepatan clock tertinggi, maka ada permintaan energi yang signifikan yang menyertainya. Sayangnya, orang-orang yang ingin meningkatkan ke produk kelas menengah terbaru mungkin juga harus menerima kenaikan energi yang signifikan.
Masuki kuda nil lapar kekuasaan: GPU
Di mana CPU cukup lembut dalam hal daya, bahkan memperhitungkan kenaikan baru-baru ini dalam batas maksimum, ada satu chip di PC desktop yang semakin besar dan lapar di setiap generasi baru. Chip pemrosesan grafis (GPU) sejauh ini merupakan perangkat semikonduktor terbesar dan terkompleks yang pernah dimiliki kebanyakan orang, dalam hal jumlah transistor, ukuran cetakan, dan kemampuan pemrosesan.
Tingkat ketelitian grafis dalam game saat ini berada pada skala yang hanya dapat diimpikan 17 tahun yang lalu, tetapi biaya daya untuk semua poligon, tekstur, dan piksel tersebut membuat CPU terlihat ringan, jika dibandingkan. Kami telah melakukan hal yang sama dalam bagan ini, seperti yang kami lakukan untuk CPU yang mengambil kartu grafis tingkat konsumen yang paling menuntut daya dari vendor teratas, untuk setiap tahun.
Dan seperti yang ditunjukkan grafik, ada sedikit tanda bahwa tren kartu grafis paling kuat yang membutuhkan jumlah daya yang lebih tinggi akan berkurang sama sekali, karena tren untuk kedua vendor jelas tidak menurun, meskipun korelasinya tidak terlalu kuat.
Dengan peluncuran GeForce RTX 4090 oleh Nvidia, dengan chip dengan 76 miliar transistor dan TDP 450W, standar tersebut telah meningkat secara signifikan. Jadi apakah vendor GPU benar-benar tidak peduli dengan kebutuhan daya sama sekali?
Grafik di atas menunjukkan bagaimana chip yang sama seperti sebelumnya telah diskalakan dalam hal jumlah transistor yang dikemas ke dalam setiap milimeter persegi cetakan, terhadap TDP kartu grafis. Skala kepadatan mati adalah logaritmik karena telah terjadi lompatan besar dalam kepadatan dalam beberapa tahun terakhir skala linier akan membuat hampir semua titik data dikemas ke dalam wilayah kecil.
Kita dapat melihat bahwa karena GPU telah mengemas lebih banyak sakelar berukuran nano ke dalam sirkuitnya, kebutuhan daya terus meningkat tetapi tidak secara konstan (ya, garis AMD terlihat lurus, tetapi ingat skala log). Kecenderungan non-linier sama-sama meningkat tetapi tingkat kenaikannya sendiri mengalami penurunan setiap tahunnya. Pola antara kepadatan dan TDP ini tergantung pada vendor yang merilis chip baru yang diproduksi pada node proses yang lebih baik.
Ini adalah nama yang diberikan untuk metode fabrikasi yang digunakan oleh pengecoran semikonduktor untuk membuat chip. Setiap node baru memberikan berbagai manfaat dibandingkan pendahulunya: densitas lebih tinggi, daya lebih rendah, kinerja lebih baik, dan sebagainya.
Tidak semua peningkatan ini dapat diterapkan pada saat yang sama, tetapi dalam kasus GPU, ini memungkinkan vendor untuk membuat prosesor yang sangat besar, dengan tingkat penguraian angka yang luar biasa, untuk kebutuhan daya yang wajar.
Misalnya, jika Navi 21 dibuat menggunakan node yang sama dengan yang digunakan untuk R520, daya yang dibutuhkan akan mengalir dengan baik ke wilayah kW. Jadi sementara tingkat energi cukup tinggi saat ini, bisa jadi jauh lebih buruk. Dan manfaat dari node proses baru dan desain GPU lebih dari sekadar menjaga tingkat daya tetap rendah. Kemampuan komputasi, per unit daya, dari semua GPU kelas atas telah mengalami peningkatan yang hampir konstan, pada tingkat yang mencengangkan, sejak model shader terpadu pertama kali muncul pada tahun 2006.
Jika seseorang mengambil angka di atas, peningkatan rata-rata TDP sejak 2006 adalah 102%, sedangkan peningkatan kinerja-per-watt FP32 adalah 5.700% yang mencengangkan. Meskipun throughput pemrosesan FP32 bukanlah kualitas kartu grafis yang menentukan, ini adalah salah satu kemampuan paling penting untuk bermain game dan grafis 3D. Kami hanya memiliki game dengan grafik dan fitur luar biasa hari ini, karena GPU terbaik menjadi lebih besar dan lebih kompleks.
Tetapi meskipun prosesor grafis lebih baik dari sebelumnya, dan tingkat dayanya sebenarnya tidak seburuk yang seharusnya, tingkat konsumsi energinya masih meningkat. Bahkan GPU ultra-anggaran, biasanya menggunakan 30W atau lebih rendah, telah mengalami peningkatan TDP yang signifikan selama beberapa tahun terakhir.
Jika seseorang ingin membeli kartu grafis Nvidia yang dapat menarik semua arusnya hanya melalui slot PCI Express, maka seluruh inventaris Ampere harus dilewati. GeForce RTX 3050 memiliki TDP 100W dan karena slot memiliki batas 75W, diperlukan konektor daya tambahan.
Kartu semacam itu, seperti saudara mereka yang jauh lebih besar, memiliki kekuatan pemrosesan yang jauh lebih besar daripada sebelumnya, tetapi bagi orang yang ingin membangun sistem berdaya sangat rendah, semakin sedikit pilihan untuk dipilih, jika menyangkut kartu grafis.
Dan sepertinya tidak ada tanda-tanda kenaikan permintaan listrik melambat, apalagi menurun. Misalnya, peluncuran terbaru Intel ke pasar kartu grafis, seri Arc, saat ini dipimpin oleh A770. Kartu ini menggunakan chip dengan 21,4 miliar transistor, GDDR6 16GB, dan TDP 225W. Meskipun ditargetkan pada sektor kelas menengah, permintaan daya tersebut sama dengan chip terbesar AMD dan Nvidia dari empat tahun lalu.
Ini sedikit lebih baik untuk kartu GeForce dan Radeon kelas menengah, di mana RTX 3060 membutuhkan 170W dan RX 6600 XT mengonsumsi 160W, tetapi permintaan energi di semua sektor jauh lebih tinggi daripada CPU. Jika bukan karena rekayasa yang lebih baik, permintaan itu jelas akan jauh lebih tinggi, tetapi pertanyaan penting yang benar-benar perlu dijawab di sini adalah apakah CPU dan GPU membutuhkan terlalu banyak daya untuk apa yang mereka tawarkan.
Berapa banyak itu?
Dua dari keluhan paling umum tentang peningkatan permintaan daya CPU dan GPU adalah biaya listrik dan jumlah panas yang dihasilkan. Mari kita lihat yang pertama, sebagai permulaan. Katakanlah Anda memiliki PC game yang sangat spesifik, penuh dengan beberapa komponen terbaik yang dapat Anda beli dengan uang. Mari kita asumsikan juga bahwa Anda menggunakan AMD Ryzen 9 5950X, didukung oleh Nvidia GeForce RTX 3090 Ti yang sedikit di-overclock.
Secara alami, akan ada bagian lain di sana juga (setidaknya, motherboard, beberapa RAM, dan drive penyimpanan), tetapi kita dapat mengesampingkannya karena konsumsi energi gabungannya akan jauh lebih rendah daripada CPU atau GPU. Jadi, kekuatan seperti apa yang dibutuhkan PC itu, di tengah kesibukan bermain game? Bagaimana suara 670W hingga 700W?
Sekarang bayangkan Anda menggunakan PC Anda dengan cara ini selama 2 jam, setiap hari, setiap hari dalam setahun. Jumlah energi yang dikonsumsi oleh PC akan menjadi sekitar 500 kWh (0,7 x 2 x 365) setara dengan menjalankan ketel listrik 1,5 kW selama hampir dua minggu, tanpa henti.
Tergantung di mana Anda tinggal di dunia, dan berapa tarif yang Anda bayarkan untuk listrik Anda, penggunaan PC seperti ini mungkin berkisar antara $70 hingga $280 (tidak termasuk pajak dan biaya tambahan), setiap tahun. Tetapi dibandingkan dengan total biaya PC itu sendiri, yang akan mencapai beberapa ribu dolar, itu adalah jumlah yang relatif kecil. Mengambil nilai yang lebih tinggi dan menghitung biaya listrik per jam permainan hanya setara dengan $0,38 per jam.
Skenario kasus terburuk dari komputer dengan kombinasi CPU dan GPU yang paling haus energi yang bisa Anda dapatkan saat ini (kartu di atas dan Intel Core i9-13900K), dengan keduanya berjalan pada batas daya default tertinggi, hanya akan menelan biaya sekitar $0,50 per jam, untuk rutinitas permainan yang sama.
Anda mungkin berpendapat bahwa bermain game 50 sen per jam terlalu tinggi, dan bagi jutaan orang di seluruh dunia, itu hampir pasti benar. Tapi mereka tidak mungkin memiliki PC seperti itu sejak awal. Konsol rumah lebih populer daripada PC game, dalam hal unit yang dikirim per tahun, dan berisi perangkat keras yang jauh lebih tidak mampu daripada contoh yang diberikan di atas. Namun dalam hal permintaan daya, sesuatu seperti Microsoft Xbox Series X hanya akan mengkonsumsi 153W selama bermain game aktif.
Bahkan jika Anda memperhitungkan TV OLED besar yang dapat menambah 100W lagi, gabungan kedua perangkat tersebut sebenarnya akan menggunakan energi 44% lebih sedikit daripada GeForce RTX 4090 saja. Jadi jika biaya listrik benar-benar menjadi perhatian, maka konsol adalah alternatif yang baik untuk bermain game.
Bukan berarti kamu harus menggunakan part PC terbaru atau tercanggih untuk menikmati game tentunya. Ada banyak komponen lama atau kelas menengah yang tidak membutuhkan daya terlalu tinggi, yang masih akan memberikan banyak performa. Kartu grafis Radeon RX 5700 XT bekas, GeForce RTX 2060 Super, atau bahkan GeForce GTX 1080 Ti masih sangat mumpuni dan ketiganya memiliki TDP 250W atau lebih rendah.
Singkatnya, argumen bahwa peningkatan daya adalah masalah, murni karena biaya listrik, agak diperdebatkan terlalu banyak bergantung pada harga lokal untuk satu unit listrik, kebiasaan bermain game, dll. untuk menyelesaikan debat semacam itu secara meyakinkan.
Tapi bagaimana dengan panasnya? Seperti disebutkan di awal artikel ini, hampir setiap joule energi listrik akhirnya hilang sebagai panas, ditransfer ke lingkungan sebagian besar melalui mekanisme konveksi. Komputer yang menghasilkan daya 900W, secara teori, dapat menaikkan suhu 1.000 kaki kubik udara (28 meter kubik) dari 20°C/68°F ke 40°C/104°F hanya dalam waktu 17 menit. Ini secara alami mengasumsikan perpindahan panas yang sempurna dan insulasi yang sempurna, tanpa pergerakan udara yang lebih panas keluar dari volume yang dimaksud.
Tetapi meskipun tidak secepat itu, pada kenyataannya, semua panas itu pada akhirnya masih akan ditransfer ke lingkungan sekitar PC, terlepas dari kecepatan transfernya. Kipas pendingin, berapa pun jumlah atau kinerjanya, tidak akan mengubah ini, karena hanya membantu menurunkan suhu komponen. Satu-satunya cara untuk mengurangi kenaikan panas lingkungan adalah dengan membiarkan udara panas berpindah ke tempat lain, melalui bukaan jendela, misalnya.
Jika Anda berencana menghabiskan banyak uang untuk CPU dan GPU paling kuat yang bisa Anda dapatkan, maka bersiaplah untuk fakta bahwa mereka akan membuang sejumlah besar energi panas ke ruang permainan Anda. Seperti halnya keluhan biaya listrik, ini pada akhirnya menjadi perhatian individu. Panas 900W mungkin menjadi masalah kronis bagi satu orang, tetapi tidak apa-apa bagi orang lain.
Kebutuhan lebih banyak daripada kebutuhan segelintir orang
Jadi tampaknya kekhawatiran tentang keluaran panas dan biaya listrik adalah masalah yang sangat individual. Namun, semuanya menjadi jauh lebih penting ketika diskalakan di seluruh dunia. Ada jutaan PC di luar sana, dan meskipun jumlah area yang mengemas chip 250W+ relatif kecil, pada akhirnya semua mesin ini akan diganti dengan komputer yang memiliki komponen yang membutuhkan daya lebih tinggi daripada yang mereka lakukan sekarang.
Untuk memahami hal ini, pertimbangkan bahwa diperkirakan ada 17 juta Xbox Series X dan 50 juta konsol Xbox One terjual di seluruh dunia. Yang pertama menggunakan daya sekitar 90W lebih banyak daripada yang terakhir. Jika kita berasumsi bahwa semua unit yang lebih tua diganti dengan yang lebih baru, itu adalah tambahan 3GW dari akumulasi permintaan daya dan, pada akhirnya, menghilangkan panas. Jelas, mesin-mesin ini tidak semuanya berjalan pada waktu yang sama, tetapi energi ekstra yang dibutuhkan tidak unik hanya untuk konsol ini.
Saat prosesor baru keluar untuk laptop, desktop, workstation, dan server, semuanya akan membutuhkan lebih banyak energi, baik itu beberapa watt atau seratus. Yang pada gilirannya berarti bahwa industri energi akan menghadapi permintaan yang semakin tinggi akan kemampuannya untuk memasok. Bagaimanapun, ini akan terjadi, karena pertumbuhan populasi dan ekonomi, tetapi masalahnya hanya akan diperparah oleh peningkatan daya semikonduktor ini.
Bahkan memperhitungkan penurunan penjualan PC seperti yang ditunjukkan oleh perkiraan selama beberapa tahun, ada sektor lain yang melakukan sebaliknya: Internet of Things (IoT), kecerdasan buatan (AI), dan analisis data besar semuanya menunjukkan banyak hal. pertumbuhan.
AI dan data besar menggunakan banyak GPU kelas atas untuk melakukan kalkulasi yang diperlukan dan jika komponen baru untuk mesin ini tidak menunjukkan tanda-tanda mengurangi permintaan dayanya, maka industri ini hanya akan memperburuk situasi energi.
Permintaan listrik, dalam skala global, diperkirakan oleh beberapa orang mencapai 3 kali lipat dari sekarang, tumbuh 3 hingga 4% setiap tahun, pada tahun 2050. Apakah perkiraan tersebut telah memperhitungkan peningkatan konsumsi energi prosesor masih belum jelas.
Sejak tahun 2005, perkiraan produksi listrik global telah meningkat dari 18 PWh (1 PWh = 1.000.000 GWh) menjadi 28 PWh pada tahun 2021, peningkatan sebesar 56% hanya dalam 16 tahun. Dan kenaikan itu sepenuhnya karena meningkatnya permintaan. Pertumbuhan penggunaan semikonduktor hanya akan menambahnya dalam beberapa dekade mendatang.
Jadi, jika ada, apa yang dapat dilakukan tentang hal itu?
Sebagai individu, ada banyak hal yang dapat Anda coba untuk menurunkan kebutuhan daya komponen PC terbesar Anda. Dalam kasus CPU, sebagian besar motherboard memiliki beragam opsi daya di BIOS yang akan memaksa prosesor untuk mengurangi konsumsi energinya saat idle.
Konfigurasi Lanjutan dan Antarmuka Daya (ACPI) muncul di komputer desktop pada tahun 1996 dan terus diperbarui sejak saat itu. Sekarang, semua CPU konsumen memiliki fitur yang sesuai dengan ACPI dan untuk konsumsi daya, ada dua yang terkenal: P-states dan C-states.
Yang pertama mengacu pada kondisi kinerja prosesor yang beroperasi, dan ketika diaktifkan di BIOS, memungkinkan chip berjalan pada frekuensi dan voltase yang lebih rendah, untuk menghemat energi. C-states melakukan hal serupa tetapi mengontrol apa yang dapat dilakukan CPU (misalnya memelihara data dalam cache atau menghapusnya seluruhnya) saat menjalankan dalam format yang tidak terlalu membutuhkan daya.
Untuk prosesor AMD Ryzen yang lebih baru (seri 3000 dan seterusnya), mengaktifkan Mode Eco di perangkat lunak Ryzen Master mereka akan memaksa prosesor untuk bekerja dengan TDP yang jauh lebih rendah, terlepas dari opsi ACPI apa pun yang diaktifkan.
Bergantung pada sistem yang digunakan dan metrik performa yang diukur, dampak penggunaan nilai daya yang lebih rendah bisa sangat kecil. Untuk pengguna CPU Intel, hal serupa dapat dicapai dengan mempelajari pengaturan BIOS dan mencari Manajemen Daya CPU Internal (tidak semua model memilikinya).
Di bagian ini, nilai untuk PL1 dan PL2 dapat diatur lebih rendah dari default, meskipun kemungkinan besar akan dicantumkan dengan nama yang berbeda. Misalnya, Asus menggunakan Batas Durasi Paket Panjang/Pendek untuk PL1/PL2.
Kartu grafis dapat di-tweak dengan cara yang sama, dengan menggunakan perangkat lunak seperti MSI Afterburner. Aplikasi ini memberikan kendali atas batas daya maksimum kartu, ditetapkan sebagai persentase, dan jumlahnya dapat diturunkan dengan mudah.
Misalnya, RTX 2080 Super Nvidia memiliki batas daya 100% 250W. Menjatuhkan ini menjadi 70% akan membatasi konsumsi daya GPU menjadi 175W. Secara alami, ini juga akan menurunkan kinerja kartu, tetapi seperti halnya Ryzen Eco Mode, dampaknya tidak sebesar yang Anda kira.
Hal serupa dapat dicapai dengan menurunkan voltase inti GPU, yang pada gilirannya biasanya akan memerlukan penurunan kecepatan jam juga. Alternatifnya, jika game menyediakan opsi untuk membatasi frekuensi gambar, menetapkannya pada nilai yang lebih rendah juga akan menurunkan permintaan daya.
Namun untuk kesederhanaannya, penyesuaian batas daya, melalui penggunaan penggeser sederhana, tidak dapat dikalahkan. Kami menjalankan beberapa pengujian cepat, menggunakan Shadow of the Tomb Raider, dengan kartu grafis yang disebutkan di atas (RTX 2080 Super) dan Intel Core i7-9700K. Resolusi game disetel ke 4K, dengan semua detail grafis disetel ke nilai maksimum, mode Kualitas DLSS diaktifkan, tetapi ray tracing dinonaktifkan.
Tampaknya tidak masuk akal bahwa pengurangan 50% dalam daya maksimum yang tersedia hanya menghasilkan pengurangan 10% dalam frekuensi gambar rata-rata (nilai Rendah 1% turun kurang dari 5%), tetapi perlu juga dicatat bahwa game ini memiliki cukup banyak beban CPU yang tinggi.
Penggunaan DLSS juga sangat membantu dalam pengujian ini, karena game merender pada resolusi yang jauh lebih rendah daripada yang disajikan, tetapi GPU hanya akan mencoba merender pada kecepatan yang lebih cepat, dan masih mencapai batas dayanya.
Jelas, pengaturan permainan dan perangkat keras yang berbeda akan menghasilkan hasil yang berbeda dari yang terlihat di atas, tetapi dalam Red Dead Redemption 2 (1440p, kualitas maksimal), pengurangan 50% dalam batas daya menghasilkan pengurangan 15% dalam frekuensi gambar rata-rata, dan untuk Jauh Cry 6, penurunan FPS hanya 7%.
Jadi semua ini mungkin menimbulkan pertanyaan sederhana mengapa vendor perangkat keras menetapkan batas daya begitu tinggi padahal tampaknya tidak perlu? Alasan yang paling mungkin adalah yang menyangkut pemasaran dan status produk. AMD, Intel, dan Nvidia membutuhkan model mereka untuk dibedakan sejelas mungkin, terutama di ujung kisaran halo. Produk-produk ini diharapkan menjadi yang terbaik yang dapat Anda beli, sehingga chip yang digunakan akan dipilih dari proses binning yang menghasilkan chip yang dapat berjalan pada kecepatan clock tertinggi, jika diberi daya yang cukup.
Namun hal ini dapat menyebabkan situasi seperti yang terlihat pada GeForce RTX 3090 Ti yang memiliki TDP 100W lebih tinggi daripada 3090 (29% lebih tinggi), tetapi bahkan pada 4K, pengujian kami hanya menunjukkan sekitar 10% lebih cepat dalam game. Karena semua vendor besar ingin menjual setiap kemungkinan chip yang diproduksi untuk mereka, model “beberapa persen lebih baik” tidak akan hilang, tetapi desainer pasti dapat mengurangi permintaan daya.
Produsen perangkat keras perlu berbuat lebih baik
Vendor seperti AMD sangat mempromosikan aspek kinerja per watt produk mereka dan biasanya menggunakannya sebagai titik penjualan utama. Misalnya, untuk arsitektur GPU desktop berikutnya, RDNA 3, perkiraan peningkatannya sangat besar. Namun, ini tidak berarti kartu grafis seri Radeon RX 7000 akan tiba-tiba memiliki TDP yang jauh lebih rendah.
Untuk RDNA 2, AMD menyoroti bahwa ia memiliki kinerja per watt hingga 65% lebih tinggi daripada arsitektur sebelumnya. Padahal, TDP Radeon RX 6800 masih 300W. Pengujian kami sendiri memverifikasi klaim AMD untuk kinerja per unit daya yang jauh lebih baik, tetapi itu tetap tidak mengurangi fakta bahwa peningkatan dalam daya render membutuhkan energi tambahan untuk memberi makan.
Orang mungkin berpendapat bahwa vendor harus membuatnya lebih mudah untuk mengurangi permintaan daya produk mereka, bahkan mungkin membuat mereka beroperasi dalam semacam ‘mode ramah lingkungan’ secara default. Pabrikan mungkin mengatakan bahwa mereka sudah melakukan ini, dalam bentuk membuat chip mereka beroperasi di berbagai level jam (mis. Turbo Mode, Boost Clock, Gaming Clock) dan meminta mereka menurunkan voltase secara signifikan saat tidak digunakan.
Tetapi ketika Intel meluncurkan CPU desktop Core generasi ke-12 mereka, siaran pers tersebut dikemas penuh dengan klaim kinerja tetapi hanya satu bagian yang berani menyebutkan kekuatan. Desain CPU baru, memadukan dua arsitektur berbeda dalam cetakan yang sama, jelas merupakan peningkatan dari model generasi ke-11 yang setara. Seperti yang ditunjukkan gambar di atas, Intel dapat menyetel TDP ke 95W, dan PL2 ke 125W, dan masih dapat membanggakan kinerja yang lebih tinggi.
Sebaliknya, mereka mempertahankan angka yang sama seperti sebelumnya dan hanya memotong 10W dari nilai PL2. Semua atas nama memiliki produk yang sedikit lebih cepat daripada kompetisi dalam pengujian tertentu. Tentu saja, Anda tidak perlu membeli chip ini, tetapi ketika tiba waktunya untuk melakukan peningkatan atau hanya membeli komputer atau konsol baru, Anda memiliki sedikit pilihan untuk menerima penawaran yang haus daya ini, karena model lama sudah tidak diproduksi lagi.
Orang-orang pada umumnya mengubah perspektif mereka tentang produksi energi, permintaan, dan dampaknya terhadap iklim dan dompet mereka. Sementara produk halo dan selera mereka yang tak terpuaskan akan energi menjadi berita utama, pertumbuhan yang stabil dalam kebutuhan daya di seluruh sektorlah yang benar-benar penting.
Dapat dikatakan bahwa terlalu banyak produsen semikonduktor terjebak dalam pola pikir yang tampaknya bertentangan dengan dunia saat ini yang memiliki kinerja setinggi mungkin, untuk mengalahkan persaingan, dengan biaya berapa pun. Namun, ada sedikit cahaya di ujung terowongan. Apple, misalnya, telah menggeser hampir seluruh lini Mac dan MacBook untuk menggunakan prosesor M1/M2 mereka sendiri. Prosesor gabungan CPU+GPU ini dirancang agar hemat energi dan bekerja setara dengan penawaran x86 dari AMD dan Intel, dengan permintaan daya yang jauh lebih rendah (kecuali game).
Server dan workstation umumnya masih dikemas dengan prosesor Intel Xeon atau AMD Epyc, tetapi arsitektur Arm hemat daya yang digunakan oleh Apple, juga menyebar ke sektor ini. Penyedia cloud besar mengganti server mereka dengan beberapa yang ditenagai oleh model Altra Ampere.
Perubahan datang perlahan, terkadang menyakitkan, tetapi itu akan datang. Mungkin perlu bertahun-tahun lagi sebelum kita mulai melihat prosesor baru diluncurkan dengan kebutuhan energi yang lebih rendah daripada pendahulunya, tetapi ada beberapa pergerakan dalam industri menuju tujuan itu.
Sementara itu, pada tingkat pribadi, kami dapat membuat pilihan sederhana: menerima permintaan daya dari perangkat keras terbaru dan menggunakannya apa adanya (dengan atau tanpa mengutak-atik beberapa pengaturan), atau memberikan suara dengan dompet kami dan memberi tahu vendor bahwa ratusan watt daya adalah harga yang terlalu tinggi untuk dibayar.
![]()
![]()
![]()
![]()
![]()

Rumor Intel Dan AMD Menunjukkan Rencana CPU Yang Mengecewakan Untuk Tahun 2023
Rumor Intel Dan AMD Menunjukkan Rencana CPU Yang Mengecewakan Untuk Tahun 2023 – Tahun depan, pertempuran prosesor desktop akan terus diperjuangkan antara Raptor Lake dengan Intel yang merencanakan kopling baru dari chip generasi ke-13 saat ini dan AMD Zen 4, menurut rumor terbaru dari seorang leaker China yang terkenal.
Rumor Intel Dan AMD Menunjukkan Rencana CPU Yang Mengecewakan Untuk Tahun 2023

zorba-xquery – Namun, kita akan melihat setidaknya beberapa silikon baru di awal tahun 2023, ketika kita dapat mengharapkan untuk disuguhi flagship Raptor Lake baru, 13900KS, sebuah CPU yang telah dibicarakan oleh Intel sebagai peningkatan kecepatan 6GHz di luar kotak yang cukup membuka mata.
Balasan AMD untuk itu menurut ECSM, akan menjadi versi 3D V-Cache baru dari prosesor Ryzen 7000 tetapi ini tidak akan melampaui model 8-inti , tampaknya. ECSM menganggap bahwa X3D 6-core dan 8-core berputar pada chip Zen 4 masuk, tetapi tidak ada lagi yang direncanakan, dan tidak ada prosesor yang lebih kuat dengan 3D V-Cache (atau setidaknya yang belum terlihat).
Baca Juga : Trik pendinginan CPU AMD Ryzen 7000 Ini Adalah Sesuatu Yang Tidak Boleh Anda Coba Di Rumah
Kami seharusnya melihat 13900KS, dan apa yang kemungkinan akan menjadi Ryzen 5 7600X3D dan Ryzen 7 7700X3D, di tengah, atau nanti, H1 2023. Jadi mungkin kita melihat April hingga Juni, atau sekitar itu, untuk chip baru untuk benar-benar dijual (pengungkapan bisa datang jauh lebih awal, mungkin).
Rupanya nanti pada kuartal ketiga tahun 2023 (September atau sekitar itu), Intel sedang merencanakan penyegaran Raptor Lake, mengambil prosesor utama dari jajaran saat ini dan meningkatkan kecepatan clock sebesar 100MHz hingga 200MHz. Jadi, ini hanya akan menjadi masalah peningkatan kecil, dan spesifikasi utama, jumlah inti, dan semacamnya, dari prosesor baru ini akan tetap sama dengan model generasi ke-13 saat ini.
Tampaknya CPU generasi berikutnya Meteor Lake dan Arrow Lake tidak akan memulai debutnya sama sekali tahun depan, dan sebagai gantinya akan keluar pada tahun 2024. Kami masih mengharapkan Meteor Lake akan muncul pada tahun 2023, meskipun tidak menurut ECSM; tetapi di tempat lain di pabrik rumor, ini masih dianggap sebagai kemungkinan. Tambahkan bumbu dalam jumlah besar dengan ini, tentu saja, dan info lain yang disampaikan oleh pembocor di sini.
Analisis: Tidak banyak yang bisa dilakukan untuk tahun 2023?
Pada dasarnya, Intel tidak akan berbuat banyak tahun depan dengan asumsi ECSM menggunakan uang dengan rumor baru ini, tentu saja dan AMD juga tidak akan melakukannya. Kita akan mendapatkan penyegaran yang sangat kecil dari silikon Raptor Lake, tetapi Meteor Lake dan Arrow Lake masih jauh. Seperti halnya Zen 5 dalam hal ini, tetapi kami tahu bahwa memang demikian rencana Intel yang tampaknya berubah yang merupakan kejutan yang lebih besar di sini.
Yang mengatakan, banyak orang mengharapkan untuk melihat varian X3D yang gemuk dari AMD, jadi itu sesuatu yang mengejutkan untuk mengetahui bahwa kita mungkin tidak mendapatkannya. Setidaknya tidak untuk memulai, meskipun dalam keadilan, model V-Cache 3D 8-core (kemungkinan 7700X3D) adalah yang akan menarik dari sudut pandang game arus utama. Itulah chip Ryzen yang diharapkan banyak orang menjadi prosesor hebat yang menyebabkan masalah Intel pada tahun 2023.
Seharusnya, Intel Meteor Lake akan dikonfigurasikan dengan chip top-end yang memiliki 6 core kinerja dan 16 core efisiensi, jadi tanpa versi CPU desktop high-end dengan kata lain (dengan spekulasi lain menunjukkan kisaran mungkin lebih terfokus pada chip seluler ).
8 core kinerja untuk model desktop teratas (Core i7, i9) diharapkan akan dibawa dengan Arrow Lake, oleh karena itu keduanya sekarang mendarat pada tahun 2024, mencakup ujung spektrum kinerja yang berbeda. Baik Meteor dan Arrow Lake akan membutuhkan soket dan platform baru, dan akan melawan Zen 5 pada tahun 2024. Namun, sementara itu, kedengarannya seperti tahun yang tenang di bagian depan prosesor untuk tahun 2023…
![]()
![]()
![]()
![]()
![]()

Trik pendinginan CPU AMD Ryzen 7000 Ini Adalah Sesuatu Yang Tidak Boleh Anda Coba Di Rumah
Trik pendinginan CPU AMD Ryzen 7000 Ini Adalah Sesuatu Yang Tidak Boleh Anda Coba Di Rumah – Prosesor AMD Ryzen 7000 mendapat kecaman karena desain integrated heat spreader (IHS), dan bagaimana hal itu tidak membantu termal tetapi ada cara untuk mengatasi hal ini, yang akan memastikan chip berjalan sedikit lebih dingin. Namun, ini jelas bukan sesuatu yang kami sarankan untuk dicoba oleh rata-rata pengguna (bukan berarti mereka akan diperlengkapi).
Trik pendinginan CPU AMD Ryzen 7000 Ini Adalah Sesuatu Yang Tidak Boleh Anda Coba Di Rumah

zorba-xquery – Mengapa? Yah, karena melibatkan mengambil prosesor Zen 4 baru yang mengkilap dan mengeksposnya ke alat gerinda. Ya, solusi untuk IHS tebal untuk generasi Ryzen ini yang akan kita bahas di kemudian hari adalah membuatnya lebih tipis dengan menggilingnya.
Jelas ini bukan sesuatu yang ingin dilakukan oleh rata-rata pemilik PC, tetapi tipe yang lebih hardcore mungkin mempertimbangkan untuk menjelajahi jalan ini dan beberapa telah melakukannya dalam kasus JayzTwoCents dengan menggunakan alat gerinda ahli overclocker Der8auer seperti yang terlihat di Twitter oleh Andreas Schilling (via Tom’s Hardware). Hasil pengurangan IHS CPU Ryzen 9 7950X sebesar 0,8 mm terbukti merupakan penurunan suhu dari 94-95C, turun menjadi 85-88C, penurunan yang cukup besar (itu adalah suhu yang berjalan pada 5,1GHz di semua inti untuk CPU).
Analisis: Yang lebih rendah dari dua kejahatan? Yah, tidak persis
Pada dasarnya, ini adalah alternatif untuk prosedur berisiko lain yang dikenal sebagai ‘delidding’, di mana CPU benar-benar menghapus IHS, yang dapat mengakibatkan penurunan suhu yang lebih besar. (Der8auer menunjukkan pengurangan 20C yang sangat besar ketika mendelidding 7900X sebelumnya, meskipun itu menggunakan pelumas termal logam cair khusus yang merupakan ramuan kustom overclocker sendiri).
Baca Juga : Bocoran Ryzen 3 7300X Memberi Kami Harapan Bahwa AMD Sedang Merencanakan CPU Anggaran Zen 4
Menggiling IHS mewakili jalur yang agak kurang berisiko dan juga tidak terlalu rumit, karena ada banyak pekerjaan ekstra dalam memasang solusi pendinginan ke chip delidded (berukuran sangat berbeda) tetapi diberikan, dalam kedua kasus, Anda membatalkan garansi Anda. Dan kecuali Anda benar-benar tahu apa yang Anda lakukan, Anda berisiko merusak CPU seperti yang Anda bayangkan ketika harus melakukan tindakan drastis seperti memisahkannya atau menghancurkannya. Itulah sebabnya kami benar-benar tidak akan merekomendasikan ini kepada siapa pun kecuali penggemar ahli (yang mampu membayar biaya jika ada yang salah, dalam hal ini).
Seluruh latar belakang untuk ini adalah bahwa AMD telah menggunakan desain yang lebih tebal untuk IHS dengan chip Zen 4 pada platform AM5 (dengan soket prosesor baru). Ini untuk menjaga kompatibilitas dengan CPU Ryzen 7000 baru dalam hal pendingin yang ada (platform AM4) sehingga orang tidak perlu membeli solusi pendinginan baru karena soket baru lebih datar, artinya chip berada sedikit lebih rendah (jadi IHS yang lebih tebal menutupi perbedaan itu). Tapi ketebalan 1mm ekstra dari biasanya agak kontraproduktif untuk termal yang baik.
Sekarang, AMD menganggap itu baik-baik saja untuk Ryzen 9 7950X untuk terus berdetak pada suhu seperti 95C, tetapi beberapa penggemar berbeda, karenanya kontroversi. Dan karenanya mencukur 0,8mm untuk mengembalikan IHS ke ukuran pra-Ryzen 7000 sebelumnya, dengan menjalankan prosesor pada lebih seperti 85C, pemilik level lebih bahagia.
Selain itu, jangan lupa IHS ada untuk memberikan perlindungan bagi CPU, dan dengan delidding yang mewakili risiko ekstra dalam hal membiarkan die terbuka sementara penggilingan masih menyisakan tutup pelindung pada chip, seolah-olah.
Jika Anda khawatir tentang suhu Zen 4 Anda yang mungkin, tentu saja, bervariasi dari kasus ke kasus daripada memilih rute ini, itu adalah ide yang jauh lebih baik dan lebih layak untuk melihat solusi alternatif seperti menggunakan pengaturan mode Eco (di AMD’s perangkat lunak Ryzen Master) untuk mengendalikan panas itu. (Atau undervolting adalah pilihan lain, mungkin).
![]()
![]()
![]()
![]()
![]()

Bocoran Ryzen 3 7300X Memberi Kami Harapan Bahwa AMD Sedang Merencanakan CPU Anggaran Zen 4
Bocoran Ryzen 3 7300X Memberi Kami Harapan Bahwa AMD Sedang Merencanakan CPU Anggaran Zen 4 – AMD dapat memiliki beberapa prosesor Zen 4 baru yang masuk, salah satunya secara teori Ryzen 7 7800X, dan yang lainnya Ryzen 3 7300X. Chip Zen 4 ini telah terlihat di Geekbench oleh Benchleaks (seperti yang dilaporkan VideoCardz, meskipun mereka menghapus ceritanya segera setelah diposting), dan tampaknya 7800X akan membuat lompatan menjadi prosesor 10-inti, setidaknya jika spesifikasi yang disediakan benar. Tentu saja, kita harus memperlakukan bocoran ini dengan hati-hati seperti biasa yang harus diterapkan pada rumor apa pun.
Bocoran Ryzen 3 7300X Memberi Kami Harapan Bahwa AMD Sedang Merencanakan CPU Anggaran Zen 4

zorba-xquery – 7800X terlihat dengan 10-core dan 20-threads dengan kecepatan boost yang ditunjukkan hingga 5,4GHz. Adapun Ryzen 3 7300X teoretis, entri Geekbench-nya menunjukkan bahwa itu adalah CPU quad-core dengan peningkatan hingga 5GHz.
Bagaimana dengan hasil Geekbench sendiri? 7800X masing-masing mencapai 2.097 dan 16.163 untuk single-core dan multi-core. Itu sedikit kurang dari 7700X yang ada di yang pertama, tetapi dengan nyaman mengalahkan chip itu sekitar 15% di yang terakhir seperti yang Anda harapkan dengan sepasang inti tambahan untuk 7800X.
Baca Juga : 5 Software Akuntansi Penggajian Terbaik Tahun 2021
Ryzen 3 7300X mencapai 1.984 dan 7.682 untuk single-core dan multi-core, yang secara mengejutkan menjadikannya sebagai bagian belakang keluarga Ryzen 7000. Ini tidak terlalu jauh dari Ryzen 5 7600X untuk single-core, dan memang yang terakhir hanya 7% lebih cepat. (Ingatlah pada kedua hitungan untuk 7800X dan 7300X bahwa ini adalah prosesor pra-rilis, jadi kemungkinan besar belum menunjukkan tingkat kinerja penuhnya).
Analisis: Apakah CPU Ryzen 3 untuk Zen 4 benar-benar masuk akal sejak awal?
Ryzen 7800X dengan 10-core tampaknya menjadi pilihan yang aneh, mungkin, mengingat bahwa 5800X adalah CPU 8-core lurus. Seperti yang dapat kita lihat dari benchmark, dalam bentuk ini dengan dua core tambahan, ini akan mewakili langkah yang solid dari 7700X dan membedakan prosesor ini lebih banyak, setidaknya dalam hal kinerja multi-threaded.
Apa yang lebih mungkin menjadi perhatian di sini adalah 7300X, dan prospek penuh harapan bahwa CPU Ryzen 3 untuk generasi Zen 4 bisa masuk. Ini adalah opsi yang diinginkan oleh beberapa orang yang ingin membuat PC ramah anggaran, dan tidak didapatkan dengan kisaran Ryzen 5000. (Ada Ryzen 5 5500 yang diluncurkan awal tahun ini, tetapi selain itu, tidak ada silikon Ryzen 3, dan hanya ada chip berbasis Ryzen 4000 Zen 2 di ujung terendah pasar untuk AMD).
Akankah Ryzen 3 7300X ini benar-benar terjadi? Kami tidak yakin, dan tentu saja ada argumen untuk tetap skeptis di sini. Melepaskan chip semacam itu akan membutuhkan AMD untuk mengarahkan setidaknya beberapa sumber daya produksi untuk memproduksinya, tentu saja, dan produk-produk kelas bawah ini memiliki margin keuntungan yang jauh lebih kecil dibandingkan dengan apa yang ada di meja sekarang. Jadi, apakah benar-benar masuk akal untuk melakukannya di awal permainan untuk keluarga Ryzen 7000?
Kemungkinan lain adalah menggunakan apa yang pada dasarnya ditolak untuk chip yang lebih besar (dengan inti dinonaktifkan hingga CPU quad-core), tetapi hasilnya sangat bagus akhir-akhir ini, sehingga silikon bermasalah seperti ini menjadi relatif tipis di lapangan.
Artinya jika Ryzen 3 7300X akan datang, kemungkinan besar tidak akan cukup untuk beberapa waktu untuk membangun chip yang diperlukan dan terlebih lagi, itu mungkin akan menjadi produksi terbatas juga. (Seperti situasi dengan favorit anggaran lama dengan Ryzen 3000, Ryzen 3 3100 dan 3300X, yang sulit didapat; terlebih lagi dalam kasus terakhir).
Selain itu, ada juga pertimbangan bahwa beralih ke Zen 4 adalah proposisi yang masih mahal dengan biaya motherboard AM5 yang diperlukan (dan RAM DDR5), yang sekali lagi merupakan argumen lain bahwa setiap penawaran Ryzen 3 tidak akan masuk akal sebagai hal jangka pendek (sebagai chip yang terjangkau, tetapi tanpa mobo yang sama terjangkaunya untuk melengkapinya). Jangka panjang, tentu saja, kita akan melihat harga motherboard turun dan model kelas bawah muncul bagi mereka yang ingin membangun PC bertenaga AMD baru yang mengkilap (ditambah DDR5 juga akan turun lebih jauh menurut perkiraan).
Singkatnya, kami menyarankan kegembiraan apa pun di sekitar 7300X harus diimbangi dengan dosis kenyataan yang mungkin terjadi di sini. Tapi kami tidak menyangkal senang melihat chip Ryzen 3 mengambang di tahap permainan ini, dan penampakan CPU memang menjanjikan masa depan dalam hal pembuatan PC anggaran. Sementara itu, kita tentu saja dapat menantikan chip Ryzen 5000 yang lebih murah karena generasi itu menyaring menuju pintu keluar…
![]()
![]()
![]()
![]()
![]()