Pengujian Komponen Xquery – Program xquery memiliki banyak sekali komponen yang sengaja disertakan untuk melengkapi dan memudahkan dalam proses pemrograman dan pembuatan html. Komponen yang diberikan tersebut memiliki manfaat yang cukup besar untuk penggunanya dalam rangka menyusun program html yang jauh lebih sederhana namun sarat akan informasi yang akurat. Komponen-komponen tersebut sengaja diberikan untuk mempermudah proses pemrograman html yang diperlukan. Tanpa adanya komponen-komponen tersebut tentu akan sulit untuk membuat program yang sesuai dengan harapan dan tujuan dari pemanfaatan program. Komponen dalam xquery diberikan sengaja untuk melengkapi kekurangan pada program xquery pada versi sebelumnya. Tujuannya adalah untuk meminimalisir terjadinya kesalahan atau bug pada program html yang dijalankan oleh pengguna.
Komponen yang diberikan di dalam program versi terbaru dari xquery diantaranya adalah program satu baris. Program komponen satu baris memungkinkan pengguna untuk membuat label-lebel dalam satu baris tertentu yang tentu saja akan menghemat ruang penyimpanan. Selain dapat menghemat ruang penyimpanan, komponen satu baris membuat proses labelisasi bisa dijalankan dengan optimal dengan ruang yang minimal. Hal ini menunjukkan kapasitas xquery bahwa xquery mampu menjadi program yang akan mempermudah sekaligus membuat efisien kinerja dari prosesor html yang digunakan. Sebab di dalam menjalankannya tidak diperlukan ruang penyimpanan yang besar untuk menjalankan sebuah hasil kerja program html yang dikerjakan.
Komponen berikutnya yang diberikan adalah komponen literasi. Komponen literasi diberikan secara khusus untuk membuat data yang dimasukkan bisa disertai dengan sumber yang akurat. Pemberian informasi sumber data member judi online sangat penting untuk diberikan, sebab dalam pembuatan html ingin mendapatkan informasi akurat yang diperoleh dari data-data member yang dikumpulkan secara resmi dan juga dikumpulkan secara akurat di dalam program html yang dijalankan. Tanpa adanya sumber informasi dan juga sumber data yang disertakan, maka html menjadi tidak memiliki fungsi untuk memberikan informasi yang sebenar-benarnya. Fungsi literasi pada xquery memberikan ruang dan juga kemudahan untuk pemrogram agar bisa memasukkan sejumlah data akurat untuk melengkapi program yang sedang dijalankan.
Pengujian komponen tersebut dilakukan secara bersamaan. Tanpa adanya pengujian yang dilakukan secara bersamaan, pihak pengguna tidak akan mengetahui apakah semua fungsi dalam komponen xquery bisa digunakan atau tidak. Proses pengujian sengaja dilakukan guna menjamin bahwa program xquery berfungsi sebagaimana mestinya. Sehingga penggunaan program xquery tidak akan mengecewakan. Terlebih dengan adanya tambahan-tambahan fungsi yang benar-benar membantu proses pemrograman html yang diperlukan. Pengujian dijalankan secara bersamaan agar diketahui secara pasti bagaimana posisi komponen-komponen dalam xquery yang menjadi unggulan. Tanpa adanya pengujian yang dilakukan secara bersamaan maka tidak akan diketahui dengan pasti apakah setiap komponen berfungsi seperti yang seharusnya. Tujuannya jelas untuk mempermudah pengguna untuk membuat program html yang sangat diperlukan dan sangat membantu.

5 Software Akuntansi Penggajian Terbaik Tahun 2021
5 Software Akuntansi Penggajian Terbaik Tahun 2021 – Layanan pemrosesan penggajianadalah layanan akuntansi yang paling biasa dan memakan waktu. Ini memotong sebagian besar waktu pemegang buku. Menurut satu laporan bisnis kecil, 11% bisnis menghabiskan lebih dari 80 jam untuk manajemen penggajian.
5 Software Akuntansi Penggajian Terbaik Tahun 2021

zorba-xquery – Itu banyak waktu! Sekarang, perusahaan tidak perlu membuang waktu berharga mereka pada manajemen penggajian ketika layanan penggajian untuk usaha kecil dapat dengan mudah diotomatisasi.
Dengan perangkat lunak penggajian yang tepat, usaha kecil dapat dengan mudah menghemat banyak waktu dan fokus pada hal-hal mendesak lainnya.
Anda tidak dapat menghindari manajemen penggajian atau memajukan bisnis Anda tanpanya. Jadi, sangat ideal bagi bisnis untuk memilih solusi penggajian yang sempurna dan terus bergerak maju.
Baca Juga : Cara Menginstal Dan Menggunakan Prosesor Oracle XQuery
Bagaimana Memilih Software Penggajian yang Cocok untuk Bisnis Anda? 5 Tips Cepat
Ada berbagai perangkat lunak manajemen penggajian yang tersedia di pasar dari gratis hingga berbayar. Jadi, temukan perangkat lunak yang sesuai yang dapat memperlancarlayanan pemrosesan penggajiansangat sulit tapi bukan tidak mungkin.
Jika Anda mengikuti arah yang benar saat memilih perangkat lunak penggajian Anda, Anda dapat dengan cepat menemukan solusi sempurna untuk bisnis Anda.
Tip 1. Apa yang Anda Butuhkan?
Sebelum memberikanlayanan outsourcing penggajiankepada klien kami, di CapActix, kami selalu meminta mereka untuk mendefinisikan kebutuhan mereka.
Setelah klien kami menentukan kebutuhan manajemen penggajian mereka berdasarkan biaya, ukuran, persyaratan pelaporan, dan fitur lainnya, kami dengan mudah membantu mereka menemukan solusi penggajian yang sempurna.
- Jumlah Karyawan
- Ukuran bisnis
- Anggaran gaji
- Tunjangan karyawan, dll.
Tip 2. Fitur apa yang Anda inginkan?
Perangkat lunak penggajian hadir dalam berbagai fitur dan fungsi yang berbeda. Beberapa perangkat lunak bahkan menawarkan fasilitas fitur tambahan untuk meningkatkan kekuatan sistem penggajian Anda.
Ini adalah tip yang sangat penting untuk dipertimbangkan karena fitur mempengaruhi akurasi dan kegunaan perangkat lunak. Untuk menjalankan sistem penggajian yang efektif, Anda mungkin memerlukan fitur berikut.
- Manajemen Kepatuhan
- Periksa Pencetakan
- Akses Seluler
- Antarmuka pengguna yang mudah
- Sistem Penggajian Tanpa Kertas
- Laporan lengkap , dll.
Anda tidak dapat memilih perangkat lunak penggajian yang benar tanpa menentukan anggaran Anda. Ada berbagai solusi penggajian yang tersedia dalam kisaran harga yang berbeda dari beberapa ratus hingga ribuan perangkat lunak penggajian.
Selain itu, ada beberapa alat sumber terbuka dan gratis juga tersedia. Sejaklayanan penggajian untuk usaha kecildianggarkan dengan ketat sehingga Anda harus mencari perangkat lunak hanya setelah menentukan anggaran Anda.
Tip 4. Seberapa Amankah Perangkat Lunak Anda?
Manajemen penggajian adalah proses yang sangat sensitif. Anda berurusan dengan data rahasia karyawan dan perusahaan di dalamnya. Karena itu, carilah perangkat lunak yang menawarkan fitur keamanan kualitas premium seperti pengaturan akses pengguna, perlindungan kata sandi, keamanan otentikasi dua faktor, dll.Tip 5. Apakah Anda Ingin Solusi Lokal atau Berbasis Cloud?
Perangkat lunak penggajian tersedia dalam struktur lokal dan berbasis cloud. Dengan perangkat lunak lokal, Anda dapat mencapai tingkat keamanan yang tinggi, tetapi biayanya mahal untuk usaha kecil.
Sebaliknya, perangkat lunak berbasis cloud fleksibel, terjangkau, dan cepat, tetapi kurang aman. Jadi, Anda perlu membaca pro dan kontra dari kedua sistem sebelum membuat keputusan.
5 Software Penggajian Terbaik untuk Bisnis Anda
Berdasarkan tips seleksi dan pengalaman real-time kami, kami ingin menyarankan beberapa solusi manajemen penggajian berperingkat teratas.1. Penggajian Online QuickBooks
QuickBooks Online Payroll, alias, QBOP adalah perangkat lunak penggajian paling populer yang tersedia di pasar. Perangkat lunak ini dihargai oleh pakar akuntansi di seluruh dunia, termasuk AS, Inggris, Australia, dan Selandia Baru. Mudah digunakan dan beberapa fitur terintegrasi menjadikan QBOP perangkat lunak penggajian terbaik yang tersedia di luar sana.
Fitur Utama
- Memberikan solusi penggajian yang lengkap
- Mudah diintegrasikan dengan alat bisnis lainnya
- Diadopsi oleh berbagai industri
- Terjangkau untuk usaha kecil, dll.
2. Semangat
Ini adalah solusi penggajian yang sangat mudah dan revolusioner untuk bisnis kecil. Ini menghemat waktu pemegang buku dan menghilangkan kesalahan rumit yang dibuat oleh entri data manual.
Platform ini menawarkan fitur manajemen penggajian yang dinamis bersama dengan antarmuka yang menarik dan memberikan solusi inovatif yang konstan kepada pengguna.
Fitur Utama
- Mudah untuk mengambil informasi
- Minimalkan kesalahan
- Otomatisasi penggajian ujung ke ujung
- Sangat terintegrasi, dll.
3. Gaji Sage
Ini adalah salah satu solusi manajemen penggajian termurah yang tersedia di luar sana. Perangkat lunak ini mungkin tidak memiliki banyak fitur, tetapi berisi semua fungsi dasar untuk menjalankan sistem penggajian yang lancar.
Ini adalah perangkat lunak yang ideal dengan fitur keamanan kelas atas seperti cloud terenkripsi, kontrol akses pengguna, dan banyak lagi untuk bisnis kecil.
Fitur Utama
- Solusi penggajian yang terjangkau
- Keamanan luar biasa
- Sesuaikan penggunaan kontrol dan akses
- Sistem pelaporan yang kuat, dll.
4. Xero
Xero bukan hanya solusi penggajian. Ini adalah sistem akuntansi berbasis web yang dikembangkan untuk membantu usaha kecil. Tambahan untuk layanan penggajian, ini dikemas dengan manajemen aset, pelacakan inventaris, dan banyak layanan lainnya. Oleh karena itu, jika Anda sedang mencari partner akuntansi yang lengkap untuk bisnis Anda, dapatkan saja Xero.
Fitur Utama
- Catat semua formulir transaksi dengan lengkap
- Sesuaikan laporan dengan mudah
- Solusi aplikasi seluler
- Memfasilitasi pengambilan keputusan berdasarkan data
- Uji coba gratis 30 hari untuk menguji perangkat lunak, dll.
5. Melambai
Wave sangat disukai oleh akuntan lepas dan beberapa penyedia layanan outsourcing penggajian. Sebagian besar fungsi penggajian inti ditawarkan secara gratis. Ini adalah salah satu alat untuk mengelola pekerjaan terkait akuntansi dan pengeluaran.Dengan Wave, pengguna dapat mengadopsi model pembayaran standar atau dapat menyesuaikannya sesuai kebutuhan mereka. Selain itu, metode izin pembayaran cepat yang disediakan oleh Wave luar biasa.
Fitur Utama
- Aplikasi penggajian gratis tanpa biaya tersembunyi
- Izin pembayaran cepat
- Transfer dana mudah
- Dapat disesuaikan sesuai spesifikasi bisnis, dll.
Manajemen penggajian adalah bagian yang tidak dapat dihindari dari bisnis Anda. Jika sistem penggajian Anda tidak cepat, sempurna, dan marah, Anda tidak dapat menjalankan bisnis Anda secara efektif.
Oleh karena itu, disarankan untuk memilih perangkat lunak akuntansi penggajian yang sesuai untuk bisnis Anda dan mengotomatiskan tugas biasa.
Namun, jika Anda tidak ingin repot mencari perangkat lunak penggajian yang sesuai, Anda dapat mengalihdayakan layanan penggajian dari CapActix dan tetap fokus mengembangkan bisnis Anda.

Cara Menginstal Dan Menggunakan Prosesor Oracle XQuery
Cara Menginstal Dan Menggunakan Prosesor Oracle XQuery – Sebagai Pemrogram Java, jika Anda bekerja dengan XML , Anda harus belajar tentang XQuery dan cara menggunakannya. XQuery adalah bahasa query untuk XML. Ini mirip dengan XPath karena menggunakan konstruksi yang sama atau serupa untuk mengidentifikasi bagian tertentu dari dokumen XML.
Cara Menginstal Dan Menggunakan Prosesor Oracle XQuery

zorba-xquery – XQuery menawarkan fasilitas untuk memperbarui dan memodifikasi dokumen XML. Ini dilakukan dengan menggunakan bahasa yang mirip (setidaknya dalam konsep jika tidak dalam bentuk) dengan SQL untuk database.
Sangat mudah untuk bekerja dengan XPath di java karena ketersediaan mesin XPath di dalam java SDK. Bekerja dengan XQuery lebih menantang karena Anda harus mengintegrasikan prosesor XQuery ke dalam perangkat Java Anda. Artikel ini menunjukkan cara melakukannya.
Baca Juga : Debugging OSB Xqueries Dengan XMLSpy Atau XQDT Dan Zorba – XQuery
Ada beberapa implementasi XQuery yang tersedia di web, beberapa di antaranya bersifat open-source sementara yang lain bersifat closed-source dan berpemilik. Pada artikel ini, kami menunjukkan kepada Anda cara mendapatkan dan menggunakan Prosesor XQuery Oracle untuk Java.
XQuery API didefinisikan oleh JSR-225 XQuery API untuk Java . Dan di sini adalah tautan ke javadocs Oracle XQuery Processor. Bahasa XQuery itu sendiri didefinisikan oleh XQuery 3.0: Bahasa Query XML.
2. Mendapatkan Prosesor Oracle XQuery untuk Java
Menemukan Prosesor Oracle XQuery untuk Java agak sulit. Sepertinya mereka menyembunyikannya dengan baik. Itu disertakan sebagai bagian dari Oracle Database (meskipun tidak dalam versi XE), tetapi siapa yang ingin menginstal Oracle Database hanya untuk mendapatkan prosesor XQuery? Tempat yang lebih baik untuk menemukan prosesor XQuery adalah Oracle Big Data Connectors .
Buka halaman ini dan klik tautan Oracle XQuery for Hadoop . Setuju dengan perjanjian lisensi yang disajikan, daftar untuk mendapatkan akun gratis, dan unduh toolkit. Itu harus berisi semua yang Anda butuhkan untuk menggunakan prosesor XQuery.
3. Memasang Guci untuk Maven
Kami menggunakan Maven jadi kami perlu mengekstrak toples dari paket yang diunduh dan menginstalnya. Kami membutuhkan toples berikut (ditunjukkan dengan path lengkap dalam paket):
- oxh-4.9.0-cdh5.0.0/hive/lib/oxquery.jar
- oxh-4.9.0-cdh5.0.0/hive/lib/xqjapi.jar
- oxh-4.9.0-cdh5.0.0/hive/lib/orai18n-mapping.jar
- oxh-4.9.0-cdh5.0.0/hive/lib/xmlparserv2_sans_jaxp_services.jar
- oxh-4.9.0-cdh5.0.0/hive/lib/Apache-xmlbeans.jar
Instal toples sehingga Maven dapat menemukannya dengan perintah berikut. Karena versi toples ini tidak diketahui, kami menggunakan versi generik 0.1 untuk semuanya.
4. Pembaruan untuk POM.XML
Untuk membangun perangkat lunak, kita memerlukan dependensi berikut di POM.Untuk membuat JAR gemuk (atau uber jar) yang dapat dijalankan dengan mudah, gunakan maven-assembly-plugin : Dan dengan pembaruan POM ini, mari kita beralih ke kode untuk menjalankan XQuery dari dalam Java.
5. Program XQuery Hello World Sederhana
<hello-world>2</hello-world>
5.1. Impor Jawa
Kami membutuhkan impor Java berikut: Mari kita mulai dengan membangun program hello-world sederhana yang mencetak berikut ini ke stdout :
5.2. Kelas Penyelesai Entitas
Kelas berikut adalah kelas penyelesai entitas yang didefinisikan sebagai kelas dalam, dan digunakan oleh prosesor XQuery untuk menyelesaikan file: ketik URLs .
5.3. Program Utama
Dan akhirnya fungsi main() yang menjalankan potongan kode XQuery. Kompilasi dan jalankan kelas ini untuk mendapatkan output dari penambahan 1 + 1 yang disematkan di dalam output XML.
6. Menjalankan kode XQuery Dari File
Contoh di atas menunjukkan cara menjalankan potongan kode XQuery dalam sebuah string. Itu juga tidak membaca XML apa pun. Untuk dapat menjalankan kode XQuery dari file, gunakan yang berikut ini. Perhatikan bahwa kami menyetel URI dasar menggunakan XQStaticContext.setBaseURI() sehingga referensi file XML relatif diselesaikan dengan benar.
Mari kita jalankan contoh file XQuery. Berikut adalah bagian dari contoh file XML books.xml : Saat menjalankan contoh XQuery ini, hasilnya seperti yang ditunjukkan. Perhatikan bahwa hanya elemen buku yang harganya lebih besar dari 30 yang dipilih.
Kesimpulan
Artikel ini menunjukkan kepada Anda cara mengintegrasikan XQuery ke dalam aplikasi Java Anda. XQuery sangat kuat dan dapat digunakan untuk berbagai permintaan XML dan tugas pembaruan yang akan sangat merepotkan. Dalam seri artikel berikutnya, kita akan membahas cara menggunakan XQuery untuk tugas-tugas ini dan banyak lagi.
![]()
![]()
![]()
![]()
![]()
Debugging OSB Xqueries Dengan XMLSpy Atau XQDT Dan Zorba – XQuery
Debugging OSB Xqueries Dengan XMLSpy Atau XQDT Dan Zorba – XQuery – Saya mencoba mendebug beberapa xqueries yang ditulis untuk Oracle Service Bus, menggunakan berbagai alat seperti XmlSpy, Eclipse XQDT dengan zorba dll. Mereka semua gagal karena “grup” fungsi xquery spesifik BEA yang mungkin setara dengan fungsi xquery “grup menurut” di xquery 3.0.
Debugging OSB Xqueries Dengan XMLSpy Atau XQDT Dan Zorba – XQuery

zorba-xquery – Jadi mesin xquery yang saya gunakan tidak mengenalinya, dan karena itu saya tidak dapat melakukan debugging langkah demi langkah. Saya telah menemukan di beberapa forum lain, daftar file jar yang mengimplementasikan fungsi xquery ini.
Jadi pertanyaannya adalah, apakah ada yang tahu apakah mungkin mengimpornya dalam zorba atau XMLSPY sehingga fungsi khusus vendor ini dikenali? Sayangnya Anda tidak akan mendapatkan prosesor XQuery lain untuk mengenali grup BEA berdasarkan klausa.
Baca Juga : Tutorial XQuery: Membangun Aplikasi Agregasi dan Pelaporan Layanan Web Berbasis XQuery
Berikut adalah dokumentasi untuk grup BEA oleh: Ini adalah ekstensi non-standar untuk bahasa yang ditambahkan sebelum klausa grup menurut ditambahkan ke XQuery 3.0.
kaitkan metode Java ke mesin xquery
Saya menggunakan XmlBeans untuk menjalankan komputasi XQuery dinamis pada beberapa data XML melalui XmlObject.execQuery() (Saat ini saya menggunakan WL8.1sp3). Sekarang, saya perlu menanyakan tabel DB eksternal, tentu dari dalam sumber XQuery; jadi saya perlu mengonfigurasi mesin untuk memanggil metode saya setelah pemanggilan fungsi XQuery.
eisenach
Ada banyak hal tentang subjek ini yang saya tidak tahu, tetapi inilah yang disediakan Platform Layanan Data AquaLogic (sebelumnya Liquid Data). Anda akan mendapatkan pustaka fungsi XQuery yang langsung mengakses sumber data.
Hmm saya tidak bisa menggunakan AquaLogic, karena saya terikat dengan lingkungan produksi yang tidak akan berubah.Saya sedang mencari cara untuk berinteraksi langsung dengan mesin XQRL, dan sepertinya ada kemungkinan, tetapi itu sama sekali tidak terdokumentasi, saya mengerti .
Apa yang Anda maksud dengan “tidak akan berubah”? Jelas, jika Anda tidak dapat mengubahnya sama sekali, Anda tidak dapat mencapai apa pun. Dengan mengatakan ini, Anda mungkin berpikir bahwa “AquaLogic” berarti WLS 9. Tidak demikian halnya dengan ALDSP saat ini. Ini diimplementasikan pada WLS 8.1.
Saya tahu apa itu ALDSP, dan saya sudah menggunakannya dalam beberapa konteks lain. Maksudku, itu tidak akan dibeli oleh pelanggan ini, jadi itu tidak tersedia untukku : Apa yang saya coba capai adalah meniru ‘Metode Pengguna seperti yang Anda lihat dan menggunakannya oleh XQuery ke dalam kontrol transformasi Workshop: Anda menulis sebuah metode dalam Java, lalu menandainya dengan anotasi dtf:xquery-function”, et voilà , secara ajaib tersedia dalam transformasi xquery lainnya.
Masalahnya adalah area ini tidak didokumentasikan (mungkin sengaja), jadi saya terjebak untuk melewati masalah ini dengan cara lain. Tidak ada cara yang baik untuk melakukan ini. Anda akan memerlukan informasi tentang internal mesin xquery dan API pribadinya.
Memperkenalkan XMLBeans
Selamat datang di forum diskusi untuk BEA XMLBeans. XMLBeans adalah teknologi baru yang keren dari BEA yang tersedia sebagai layanan host gratis di dev2dev. XMLBeans adalah inovasi teknologi yang sangat memudahkan pengembang untuk mengakses dan memanipulasi data dan dokumen XML di Java.
- Misi kami adalah membantu pengembang dapatkan tampilan berbasis objek Java yang familier dan nyaman dari data XML mereka tanpa kehilangan akses ke kekayaan struktur XML asli yang asli.
- XMLBeans didasarkan pada XML Skema dan memiliki banyak keunggulan dibandingkan solusi yang ada (seperti DOM/SAX.) Untuk mendapatkan informasi lebih lanjut dan memulai uji coba XMLBeans, ikuti tautan ini.
- Ini terlihat sangat menarik. Saya menggunakan JDOM saat ini, yang menggunakan SAX Parser untuk membangun pohon DOM. Ini sangat mudah digunakan dan saya tidak perlu berurusan dengan keduanya Penguraian DOM atau SAX.
Ada beberapa dukungan untuk XPATH di JDOM dan saya percaya itu Dukungan XQuery sedang ditambahkan. Dari FAQ, saya melihat beberapa keunggulan XMLBeans dibandingkan JDOM. Saya ingin mendapatkan klarifikasi pada beberapa poin untuk memastikan bahwa saya memahami ini benar.
- Dari FAQ, tampak bahwa seluruh pohon XML tidak disusun. Melakukan itu berarti org.w3c.Document tidak dibuat. Dan hanya bagian itu XML dimuat yang saya minta secara khusus?. Dalam hal ini, ini akan menjadi keunggulan dibandingkan JDOM untuk file XML yang sangat besar karena seluruh DOM tidak dibuat.
- Tampaknya saya dapat menggunakan kursor untuk membuat perubahan pada file XML. Maukah kamu pertimbangkan untuk menambahkan cara yang lebih langsung untuk melakukan ini menggunakan metode penyetel? Juga, saya tidak melihat kelas XMLWriter yang sesuai. Bagaimana cara menulis perubahan yang saya? buat ke file XML?
- Masalah praktisnya adalah tidak ada cara bagi saya untuk menghasilkan kode dari skema di mesin lokal saya. Jika saya tidak memiliki akses ke Internet, atau Anda situs down atau akses lambat, maka produktivitas saya terhambat. aku percaya bahwa ini karena produknya dalam versi beta dan Anda ingin dapat membuat kode perubahan/perbaikan bug di pihak Anda dan Anda akan merilis program untuk menghasilkan stoples, setelah Anda siap. Namun demikian, saya masih ingin mendapatkannya secara lokal dan terus dapatkan pembaruan. Webstart mungkin merupakan solusi yang baik.
- Prasyarat JDK 1.4 akan mencegah saya menggunakannya dalam produksi. Kita masih menggunakan JDK 1.3 dan akan melakukannya selama beberapa bulan ke depan.
Apakah ada kemungkinan ini bekerja pada JDK 1.3? Fitur 1.4 apa yang digunakan? Pertanyaan 3 dan 4 Saya serahkan ke pemasaran untuk menjawab, tetapi saya dapat membantu dengan 1 dan 2.
- XmlBeans memuat seluruh muatan XML ke dalam memori. Namun, kami tidak membuat struktur data apa pun yang mengimplementasikan DOM W3C. Kami menggunakan model berbasis kursor untuk inspeksi dan modifikasi XML yang memungkinkan kami lebih fleksibel dan performant dalam cara XML disimpan. Saat ini, seseorang bisa mendapatkan salinan semuanya atau bagian dari XML sebagai DOM. Di masa mendatang, kami juga berencana untuk mendukung DOM langsung.
- Saya tidak yakin apa yang Anda maksud dengan metode setter. Kursor hari ini tidak memiliki metode penyetel untuk mengatur teks atribut, elemen, dll. Jika XML Anda dikaitkan dengan skema, Anda dapat menggunakan operasi yang sangat diketik yang dihasilkan dari skema.
Anda dapat membuat serial XML dengan memanggil salah satu dari beberapa metode dari kelas dasar dari XmlCursor atau XmlObject (XmlTokenSource).
Metode xmlText mengembalikan XML sebagai tali. Metode newInputStream membuat serial XML sebagai byte yang disandikan sungai kecil. Metode newReader membuat serial itu sebagai aliran karakter. Dan DomNode baru metode membuat DOM.
Eric
Saya membuat sederhana (.xml & xsd). Mampu menghasilkan antarmuka. Ketika saya menulis kode Java untuk mencetak nilai, saya mendapatkan nol. Ini membuat frustrasi bcos, saya dapat melihat konten file xml, tetapi pengambil/penyetel mengembalikan nol.
Anita
Selamat datang di forum diskusi untuk BEA XMLBeans. XMLBeans itu keren teknologi baru dari BEA yang tersedia sebagai layanan host gratis di dev2dev. XMLBeans adalah inovasi teknologi yang sangat memudahkan pengembang untuk akses dan memanipulasi data dan dokumen XML di Java.
Misi kami adalah membantu pengembang dapatkan tampilan berbasis objek Java yang familier dan nyaman dari data XML mereka tanpa kehilangan akses ke kekayaan struktur XML asli yang asli.
XMLBeans
didasarkan pada XML Skema dan memiliki banyak keunggulan dibandingkan solusi yang ada (seperti DOM/SAX.) Untuk mendapatkan informasi lebih lanjut dan memulai uji coba XMLBeans, ikuti ini tautan: Jika Anda memiliki komentar, jangan ragu untuk memposting di sini secara publik, atau kirim umpan balik langsung ke xmlbeans.
Versi 11: EventSource tidak digunakan lagi?
saat ini saya sedang membahas contoh-contoh yang diberikan dengan versi baru dari Oracle CEP suite. Ketika saya membuat kelas yang mengimplementasikan EventSource, Eclipse menunjukkan kepada saya bahwa antarmuka ini (dan juga EventSender) tidak digunakan lagi. Bagaimana bisa? Apakah saya salah mengonfigurasi Eclipse atau apa yang terjadi?
Andreas
saat ini saya sedang membahas contoh-contoh yang diberikan dengan versi baru dari Oracle CEP suite. Ketika saya membuat kelas yang mengimplementasikan EventSource, Eclipse menunjukkan kepada saya > bahwa antarmuka ini (dan juga EventSender) tidak digunakan lagi.
Bagaimana bisa? Apakah saya salah mengkonfigurasi Eclipse atau apa yang terjadi? 11g adalah rilis pertama yang mengintegrasikan mesin CQL ke OCEP dan model pemrosesan CQL sedikit berbeda dengan EPL.
Secara khusus CQL mendukung gagasan tentang dua jenis umpan peristiwa aliran dan hubungan. Aliran hanya disisipkan dan umumnya digunakan untuk memfilter data yang bergerak cepat.
Hubungan mendukung penyisipan/pembaruan/penghapusan dan kueri kompleks. Untuk membedakan ini di EPN dan untuk membedakan dari konstruksi EPL, kami membuat dua API baru StreamSource/StreamSink dan RelationSource/RelationSink.
Tapi sekarang muncul pertanyaan lain. Apakah saya benar bahwa bekerja dengan CQL adalah ide yang bagus, karena ini adalah “barang baru”? Pada pandangan pertama saya tidak dapat menemukan petunjuk berharga tentang kapan harus menggunakan EPL dan kapan CQL. Karena saya berencana untuk bekerja dengan suite Anda untuk sementara waktu, saya kira masuk akal untuk memulai dengan yang terakhir, bukan?
Bersulang, Andreas Ya, CQL didasarkan pada standar ANSI yang muncul sehingga akan menjadi hal yang tepat untuk digunakan jika Anda memulai dengan 11g. EPL adalah satu-satunya pilihan di WLEVS 2.0 & OCEP 10.3 dan masih didukung di 11g dan seterusnya (tetapi tidak digunakan lagi dengan munculnya CQL). Di mana saya dapat menemukan Javadoc untuk kelas-kelas baru ini?
Martin
OK saya menemukan dokumen Java di: Saya perhatikan bahwa StreamSender tidak memiliki metode sendEvent melainkan sendInsertEvent. Apakah ini setara secara fungsional? Juga contoh dalam dokumentasi menunjukkan koleksi ArrayList yang diteruskan ke sendEvent, apakah itu sama untuk sendInsertEvent ?
Martin javadoc juga tersedia dalam IDE untuk API publik server CEP. Anda mengaksesnya seperti yang Anda lakukan untuk hal lain di IDE, misalnya dengan mengarahkan mouse ke kelas atau metode yang Anda minati.
Javadoc akan muncul setelah satu detik atau lebih melayang. Dalam aliran CQL hanya disisipkan dan relasi disisipkan/perbarui/hapus, penamaannya adalah untuk membedakan antara ini (RelationSender mewarisi dari StreamSender misalnya).
StreamSender mirip dengan EventSender, tetapi tidak identik aliran digunakan untuk pemfilteran daripada kueri ad-hoc dan ada aturan tentang apa yang dapat Anda gunakan di mana sendInsertEvent() hanya membutuhkan satu acara.
Fungsi Xquery
saya perlu tahu apakah mungkin memodifikasi file dengan fungsi xquery standar BEA dan jika memungkinkan di mana file itu? saya ingin melakukan itu karena, saya perlu melakukan perpustakaan sendiri dengan fungsi Xquery tetapi tidak mungkin melakukannya dengan file Xquery normal, maksud saya jika mungkin menambahkan fungsi sendiri ke file fungsi standar BEA bukannya aku sadar.
Cara standar untuk memperluas Xquery adalah dengan xpath khusus mungkin mereka bisa sesuai dengan kasus Anda Itu membantu tetapi saya bekerja dengan osb 10g, tetapi saya tidak dapat menemukan jalur yang muncul di dokumen untuk 11g. fungsi xpath khusus hanya tersedia dari versi osb11g
Dukungan xslt
FAQ menyatakan bahwa XSLT tidak diimplementasikan dalam produk, tetapi “mudah diintegrasikan” dengan mesin pihak ketiga. Tidak disebutkan lebih lanjut tentang integrasi XSLT yang diberikan di mana pun dalam literatur Oracle. Saya berharap integrasinya mudah, tetapi saya masih mencari informasi lebih lanjut.
Memang benar bahwa aplikasi apa pun yang menggunakan API juga dapat menggunakan mesin transformasi, tetapi saya memerlukan cara untuk melakukan transformasi yang menggunakan dokumen dalam database sebagai sumbernya. Dengan cara ini data terstruktur dalam database akan diubah menjadi dokumen XHTML.
Ekspresi XPath dalam template harus dijalankan oleh database, karena mengekstrak database terlebih dahulu ke dalam memori jelas akan menggagalkan tujuan database, yaitu untuk menyimpan dan menanyakan dokumen XML besar-besaran. Adakah yang bisa membantu saya mencapai tujuan ini?
Saya menggunakan aplikasi C++ karena Java akan terlalu mahal dalam waktu buka dan jejak memori. XSLT bukan fitur bawaan bdbxml; perpustakaan XQilla terintegrasi memiliki dukungan XSLT terbatas. Saya sarankan Anda mencoba salah satu dari berikut ini:
Coba manfaatkan bahasa XQuery untuk membuat transformasi yang Anda cari. Bahasa XQuery sangat kuat dan fleksibel, dan tergantung pada situasi Anda, itu akan terbukti sangat berguna tautkan ke pustaka XSLT dan integrasikan beberapa kombinasi keluaran yang dihasilkan XQuery sebagai masukan ke dalam template XSL Anda Itu adalah dua pilihan terbaik Anda.
![]()
![]()
![]()
![]()
![]()

Tutorial XQuery: Membangun Aplikasi Agregasi dan Pelaporan Layanan Web Berbasis XQuery
Tutorial XQuery: Membangun Aplikasi Agregasi dan Pelaporan Layanan Web Berbasis XQuery – Adopsi luas XML telah sangat mengubah cara informasi dipertukarkan di dalam dan di antara perusahaan. XML, bahasa markup berbasis teks yang dapat diperluas, menjelaskan data dengan cara yang tidak bergantung pada perangkat keras dan perangkat lunak.
Tutorial XQuery: Membangun Aplikasi Agregasi dan Pelaporan Layanan Web Berbasis XQuery

zorba-xquery – Dengan demikian, telah menjadi standar pilihan untuk semakin banyak layanan Web dan Arsitektur Berorientasi Layanan. Dengan sejumlah besar data yang diterbitkan dalam format XML oleh berbagai sumber, kebutuhan telah muncul untuk cara yang mudah dan efisien untuk mengekstraksi dan memanipulasi informasi ini. XQuery telah muncul sebagai cara yang ideal untuk mengumpulkan data dari layanan Web , database relasional, dan aplikasi lain yang menggunakan XML.
Skenario
Untuk mengilustrasikan penggunaan XQuery untuk menggabungkan data dari berbagai sumber, tutorial XQuery ini akan mencakup penggunaan data dunia nyata dari layanan Web kutipan saham, dan menggabungkan informasi tersebut dengan data perusahaan historis yang disimpan dalam database relasional dan disajikan sebagai XML.
Baca Juga : Tips untuk Mengoptimalkan XML di SQL Server
Dalam tutorial ini, data historis sedang ditingkatkan dengan data langsung tentang harga saham saat ini, yang diambil melalui panggilan layanan Web. Setelah data dikumpulkan, itu dapat disajikan dalam berbagai format. Untuk tujuan artikel ini, kami akan menggunakan Stylus Studio® untuk menampilkan data dalam HTML menggunakan XSLT .
Ada dua input XML dalam contoh ini: database relasional (RDBMS) dan layanan Web. Untuk RDBMS, Microsoft Access digunakan untuk memformat data secara otomatis ke dalam XML. Konversi ini juga dapat dilakukan oleh Wisaya Dokumen ADO-ke-XML bawaan Stylus Studio . Kutipan data hasil konversi dari RDBMS..
Hasil dari eksekusi Web service ini adalah respon SOAP yang dapat dilihat pada Gambar 3. SOAP (Simple Object Access Protocol) adalah protokol messaging yang memungkinkan aplikasi Web service untuk saling berbicara.
Ketika layanan Web diidentifikasi sebagai sumber input, Stylus Studio secara transparan memanggil layanan Web sebagai bagian dari operasi apa pun yang menggunakan sumber data tersebut.
Untuk mengekstrak dan menggabungkan data XML dari database Microsoft Access dan layanan Web, kami akan membuat model informasi umum dalam XML menggunakan Stylus Studio XML Schema Editor . Ini akan memungkinkan kami untuk lebih mudah memanipulasi hasil agregasi data untuk tujuan pelaporan.
Memisahkan presentasi dari ekstraksi data memungkinkan kami mengembangkan algoritme pelaporan secara independen, yang membuat sistem lebih mudah dirawat. Skema model informasi umum yang digunakan untuk hasil data stok digambarkan.
Menulis solusi di XQuery
Karena XQuery dirancang untuk memproses XML, ini adalah pilihan logis untuk skenario ini. Selain itu, XQuery dengan mudah mendukung gagasan “gabungan”, yang memungkinkan dua atau lebih sumber data digabungkan berdasarkan kondisi kueri. Pilihan bahasa lainnya termasuk:
Menggunakan bahasa tingkat tinggi seperti Java dan melakukan penguraian dan manipulasi data menggunakan JDOM Menggunakan XSLT
Perbedaan utama adalah bahwa dengan XSLT, logika gabungan dicapai dengan menyimpan simbol stok dalam variabel di loop luar saat memproses informasi stock-ticker SOAP, dan kemudian di loop dalam menguji variabel itu dalam “xsl:if” terhadap setiap elemen stok dari data stok historis. Ketika “xsl:if” bernilai true, Annual Revenues dan City akan ditampilkan.
Untuk solusi XQuery, pertama-tama kita buat produk silang elemen dari dua file XML, lalu batasi hasilnya dengan mengembalikan hanya item tersebut dari database Access dan sumber SOAP yang cocok. Program lengkapnya ditunjukkan di bawah ini:
Deklarasi ini diperlukan karena permintaan SOAP berisi dua ruang nama yang berbeda: satu yang menjelaskan struktur pesan, dan satu yang menjelaskan muatan pesan yang, dalam hal ini, adalah informasi stok real-time. Dua ruang nama XML mencegah konflik penamaan.
Elemen yang mengacu pada komponen SOAP dari pesan diakses dengan awalan “soap:” (/soap:Envelope/soap:Body), sedangkan elemen yang merupakan bagian dari pesan tertanam yang ditransfer sebagai bagian dari respons layanan Web digunakan awalan “a:” ($Quote/a:StockTicker).
Dua baris berikutnya memberikan petunjuk tentang bagaimana program akan beroperasi:
<Hasil>
{
Ketika XQuery mulai dijalankan, ia membangun pohon XML yang dimulai dengan elemen <Result>. Kurung berlekuk-lekuk “{” yang mengikuti adalah awal dari blok pemrosesan yang, ketika selesai, akan memiliki output yang ditambahkan ke pohon XML.
Sebagian besar pemrosesan program terjadi di loop “untuk/di mana”. untuk $Quote di /soap:Envelope/soap:Body/a:GetStockQuotesResponse/a:GetStockQuotesResult/a:Quote,
$Report2003 in document(“Report2003.xml”)/dataroot/Report2003
di mana $Quote/a:StockTicker = $Report2003 /Simbol
Loop “for” mengulangi pesan SOAP melalui elemen berulang “a:Quote”. Setiap kali melalui loop, ia menetapkan elemen “a:Quote” ke variabel “$Quote”.
Demikian pula, untuk setiap elemen berulang “Report2003” dari file “Report2003.xml”, program menetapkan elemen ke $Report2003. Setiap kali melalui loop, klausa “where” dijalankan dan ketika bernilai true, klausa tersebut memungkinkan baris XQuery berikutnya berjalan.
Perhatikan bahwa prosesor XQuery dalam banyak kasus dapat mengoptimalkan eksekusi XQuery seperti ini. Misalnya, ia dapat mengambil hasil dari $Quotevariabel ” dan menggunakannya untuk membaca lebih optimal dari Report2003.xmldokumen “, membuat atau menggunakan indeks yang ada jika perlu.
Prosesor XQuery juga dapat membaca Report2003.xmldokumen ” hanya sekali dan membuat tabel hash dalam memori dari struktur tersebut sehingga selama iterasi berikutnya melalui loop, $Quote/a:StockTicker $Report2003/Symbolperbandingan” dapat dilakukan dengan sangat efisien.
Di sini, pohon hasil XML sedang dibangun sebagai bagian dari operasi pengembalian, dengan <CompanyData>di tingkat atas, dan <Name of Company>sebagai sub-elemen bersarang. Nilai yang dievaluasi oleh kueri didefinisikan dalam tanda kurung berlekuk.
Perhatikan bahwa Anda harus menentukan tipe data yang akan diambil [di sini, ini adalah “teks ()”]; jika tidak, XQuery hanya menyalin elemen “$Report2003/Company” dan bukan konten ke pohon hasil XML tujuan.
Sebagai bagian dari debugger XSLT Stylus Studio®, hasil antara pengembalian tersedia di jendela “Variabel” produk. Ini sangat membantu untuk mengembangkan program XQuery karena, tidak seperti bahasa seperti XSLT, output tidak langsung dihasilkan. Oleh karena itu, alat ini memungkinkan untuk melihat status perantara dengan cepat selama eksekusi.
Mencapai hasil
Ketika XQuery dijalankan dalam Stylus Studio®, pohon hasil XML dikeluarkan ke Jendela Pratinjau Stylus. Dari sana, menyortir hasil menurut elemen apa pun dari input dapat bermanfaat, dan membuat ekstensi untuk mencapainya adalah hal yang mudah.
Untuk mengurutkan hasil dalam urutan abjad berdasarkan nama perusahaan, misalnya, cukup masukkan pernyataan “pesan berdasarkan” setelah “di mana” dalam loop “untuk/biarkan/di mana/kembali”. Kami kemudian dapat mengurutkan output berdasarkan nama perusahaan dengan loop berikut:
untuk $Quote di
/soap:Envelope/soap:Body/a:GetStockQuotesResponse/a:GetStockQuotesResult/a:Quote,
$Report2003 in document(“Report2003.xml”)/dataroot/Report2003
di mana $Quote/a:StockTicker = $Report2003 /Simbol
pesanan dengan $Quote/a:CompanyName
kembali
Sementara kode untuk menghasilkan XQuery di atas cukup mudah untuk ditulis, Stylus Studio menyediakan alat pemetaan yang menyederhanakan pembuatan peta dasar.
Membangun XQuery seperti yang ditunjukkan dalam artikel ini dapat diselesaikan dalam waktu kurang dari satu menit menggunakan alat pemetaan ini.
Representasi visual dari XQuery terlihat pada Gambar 5. Loop “for/let/where” dibangun dengan menyeret elemen berulang ke ikon FLWOR (di mana klausa “for” diimplementasikan); klausa “di mana” diimplementasikan dengan membuat ikon “sama” dan menyeret elemen untuk kedua sisi “sama” ke ikon itu.
Loop “for/let/where” diselesaikan dengan mengaitkan “equal” ke FLWOR dan kemudian menyeret output ekspresi FLWOR ke elemen berulang dari dokumen target. Setelah membuat struktur loop “for/let/where”, elemen dari skema sumber dapat dengan mudah diseret dan dijatuhkan ke skema target.
Melaporkan ke HTML menggunakan XSLT
Setelah model informasi umum berbasis XML diisi, ada banyak pilihan untuk menyajikan informasi tersebut kepada pengguna. Untuk melengkapi contoh ini, kami akan membuat lembar gaya menggunakan perancang XML-ke-HTML WYSIWYG Stylus Studio untuk menyajikan data sebagai HTML.
Pilihan lain termasuk menggunakan alat pelaporan seperti Crystal Reports, atau memproses XML dengan bahasa lain seperti Visual Basic atau Java dan kemudian menulis laporan kustom dari itu. Pilihan lain, tentu saja, hanya menggunakan XQuery untuk menghasilkan HTML.
Ringkasan
Dalam tutorial XQuery ini, kami mempelajari bahwa layanan Web menyediakan banyak informasi baru yang dijelaskan dan tersedia untuk aplikasi dalam XML. Seringkali, analisis data memerlukan informasi dari berbagai sumber, yang berarti bahwa data layanan Web, misalnya, perlu ditingkatkan atau digabungkan dengan data XML yang diperoleh dari sumber data lain.
Menggunakan Stylus Studio®, kami membuktikannya dengan cepat dan mudah untuk membuat XQuery yang secara efisien mengumpulkan data dari data stok historis yang disimpan dalam database relasional dengan data kuotasi stok langsung yang disediakan dari layanan Web. Model informasi umum digunakan untuk target agregasi, dan hasilnya diterjemahkan ke dalam HTML untuk tujuan presentasi.
![]()
![]()
![]()
![]()
![]()
Tips untuk Mengoptimalkan XML di SQL Server
Tips untuk Mengoptimalkan XML di SQL Server – Saya telah mengerjakan proyek yang banyak menggunakan XML di dalam SQL Server. Kami benar-benar memanfaatkan dukungan XML SQL Server hampir sepenuhnya, tetapi dengan beberapa dampak.
Tips untuk Mengopti malkan XML di SQL Server

zorba-xquery – Saat kami melakukan pengujian beban, kinerja menurun dan kami harus mundur dan menyesuaikan cara kami menggunakan data XML kami.
Baca Juga : Mengembangkan Sistem Kueri Yang Efisien Untuk Dokumen XML
Jika Anda menggunakan XML dalam database Anda, Anda mungkin ingin mempertimbangkan beberapa tips ini untuk mengoptimalkan keseluruhan kueri dan kinerja yang terkait dengan data XML Anda.
1. Promosikan elemen dan atribut yang sering digunakan ke dalam kolom relasional
Jika Anda mendapati diri Anda selalu menarik nilai skalar dari kolom XML Anda untuk bergabung ke tabel lain, Anda harus mempertimbangkan untuk “mempromosikan” nilai ini ke dalam kolom.
- Pro: Nilai ini sekarang dapat diindeks, sehingga dapat meningkatkan kinerja kueri Anda.
- Con: Ini adalah overhead manajemen tambahan. Jika Anda perlu mengubah nilai dalam dokumen XML, Anda juga perlu mengubah nilai di kolom relasional Anda. Anda dapat mempertimbangkan untuk melakukan ini di tingkat aplikasi (yaitu mengubah nilai di kedua tempat sekaligus), atau membuat kolom kalkulasi tetap yang menggunakan UDF yang mengekstrak nilai skalar untuk Anda, atau bahkan memicu (hati-hati! pastikan Anda menguji sebelum Anda menerapkan dalam produksi).
2. Tambahkan skema ke kolom XML Anda
XML sebenarnya hanyalah sebuah dokumen teks. Ini menimbulkan overhead ke SQL Server karena setiap kali Anda melakukan operasi, SQL Server perlu “menebak” tipe data mana yang mungkin sesuai untuk operasi Anda sebelum melakukan konversi implisit. Anda dapat menghilangkan langkah ini dengan membuat kolom XML yang diketik, atau XML yang terikat ke skema (XSD).
- Pro: Memproses XML Anda akan lebih cepat daripada jika Anda menggunakan XML yang tidak diketik. Ini menghilangkan pekerjaan tebakan tipe data dari SQL Server.
- Con: Ini dapat membuat overhead manajemen. XML Anda sekarang tiba-tiba menjadi tidak fleksibel lagi. Setiap kali Anda perlu menambahkan elemen atau atribut baru atau fragmen bersarang baru, Anda harus MENGUBAH skema terlebih dahulu sebelum Anda dapat membuat perubahan. Perubahan ini mungkin perlu diturunkan ke semua prosedur tersimpan Anda yang menggunakan kolom ini.
3. Gunakan Indeks XML
Anda harus terlebih dahulu membuat indeks XML Primer, kemudian membuat indeks sekunder.
Contoh indeks XML utama
BUAT INDEKS XML UTAMA invoiceidx
AKTIF [Penjualan].[salesxml](xmlcontent)
PERGILAH
Ada 3 indeks XML sekunder utama:
PATH Sekunder XML Indeks berguna jika Anda menggunakan jalur, dan jika Anda tidak memiliki wildcard
PILIH
xmlcontent.value(‘(penjualan/pesanan[@ord_num=”6871″])[1]’, ‘varchar(20)’) ,
kolom lainnya
DARI
[Penjualan].[salesxml]
DI MANA
xmlcontent.exist(‘(penjualan/pesanan[@ord_num=”6871″])’) =1
PROPERTI Indeks XML Sekunder berguna jika mencari beberapa properti, tetapi mungkin tidak memiliki path lengkap
Sampel
PILIH
kolom lainnya
DARI
[Penjualan].[salesxml]
DI MANA
xmlcontent.exist(‘(//title_id)’) = 1
VALUE Indeks XML Sekunder berguna jika Anda mengetahui nilai pasti yang dicari, tetapi mungkin tidak memiliki jalur lengkap
PILIH
kolom lainnya
DARI
[Penjualan].[salesxml]
DI MANA
xmlcontent.exist(‘/sales/order[@ord_num=”6871″]/text()[. = “Sesuatu”]’) = 1
PILIH
kolom lainnya
DARI
[Penjualan].[salesxml]
DI MANA
xmlcontent.exist(‘(//title_id/@*[. = “khusus”])’) = 1
- Pro: Seperti halnya indeks biasa, pencarian lebih cepat.
- Con: Seperti halnya indeks biasa, menempati lebih banyak penyimpanan, dan membutuhkan lebih banyak sumber daya yang diperlukan untuk memproses ulang indeks Anda.
4. Membuat ulang XML pada Pembaruan Massal
Pernah ingin memperbarui properti elemen atau atribut secara massal di XML Anda? Tergoda untuk menggunakan dukungan SQL Server untuk XQuery? Sayangnya dalam kasus saya, untuk beberapa pembaruan yang perlu saya lakukan, XQuery tidak memotongnya.
Metode .modify() kolom atau variabel XML Anda terbatas hanya untuk memperbarui instance XML tersebut. Jika Anda ingin menggunakan XQuery .modify() untuk memperbarui lebih dari satu item, Anda harus mengulang semua instance XML dan memanggil .modify() untuk masing-masing item.
Alternatif yang mungkin, tergantung pada seberapa besar data XML Anda, adalah membuat ulang XML. Jika data yang Anda perlukan untuk XML sudah ada di kolom lain yang ada, Anda bisa melakukan kueri dengan FOR XML PATH dan menyertakan nilai baru. Gunakan dengan hati-hati. Ini berhasil untuk tujuan saya, jarak tempuh Anda mungkin berbeda.
- Pro: Bisa lebih cepat. YMMV.
- Con: Ini membutuhkan sedikit lebih banyak pengkodean, dan merakit ulang XML Anda.
![]()
![]()
![]()
![]()
![]()

Mengembangkan Sistem Kueri Yang Efisien Untuk Dokumen XML
Mengembangkan Sistem Kueri Yang Efisien Untuk Dokumen XML – XQuery adalah query dan bahasa pemrograman fungsional yang dirancang untuk query data dalam dokumen XML. Makalah ini membahas cara efisien mengkueri dokumen XML terenkripsi menggunakan XQuery, dengan poin kuncinya bagaimana menghilangkan dekripsi yang berlebihan sehingga mempercepat proses kueri.
Mengembangkan Sistem Kueri Yang Efisien Untuk Dokumen XML

zorba-xquery – Kami mengusulkan model yang dapat diterjemahkan secara otomatis pernyataan XQuery untuk dokumen XML terenkripsi. Implementasi dan hasil eksperimen menunjukkan kepraktisan model yang diusulkan.
Menyorot
Kami mengusulkan skema untuk kueri dokumen XML terenkripsi yang efisien. Skema kami menghilangkan dekripsi yang berlebihan untuk mempercepat proses kueri. Algoritma yang digunakan untuk mengubah program XQuery menunjukkan kinerja yang baik.
Pengantar
Bahasa XQuery (Boag et al., 2007) adalah teknologi dari W3C yang dirancang untuk dapat diterapkan secara luas di semua jenis sumber data XML. Ini menyediakan fungsionalitas kueri yang fleksibel untuk mengekstrak data dari dokumen nyata dan virtual dengan cepat atau dalam database. XQuery menggunakan model data XML yang dapat mewakili dokumen XML, urutan, atau elemen atom seperti bilangan bulat atau string. Spesifikasi XQuery menentukan model yang menentukan yang menentukan bahwa prosesor XQuery berinteraksi dengan dan langkah apa yang harus diambil untuk menemukan kueri. Program XQuery mencakup navigasi dalam dokumen XML menggunakan XPath (Clark dan DeRose, 1999), pernyataan database (yang disebut ekspresi FLWOR), konstruksi elemen XML baru, operasi pada tipe Skema XML, dan pemanggilan fungsi.
W3C Lebih dari 50 implementasi XQuery . Misalnya, Galax adalah implementasi XQuery 1.0 yang ringan dan dapat diperluas yang melacak dengan cermat definisi XQuery 1.0 seperti yang ditentukan oleh W3C, yang berarti ia juga mengimplementasikan XPath 2.0 (bagian dari XQuery 1.0). Qexo adalah implementasi parsial dari bahasa XQuery yang menunjukkan kinerja yang baik karena kueri dikompilasi ke kode byte Java menggunakan kerangka Kawa. Sedna, yang didasarkan pada toko XML asli, mengimplementasikan arsitektur yang berlapis standar menggunakan dinamis antara eksekusi berbasis tarik dan dorong saat run-time. Zorba adalah prosesor XQuery sumber terbuka yang dirancang untuk dapat disebarluaskan di berbagai lingkungan, seperti bahasa pemrograman lain yang diperluas dengan kemampuan menawarkan XML, browser, server basis data, pengirim pesan XML,
XML berguna karena mengurangi biaya dengan meningkatkan fleksibilitas manajemen data dalam berbagai cara. XML adalah platform-independen dan berdasarkan Unicode, yang berarti mendukung semua bahasa dan abjad. Format XML menjadi pengkodean data yang tersebar luas untuk aplikasi dan layanan Web, yang membuatnya semakin penting untuk menjaga keakuratan informasi yang direpresentasikan dalam dokumen XML. Misalnya, kita mungkin perlu dan mengenkripsi dokumen XML untuk memastikan tidak ada keharusan dan kerahasiaan (Schneier, 1995). enkripsi elemen-bijaksana XML (Maruyama dan Imamura, 2000), kelompok kerja enkripsi XML dari W3C (Enkripsi XML, 2001) berdasarkan spesifikasi rekomendasi untuk enkripsi XML (Imamura et al., 2002). Dokumen terenkripsi menentukan proses untuk mengenkripsi data dan mewakili hasilnya dalam XML. Data terenkripsi dapat berupa data arbitrer, elemen XML, atau konten elemen XML. Gambar 2 mengilustrasikan konsep enkripsi elemen-bijaksana. Gambar 2(A) menunjukkan informasi pembayaran Tony Chen. Nomor kredit Chen sensitif dan harus dijaga kerahasiaannya. Seluruhnya “Elemen CreditCard” dienkripsi dan ditunjukkan pada Gambar. 2(B). Gambar 2(C) menyatakan bahwa “Kartu Kredit” dan “Nomor” dalam keadaan kosong, tetapi isi data karakter “Nomor” dienkripsi. Ini memungkinkan file XML dilindungi karena data sensitif dalam XML dienkripsi dengan kunci tertentu. Elemen CreditCard” dienkripsi dan ditunjukkan pada Gambar. 2 (B). Gambar 2(C) menyatakan bahwa “Kartu Kredit” dan “Nomor” dalam keadaan kosong, tetapi berisi data karakter “Nomor” dienkripsi. Ini mendukung file XML yang dilindungi karena data sensitif dalam XML dienkripsi dengan kunci tertentu. Elemen CreditCard” dienkripsi dan ditunjukkan pada Gambar. 2 (B). Gambar 2(C) menyatakan bahwa “Kartu Kredit” dan “Nomor” dalam keadaan kosong, tetapi berisi data karakter “Nomor” dienkripsi. Ini mendukung file XML yang dilindungi karena data sensitif dalam XML dienkripsi dengan kunci tertentu.
Makalah ini membahas cara meminta data dari dokumen XML terenkripsi ini dengan XQuery. Cara yang mudah dan intuitif adalah pertama-tama mendekripsi seluruh dokumen XML terenkripsi dan kemudian menggunakan program XQuery untuk mendapatkan dokumen yang diinginkan (lihat Gambar 3). Kelemahan dari pendekatan ini adalah tidak efisien dalam situasi tertentu karena semua elemen terenkripsi dalam dokumen XML yang harus didekripsi. Menurut semantik operasionalnya, XQuery biasanya digunakan untuk mendapatkan elemen kecil dari dokumen XML target. Secara teoritis tidak perlu mendekripsi semua elemen terenkripsi dalam dokumen XML target kita hanya perlu mendekripsi elemen-elemen yang termasuk dalam elemen hasil dari kueri yang dikeluarkan.
Baca Juga : 7 Faktor yang Perlu Diperhatikan Dalam Prosesor (CPU)
Tujuan pertama adalah untuk menghilangkan dekripsi yang tidak perlu. Menurut spesifikasi enkripsi W3C XML (Imamura et al., 2002), cakupan dapat berupa “elemen”, yang mengenkripsi seluruh elemen (termasuk tag awal/akhir), atau “konten”, yang mengenkripsi elemen konten (antara tag awal/akhir) . Perhatikan dokumen XML yang ditunjukkan pada Gambar 4. Elemen “pembayar” dan “cardinfo” dienkripsi secara keseluruhan; yaitu, Cakupan enkripsi mereka diatur ke “elemen”. Dalam dokumen XML terenkripsi yang ditunjukkan pada Gambar. 5, elemen ” CipherData ” berisi data terenkripsi dari ” pembayar ” dan ” cardinfo”, dan dibungkus oleh elemen “ EncryptedData ”. Perhatikan bahwa nama tag dari elemen “ pembayar ” dan “ cardinfo ” menghilang. Gambar 5 menunjukkan bahwa setelah cakupan suatu elemen diatur ke “elemen”, nama tagnya tidak dapat diperiksa kecuali kita mendekripsi elemen tersebut terlebih dahulu. Jenis cakupan enkripsi sangat membantu untuk keamanan data karena tidak ada petunjuk tentang elemen mana yang dienkripsi. Gbr. 6 daftar program XQuery yang digunakan untuk mendapatkan nilai dari “cardinfo”element ” dari Gambar 4. Jelas bahwa kita tidak dapat menggunakan program ini untuk menanyakan dokumen terenkripsi yang ditunjukkan pada Gambar 5; kita harus mendekripsi dua elemen terenkripsi sebelum melakukan kueri. Namun, karena kami hanya ingin menanyakan salah satunya, dekripsi lainnya tidak diperlukan. Jenis cakupan enkripsi sangat membantu untuk keamanan data karena tidak ada petunjuk tentang elemen mana yang dienkripsi. Gbr. 6 daftar program XQuery yang digunakan untuk mendapatkan nilai dari “cardinfo”element ” dari Gambar 4. Jelas bahwa kita tidak dapat menggunakan program ini untuk menanyakan dokumen terenkripsi yang ditunjukkan pada Gambar 5; kita harus mendekripsi dua elemen terenkripsi sebelum melakukan kueri. Namun, karena kami hanya ingin menanyakan salah satunya, dekripsi lainnya tidak diperlukan. Jenis cakupan enkripsi sangat membantu untuk keamanan data karena tidak ada petunjuk tentang elemen mana yang dienkripsi. Gbr. 6 daftar program XQuery yang digunakan untuk mendapatkan nilai dari “cardinfo”element ” dari Gambar 4. Jelas bahwa kita tidak dapat menggunakan program ini untuk menanyakan dokumen terenkripsi yang ditunjukkan pada Gambar 5; kita harus mendekripsi dua elemen terenkripsi sebelum melakukan kueri. Namun, karena kami hanya ingin menanyakan salah satunya, dekripsi lainnya tidak diperlukan. kita harus mendekripsi dua elemen terenkripsi sebelum melakukan kueri. Namun, karena kami hanya ingin menanyakan salah satunya, dekripsi lainnya tidak diperlukan. kita harus mendekripsi dua elemen terenkripsi sebelum melakukan kueri. Namun, karena kami hanya ingin menanyakan salah satunya, dekripsi lainnya tidak diperlukan.
Beberapa peneliti telah mengerjakan kueri atas dokumen XML terenkripsi (Schrefl et al., 2005, Yang et al., 2006, Wang dan Lakshmanan, 2006, Lee dan Whang, 2006). Misalnya, Schrefl dkk. (2005) mengusulkan teknik untuk memproses kueri dan dokumen XML terenkripsi yang disimpan di server yang tidak dapat dipercaya. Dengan melakukan enkripsi dan dekripsi hanya pada klien tetapi tidak pada server, ini menjamin bahwa baik struktur dokumen maupun konten dokumen tidak di server. Yang dkk. (2006) mengusulkan XQEnc teknik enkripsi XML menggunakan vektorisasi dan kompresi kerangka. Pendekatan ini menyimpan skema dokumen XML sebagai kerangka terkompresi pada klien dan sangat efisien karena hanya mengambil data yang diperlukan klien untuk mendekripsi. Wang dan Lakshmanan (2006) mengusulkan mekanisme metadata termasuk indeks struktural dan nilai di server sisi yang mendukung evaluasi kueri yang efisien. Lee dan Whang (2006) mengusulkan gagasan Query-Aware Decryption. Pendekatan ini menyebarkan indeks XML terenkripsi bersama dengan data XML terenkripsi. Indeks ini akan informasi di mana hasil kueri berada dalam data XML terenkripsi; sehingga mencegah melakukan dekripsi yang tidak perlu di bagian lain dari data.
Untuk meningkatkan efisiensi dekripsi dokumen XML terenkripsi dalam proses kueri, kita harus menghindari melakukan dekripsi yang tidak perlu. Untuk contoh yang ditunjukkan pada Gambar. 4, Gambar. 5, Gambar. 6, menjelaskan bahwa beberapa informasi tambahan yang diperlukan untuk menghilangkan dekripsi yang berlebihan karena enkripsi dapat merusak struktur dokumen XML. kadang-kadang informasi struktur harus selama kueri. Dalam makalah ini, kami menyajikan jenis informasi yang diperlukan untuk menghilangkan dekripsi yang berlebihan dan mengusulkan model untuk diterjemahkan secara otomatis menerjemahkan program XQuery yang ditulis oleh pengguna ke program lain yang secara akurat menemukan elemen target yang harus didekripsi. Algoritme terjemahan yang disajikan optimal dalam hal perhitungan yang diperlukan untuk dekripsi.
Model Pemrosesan Untuk Menanyakan Dokumen XML Terenkripsi
Mengkueri dokumen XML terenkripsi secara optimal di XQuery memerlukan informasi tentang keamanan. Perhatikan bahwa kueri optimal didefinisikan sebagai kueri yang memerlukan dekripsi minimal untuk elemen terenkripsi dalam dokumen XML target. Secara umum, standar enkripsi dan tanda tangan yang diusulkan oleh W3C menawarkan definisi lengkap format untuk dokumen XML terenkripsi (Imamura et al., 2002, Bartel et al., 2008). Namun, bahasa tersebut tidak cukup kuat bagi programmer untuk menentukan caranya
Algoritma Transformasi XQuery Untuk Menanyakan Dokumen XML Terenkripsi
Sekarang kami menyajikan desain algoritma yang digunakan untuk mengubah program XQuery; yaitu, desain penerjemah yang ditunjukkan pada Gambar 8. Kita mulai dengan mempertimbangkan sintaks dari pernyataan XQuery. Setiap program XQuery berisi satu atau lebih ekspresi kueri. Ekspresi FLWOR adalah ekspresi XQuery yang paling kuat dan, dalam banyak hal, mirip dengan pernyataan SELECT-FROM-WHERE yang digunakan dalam SQL (ISO, 1999). Tata bahasa formal untuk ekspresi FLWOR di XQuery didefinisikan dalam (Boag et
Implementasi Dan Hasil Eksperimen
Kami menggunakan Saxon sebagai prosesor XQuery untuk menjalankan program XQuery. Saxon langsung mengkompilasi program XQuery ke dalam pohon operator dan melakukan transformasi dan optimasi tingkat lanjut pada pohon operator. Menurut model pemrosesan yang ditunjukkan pada Gambar. 8, kami mengimplementasikan penerjemah yang memungkinkan program XQuery yang ditulis oleh pengguna untuk meminta data dari dokumen XML terenkripsi sesuai dengan algoritma yang tercantum pada Gambar 9. Kami juga mengimplementasikan objek ekstensi untuk melakukan proses dekripsi.
Kesimpulan
Makalah ini berfokus pada pengembangan model untuk kueri dokumen XML terenkripsi secara efisien menggunakan XQuery. Model ini memerlukan dokumen tertentu untuk kueri yang efisien, termasuk DSL yang menentukan cara mengenkripsi dokumen XML dan Skema XML dari dokumen XML asli. Model ini mendukung kueri dokumen XML terenkripsi yang efisien, dalam hal perhitungan yang diperlukan untuk dekripsi selama proses kueri. Hasil eksperimen disajikan di sini
Tao-Ku Chang adalah asisten profesor di Departemen Ilmu Komputer dan Informasi di Universitas Nasional Dong Hwa. Ia menerima gelar Ph.D. gelar saat di Graduate Institute of Information and Computer Education di National Taiwan Normal University, Taipei, Taiwan, pada tahun 1998. Minat penelitiannya meliputi SOA, masalah terkait XML, keamanan Internet, dan teknologi berorientasi objek.
![]()
![]()
![]()
![]()
![]()

7 Faktor yang Perlu Diperhatikan Dalam Prosesor (CPU)
7 Faktor yang Perlu Diperhatikan Dalam Prosesor (CPU) – Jika Anda berada di pasar untuk komputer baru dan berencana membangun sistem Anda sendiri, komponen yang mungkin akan Anda pilih pertama adalah prosesor (CPU).
7 Faktor yang Perlu Diperhatikan Dalam Prosesor (CPU)

zorba-xquery – Namun, jika Anda baru membuat komputer, apa yang harus dicari dalam CPU mungkin tidak jelas bagi Anda. Dalam artikel ini, saya membahas tujuh faktor berbeda yang harus Anda pertimbangkan agar Anda dapat membeli prosesor terbaik untuk anggaran dan kebutuhan Anda.
Daftar isi
- Bagaimana Anda Akan Menggunakan Komputer Anda?
- Berapa Banyak yang Harus Anda Keluarkan?
- Intel vs. AMD
- Apakah Anda Ingin Overclock?
- Mencocokkan CPU Anda Dengan Soket yang Tepat
- Dapatkan Chipset Motherboard yang Tepat
- Dapatkan Pendingin CPU yang Tepat
1. Bagaimana Anda Akan Menggunakan Komputer Anda?
Jika Anda ingin membeli/membangun komputer atau laptop baru dan Anda bertanya-tanya CPU apa yang harus Anda dapatkan, pertama-tama Anda harus mempertimbangkan untuk apa sebenarnya komputer Anda akan digunakan.
Baca Juga : Cara Mengeksekusi dan Menjalankan Kode Java dari Terminal
Jika Anda sedang mencari komputer baru yang dapat Anda gunakan untuk menjelajah internet, mengirim email, atau menonton video, Anda tidak memerlukan komputer yang kuat seperti jika Anda ingin bermain game yang menuntut, atau menggunakan sistem Anda sebagai sebuah stasiun kerja.
Atau, jika Anda seorang gamer, tetapi Anda hanya memainkan game yang tidak menuntut seperti League of Legends, Anda dapat menghemat sedikit uang dengan mendapatkan prosesor quad-core yang lebih hemat anggaran, dan kemudian mengantongi uang ekstra, atau menggunakannya untuk dimasukkan ke dalam komponen lain.
Jika Anda ingin membuat komputer kelas atas untuk mengedit video, pekerjaan desain grafis, atau untuk memainkan game yang menuntut seperti Assassin’s Creed dan Call of Duty , Anda pasti ingin mencari prosesor kelas atas dengan lebih banyak inti/utas .
Sementara banyak game masih belum sepenuhnya menggunakan banyak inti dan hyperthreading, setiap generasi semakin banyak game yang dikembangkan untuk memanfaatkan teknologi tersebut.
Dan, untuk desain grafis, pengeditan video, dan kasus penggunaan terkait lainnya, inti/utas tambahan akan memberi Anda lebih banyak kinerja. Namun, pada akhirnya, hal pertama yang ingin Anda pertimbangkan saat membeli CPU baru adalah untuk apa sebenarnya Anda akan menggunakan sistem Anda.
2. Berapa Banyak Yang Harus Anda Keluarkan?
Salah satu faktor yang akan menjadi faktor penentu paling signifikan dalam jenis prosesor apa yang bisa Anda dapatkan adalah berapa banyak uang yang harus Anda keluarkan.
Baik Anda sedang membangun komputer atau membeli yang sudah jadi, semakin banyak uang yang harus Anda keluarkan, semakin baik prosesor yang bisa Anda dapatkan.
Namun, bahkan jika Anda memiliki banyak uang untuk dibelanjakan, itu tidak berarti Anda harus mendapatkan prosesor terbaik yang bisa dibeli dengan uang. Seperti yang kami sebutkan di atas, bagaimana Anda akan menggunakan sistem Anda juga penting untuk dipertimbangkan.
Sekali lagi, jika Anda hanya ingin membuat atau membeli komputer untuk penggunaan ringan (browsing internet, mengirim email, dll.), Anda tidak perlu menghabiskan banyak uang untuk mendapatkan mesin yang akan melakukan apa yang Anda inginkan. untuk.
Dan, jika Anda seorang gamer yang ingin memainkan game yang lebih menuntut, Anda akan ingin menghabiskan setidaknya jumlah sedang untuk prosesor Anda.
Meskipun memiliki prosesor kelas atas bagus untuk bermain game, kenyataannya adalah mengalokasikan lebih banyak uang untuk GPU yang lebih kuat akan memberikan hasil dalam game yang lebih baik. (Lihat panduan kami tentang berapa biaya untuk membangun PC gaming .) Untuk bermain game, CPU Anda tidak akan berdampak besar pada kinerja dalam game seperti halnya GPU Anda.
Jadi, jika Anda tidak memiliki anggaran tak terbatas, pastikan Anda menemukan keseimbangan antara CPU dan GPU yang Anda pilih, karena Di sisi lain, jika Anda ingin mengedit video atau melakukan pekerjaan desain, atau Anda bermain game yang lebih banyak menggunakan CPU , maka Anda akan ingin menghabiskan lebih banyak uang untuk prosesor Anda.
3. Intel vs. AMD
Jika Anda telah meneliti komponen mana yang harus dipilih untuk komputer game Anda, maka Anda pasti telah menemukan lebih dari satu artikel yang mengadu prosesor Intel versus prosesor AMD.
Intinya adalah bahwa hanya ada dua pilihan yang Anda miliki untuk CPU jika Anda berada di pasar untuk membangun atau membeli komputer baru: Intel atau AMD. Setiap produsen CPU membawa sesuatu yang berbeda ke meja.
Intel biasanya menawarkan CPU yang memberikan kinerja dan efisiensi inti tunggal yang lebih baik. Sampai sekarang, ini diterjemahkan ke dalam kinerja game yang lebih baik secara keseluruhan. AMD, di sisi lain, biasanya menawarkan CPU yang memiliki lebih banyak core.
Dan, sementara kinerja inti tunggal mereka tidak cukup sesuai dengan kinerja inti tunggal Intel, chip AMD, pada kenyataannya, mempersempit kesenjangan kinerja dengan memasang lebih banyak inti ke dalam chip mereka.
Mengenai kinerja game, dalam kebanyakan skenario, prosesor Intel memiliki sedikit keunggulan dibandingkan prosesor AMD. Namun, dalam situasi dunia nyata, perbedaan kinerja dalam game antara prosesor terbaru dari AMD dan Intel cukup tipis.
Pada akhirnya, meskipun ada banyak sudut berbeda dalam pertempuran antara Intel dan AMD untuk supremasi CPU game, intinya adalah kedua produsen prosesor menghadirkan CPU yang lebih dari cukup kuat untuk menangani game saat ini.
Jadi, apakah keputusan Anda tergantung pada harga, kinerja, atau sedikit dari keduanya, kedua perusahaan memiliki sesuatu untuk ditawarkan.
4. Apakah Anda Ingin Overclock?
Hal lain yang ingin Anda pertimbangkan jika Anda mencari prosesor yang tepat untuk kebutuhan Anda adalah apakah Anda ingin memiliki kemampuan untuk melakukan overclock atau tidak. Overclocking memungkinkan Anda untuk “meningkatkan” kecepatan pada prosesor Anda, yang dapat membantu Anda mendapatkan lebih banyak kinerja.
Untuk sebagian besar pengguna, overclocking tidak diperlukan. Namun, jika Anda ingin membuat komputer gaming baru, atau Anda sedang melakukan pekerjaan bertipe desain grafis, terkadang semakin banyak kekuatan pemrosesan yang Anda dapatkan, semakin baik.
Prosesor yang dapat di-overclock juga berpotensi untuk tetap relevan lebih lama. Jadi, jika Anda bekerja dengan anggaran yang lebih kecil hingga menengah dan Anda tidak ingin meningkatkan prosesor Anda dalam 3-4 tahun, memilih CPU yang dapat dibuka kuncinya mungkin merupakan cara yang baik. Jika Anda ingin melakukan overclock, perhatikan bahwa Anda harus mengeluarkan lebih banyak uang untuk mendapatkan hasil maksimal dari upaya overclocking Anda.
Misalnya, CPU “tidak terkunci” (CPU yang dapat di-overclock) biasanya lebih mahal daripada CPU “terkunci” (CPU yang tidak dapat di overclock.) CPU yang tidak terkunci juga biasanya membutuhkan motherboard dan pendingin CPU yang lebih mahal untuk mengakomodasinya.
Jadi, jika Anda ingin membuat PC gaming murah , overclocking mungkin bukan pilihan yang tepat untuk Anda. Namun, jika Anda memiliki anggaran yang lebih besar dan Anda ingin memiliki kemampuan untuk meng-overclock prosesor Anda, pastikan Anda memilih motherboard dan pendingin CPU yang akan mengakomodasi prosesor Anda.
5. Mencocokkan CPU Anda Dengan Soket yang Tepat
Jika Anda membuat komputer, Anda ingin memastikan bahwa bagian yang Anda pilih kompatibel satu sama lain. Untuk prosesor Anda, ada beberapa hal yang perlu dipertimbangkan di bagian depan kompatibilitas.
Yang pertama adalah memastikan bahwa Anda mencocokkan CPU yang Anda pilih dengan motherboard yang memiliki soket CPU yang benar. Soket CPU adalah soket pada motherboard tempat CPU dicolokkan. Tidak semua CPU bisa masuk ke semua soket CPU. Misalnya, CPU AMD tidak dapat masuk ke soket CPU berbasis Intel dan sebaliknya.
Selain itu, karena Intel dan AMD keluar dengan arsitektur prosesor baru, mereka juga keluar dengan soket CPU baru untuk mengakomodasi arsitektur baru.
Ini berarti bahwa beberapa prosesor AMD dan Intel yang lebih lama tidak kompatibel dengan soket CPU yang dibuat untuk soket AMD dan Intel yang lebih baru. Misalnya, Intel Core i7-4770K dimaksudkan untuk bekerja dengan soket LGA 1150, sedangkan Intel Core i7-12700K dimaksudkan untuk bekerja dengan soket LGA 1200.
Anda tidak dapat menggunakan i7-4770K di motherboard soket LGA 1200 dan sebaliknya. Jadi, intinya adalah, ketika Anda memilih prosesor Anda, Anda perlu memahami untuk apa soket CPU itu dimaksudkan untuk bekerja sehingga ketika Anda memilih motherboard, Anda memilih yang tepat.
6. Dapatkan Chipset Motherboard yang Tepat
Selain memastikan bahwa Anda memahami bahwa CPU Anda hanya dapat masuk ke soket tertentu, Anda juga perlu memahami bahwa CPU yang Anda pilih harus dipasangkan dengan motherboard yang memiliki chipset yang mengakomodasi CPU Anda.
Pertama, ada berbagai jenis motherboard yang tersedia pada soket tertentu. Mereka dipisahkan oleh chipset. Pada dasarnya, chipset menentukan fitur apa yang ada pada motherboard. Beberapa chipset memiliki lebih banyak fitur/port/dibangun dengan lebih baik.
Dan, beberapa chipset memiliki fitur yang lebih sedikit tetapi lebih murah.Namun, penting untuk dicatat bahwa prosesor yang Anda pilih kemungkinan akan memiliki chipset yang paling cocok dengannya. Misalnya, CPU Intel yang dapat di-overclock harus dipasangkan dengan motherboard yang dibuat untuk overclock.
Jika Anda mendapatkan prosesor Intel Core i7-12700K LGA 1200, Anda memilih prosesor yang dapat di-overclock (ditandai dengan ‘K’) dan, Anda akan ingin memasangkannya dengan chipset motherboard LGA 1200 yang dirancang untuk overclock.
Bagaimana Dengan Penunjukan ‘F’ pada CPU Intel? Intel K vs KF: Apa Bedanya?
Ada motherboard chipset Z690 yang dirancang untuk overclocking. Dan, kemudian ada motherboard B660, H670, dan H610 pada soket LGA 1200 yang tidak dirancang untuk overclocking.
Jadi, jika Anda mendapatkan i7-12700K, Anda harus menggunakan motherboard Z690 sehingga Anda dapat melakukan overclock prosesor Anda. Jika Anda tidak ingin meng overclock prosesor Anda, Anda dapat menggunakan Intel Core i7-12700 (tanpa ‘K’) dan motherboard B660 atau H670. Tentu saja, Anda dapat memasangkan i7-12700K dengan motherboard chipset B660 atau H670 non-overclocking. Secara teknis, keduanya akan bekerja sama.
Namun, kelemahannya di sini adalah, karena perangkat keras yang mengakomodasi overclocking membutuhkan biaya lebih banyak, adalah pemborosan pengeluaran untuk memasangkan CPU yang dapat di overclock dengan motherboard yang tidak mengizinkan overclocking.
Jadi, chipset CPU dan motherboard yang tepat untuk Anda sebagian besar tergantung pada berapa banyak uang yang harus Anda keluarkan dan apakah Anda ingin melakukan overclock atau tidak. Baik AMD dan Intel menawarkan berbagai chipset untuk prosesor mereka. Mereka menyediakan chipset kelas atas untuk overclocking, serta opsi yang lebih ramah anggaran juga.
Masalah Kompatibilitas Antara Generasi CPU & Chipset Lama/Baru
Hal penting lainnya yang perlu diperhatikan pada chipset adalah bahwa, meskipun sebagian besar soket CPU kompatibel ke belakang dan ke depan, masalah dapat muncul saat Anda memasangkan CPU lama dengan chipset generasi baru dan sebaliknya meskipun secara teknis kompatibel satu sama lain.
Masalah utamanya adalah, dalam beberapa kasus, jika Anda memasangkan CPU yang lebih baru dengan chipset motherboard yang lebih lama pada soket yang sama, mereka dapat bekerja bersama, tetapi Anda mungkin harus mem-flash BIOS motherboard agar kompatibel dengan yang lebih baru. prosesor.
7. Dapatkan Pendingin CPU yang Tepat
Terakhir, jika Anda menggunakan prosesor yang dapat di-overclock, Anda mungkin ingin mempertimbangkan untuk mendapatkan solusi pendinginan yang lebih baik. Untuk meng-overclock prosesor Anda, pada dasarnya Anda memaksanya untuk berjalan lebih cepat daripada kehabisannya.
Dan, untuk membuatnya berjalan lebih cepat, Anda harus mengirim lebih banyak daya ke sana. Tapi, semakin banyak kekuatan yang Anda kirimkan, semakin panas.
Prosesor hanya bisa menjadi sangat panas sebelum dipaksa melambat. Namun, jika Anda dapat menyesuaikan kenaikan suhu prosesor saat Anda melakukan overclock dengan solusi pendinginan yang unggul, Anda dapat menjaga suhu CPU Anda dalam kisaran yang moderat.
Juga, semakin baik Anda dapat mendinginkan prosesor Anda, semakin tinggi Anda dapat melakukan overclock (sampai batas tertentu.) Sebagian besar CPU dilengkapi dengan pendingin CPU bawaan. Biasanya, pendingin stok tidak cukup baik untuk segala jenis overclocking yang signifikan. (Meskipun, prosesor Ryzen baru AMD hadir dengan pendingin stok yang mumpuni.)
![]()
![]()
![]()
![]()
![]()
Cara Mengeksekusi dan Menjalankan Kode Java dari Terminal
Cara Mengeksekusi dan Menjalankan Kode Java dari Terminal – Jika Anda bekerja dengan Java, Anda mungkin pernah menggunakan salah satu editor teks terkenal seperti Sublime Text, VS Code, Brackets, Atom, dan Notepad++ serta IDE seperti Apache NetBeans dan IntelliJ IDEA.
Cara Mengeksekusi dan Menjalankan Kode Java dari Terminal

zorba-xquery – Menjalankan kode di IDE Anda sangatlah mudah, tetapi Anda tidak sering melihat bagaimana kode tersebut mengeksekusi kode Anda (walaupun Anda dapat memeriksa perintah di terminal tentu saja!).
Namun, ini adalah praktik yang baik untuk mengetahui bagaimana kode Anda benar-benar dijalankan dan memberikan output yang diberikannya kepada Anda.
Banyak dari Anda mungkin pernah mendengar bahwa programmer profesional yang berpengalaman juga menggunakan terminal untuk menjalankan program.
Ini memberi mereka kejelasan yang lebih baik dan membantu mereka memahami cara kerja kode, di mana ia mengembalikan nilai yang diinginkan, di mana bug itu berada, dan seterusnya.
Baca Juga : Cara Menjalankan Program Java di CMD Menggunakan Notepad
Apa pun tujuan Anda, mengeksekusi kode Java langsung dari terminal adalah tugas yang sangat mudah. Pada artikel ini, saya akan menunjukkan kepada Anda bagaimana Anda dapat mengeksekusi Java langsung dari jendela terminal favorit Anda.
Jangan takut! Prosedurnya cukup mudah, dan setelah membaca seluruh artikel Anda seharusnya dapat menjalankan kode Java Anda sendiri di terminal.
Cara Menjalankan Kode Java di Terminal
Proses yang akan saya tunjukkan dalam artikel ini berlaku untuk sistem operasi apa pun baik itu Windows, MacOS, atau Linux. Saya akan menggunakan kode Java berikut di langkah berikutnya.
public class Main {
public static void main(String[] args) {
System.out.println(“Hello, World!”);
}
}
Langkah 1 Buka direktori tempat kode sumber Anda berada
Jika Anda sudah menulis kode Java Anda di editor, maka cukup masuk ke direktori itu. Anda dapat langsung masuk ke direktori melalui pengelola file Anda jika Anda mau.
Cara masuk ke direktori tempat kode sumbernya: untuk Windows
Misalkan saya memiliki kode sumber ( Main.java) di dalam This PC> Documentsfolder. Saya cukup pergi ke sana melalui file explorer saya. Atau, jika saya mau, saya juga bisa pergi ke sana menggunakan terminal saya.
Saya perlu menggunakan cduntuk menunjukkan bahwa saya ingin mengubah direktori . Dalam hal ini, saya dapat menggunakan cd “C:\Users\Md. Fahim Bin Amin\Documents”. Karena nama pengguna saya mengandung spasi putih, saya telah menggunakannya ” “untuk melampirkannya.
Kemudian jika saya memeriksa semua file di bawah direktori itu, maka saya akan mendapatkan Main.javafile juga. Saya menempatkan Main.javafile di bawah drive D saya kali ini. Jadi saya masuk ke direktori itu menggunakan cdperintah.
Saya mendapatkan file Java saya di terminal juga.
Cara masuk ke direktori tempat kode sumbernya: untuk Linux
Anda dapat masuk ke direktori tempat Anda menyimpan kode sumber dengan mengikuti cara GUI yang khas atau dari terminal menggunakan cdperintah juga. menggunakan cara GUI yang khas, Menggunakan cdperintah.
Cara Mengkompilasi Kode Java
Sebelum menjalankan kode Java kita, kita perlu mengkompilasinya terlebih dahulu. Untuk mengkompilasi kode/program Java, kita mendapatkan file kelas. Maka kita perlu mengeksekusi/menjalankan file kelas.
Cara mengkompilasi kode Java menggunakan terminal
Kita perlu menggunakan perintah javac file name with the extension. Misalnya, karena saya ingin mengkompilasi Main.java, saya akan menggunakan perintah javac Main.
java. In menunjukkan kompilasi c.javac Jika proses kompilasi berhasil, maka kita tidak akan mendapatkan error apapun. Ini akan membuat file kelas yang kita butuhkan di bawah direktori yang sama.
Perlu diingat bahwa kita menjalankan file kelas , bukan . javafile. Proses yang sama berlaku untuk semua sistem operasi di luar sana.
Cara Menjalankan Kode Java
Kami menjalankan .classfile untuk menjalankan program Java. Untuk itu, kita menggunakan perintah java class_file_name_without_the_extension. Seperti, karena .classfile kami untuk ini adalah Main.class, perintah kami adalah java Main. Program Java telah berhasil dijalankan! Prosedur yang sama persis juga berlaku untuk sistem operasi lain juga.
Bonus: Cara Menjalankan Program Java dengan Paket
Paket pada dasarnya berarti folder. Sebelumnya, saya menunjukkan cara menggunakan kode Java biasa menggunakan terminal. Di sana, saya tidak menggunakan paket apa pun di dalam kode Java.
Sekarang saya akan menunjukkan kepada Anda bagaimana Anda dapat menjalankan kode Java apa pun yang memiliki paket yang dideklarasikan di dalamnya. Kali ini, saya akan menggunakan kode Java berikut.
package myJavaProgram.Source;
public class Main {
public static void main(String[] args) {
System.out.println(“Hello, World!”);
}
}
Di baris pertama, saya telah menulis paket sebagai package myJavaProgram.Source. Ini menunjukkan bahwa saya ingin membuat folder bernama myJavaProgram.
Kemudian, saya ingin membuat folder lain di bawah yang bernama Source. Akhirnya, saya ingin membuat file kelas kode Java saya di dalam Sourcefolder.
Pohon direktori terlihat seperti ini: myJavaProgram > Source. Untuk mengkompilasi kode Java jenis ini dengan paket, kami menggunakan perintah javac d . file name with the extension.
Untuk saat ini, saya menggunakan Main.javafile, jadi saya akan menerapkan perintah javac d . Main.java. Ini akan membuat folder bernama myJavaProgram , lalu buat folder lain bernama Source di bawah folder myJavaProgram di bawah direktori tempat file sumber saya sekarang.
The_Directory_Where_I_Have_Simpan_My_Source_Code
myJavaProgrammap
Sourcemap
Itu langsung membuat folder myJavaProgram .
Di dalam folder, itu membuat folder Sumber .
Di dalam folder Sumber, itu membuat .classfile kita. Kami membutuhkan file ini untuk menjalankan program Java.
Jika Anda bertanya-tanya mengapa kami mengubah perintah sekarang, itu karena sebelumnya, kami tidak mendeklarasikan paket apa pun.
Jadi kompiler Java membuat .classfile di dalam direktori tempat kode sumber kita berada. Jadi, kita bisa mendapatkan . classfile langsung dari sana dan mengeksekusi file kelas juga.
Tetapi jika kita mendeklarasikan paket-paket di dalam kode sumber seperti ini, maka kita menyuruh kompiler untuk membuat . Classfile di tempat lain (bukan di dalam direktori tempat kode sumber kita saat ini berada).
Artinya kita tidak mendapatkan file kelas langsung di sana. Karena kita ingin menjalankan file kelas, kita perlu memberi tahu kompiler secara eksplisit di mana file kelas saat ini berada sehingga ia bisa mendapatkan file kelas dan menjalankannya.
Jika Anda berpikir bahwa Anda mungkin mengacaukan langkah ini, maka Anda dapat menyalin direktori langsung dari kode Java Anda.
Tangkapan Layar-2022-03-10-135404
Pada baris 1, kita telah mendeklarasikan direktori paket (di mana kita ingin file kelas dihasilkan). Jadi jika kita hanya menyalin direktori dan menambahkan .
Classnama file tanpa ekstensi ( class) kemudian dengan titik ( .), maka memenuhi kondisi untuk mengeksekusi kode Java yang memiliki paket yang dideklarasikan dalam kode sumber. Proses yang sama juga berlaku untuk sistem operasi lain. Saya menyediakan tangkapan layar dari OS Linux di sini:
Kerja bagus! Sekarang Anda dapat menjalankan kode/program Java secara langsung menggunakan terminal. Saya juga telah membuat video di mana saya telah menunjukkan semua proses yang disebutkan di atas. Anda dapat memeriksanya di sini .
Kesimpulan
Saya harap artikel ini membantu Anda menjalankan program Java hanya dengan menggunakan terminal. Saya juga ingin mengucapkan terima kasih dari lubuk hati saya untuk membaca seluruh artikel hingga saat ini.
Jika Anda ingin tahu cara menginstal kompiler Java untuk sistem operasi Windows Anda, maka Anda dapat melihat artikel ini . Jika Anda ingin tahu cara menginstal compiler C dan C++ untuk sistem operasi Windows Anda, maka Anda dapat melihat artikel ini . Jika Anda ingin tahu cara menginstal Python di OS Windows Anda, maka Anda dapat melihat artikel ini .
Jika Anda ingin menghubungi saya, pertimbangkan untuk memeriksa platform ini: GitHub , Twitter , LinkedIn , saluran YouTube Inggris , saluran YouTube Bengali . Jika Anda ingin memeriksa sorotan saya, Anda dapat melakukannya di timeline Polywork saya .
![]()
![]()
![]()
![]()
![]()
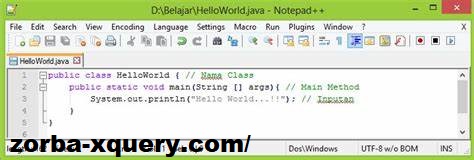
Cara Menjalankan Program Java di CMD Menggunakan Notepad
Cara Menjalankan Program Java di CMD Menggunakan Notepad – Pada bagian ini, kita akan mempelajari cara menyimpan, mengkompilasi, dan menjalankan (mengeksekusi) program Java di Command Prompt (CMD) menggunakan notepad .
Cara Menjalankan Program Java di CMD Menggunakan Notepad
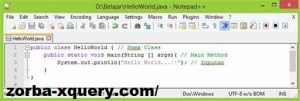
zorba-xquery – Sebelum menjalankan (mengeksekusi) program Java , pastikan Java telah terinstal di sistem dan jalurnya diatur dengan benar. Jika jalur tidak diatur dengan benar, kami tidak dapat menjalankan program Java .
Baca Juga : Kiat Kinerja dan Pengoptimalan untuk XQuery
Kita harus mengikuti langkah-langkah yang diberikan di bawah ini untuk menjalankan program Java.
Buka notepad dan tulis program Java ke dalamnya.
Simpan program Java dengan menggunakan nama kelas diikuti dengan ekstensi .java .
Buka CMD, ketik perintah dan jalankan program Java.
Mari kita membuat program Java dan menjalankannya menggunakan Command Prompt.
- Langkah 1: Buka notepad dengan menekan tombol Windows + R , ketik notepad dan tekan tombol enter , atau klik tombol Ok . Ini membuka notepad.
- Langkah 2: Tulis program Java yang ingin Anda kompilasi dan jalankan. Kami telah menulis kode berikut di notepad.
- Langkah 3: Untuk menyimpan program Java, tekan tombol Ctrl + S dan berikan nama file. Ingat bahwa nama file harus sama dengan nama kelas diikuti dengan ekstensi . Jika Anda menulis program Java yang sama (seperti di atas) simpan dengan memberikan nama file CharArrayToStringExample.java tekan tombol enter atau klik tombol Simpan . Kami telah menyimpan program di atas di lokasi C:\demo .
Sekarang, kami telah membuat dan menyimpan program Java. Pada langkah selanjutnya, kita akan mengkompilasi dan menjalankan program Java.
- Langkah 4: Untuk mengkompilasi dan menjalankan program Java, buka Command Prompt dengan menekan Tombol Windows + R , ketik cmd dan tekan tombol enter atau klik tombol Ok . Ini membuka jendela Command Prompt .
- Langkah 5: Di jendela Command Prompt, tulis perintah berikut.Sekarang kita berada di dalam folder demo tempat kita menyimpan program Java.
- Langkah 6: Untuk mengkompilasi program Java ketik perintah berikut: Ketika kami mengkompilasi program Java tanpa kesalahan, itu membuat file .class dengan nama yang sama dengan nama file di lokasi yang sama (tempat program disimpan).
- Langkah 7: Untuk menjalankan program Java, ketik perintah berikut.Perhatikan bahwa kami tidak menulis .java setelah nama file.Pada gambar di atas, selamat datang di Javatpoint adalah output dari program.
Cara Menjalankan Program Java Di Cmd Menggunakan Notepad
Jika Anda membaca posting ini tentang Cara Menjalankan Program Java Di Cmd maka sepertinya Anda sudah menulis program java. Ada banyak lingkungan pemrograman yang akan menyediakan Anda platform untuk menjalankan dan mengkompilasi program java . Namun ada juga cara alternatif untuk menjalankan program java yaitu menggunakan cmd prompt. Windows memiliki command prompt dan iOS serupa juga memiliki command prompt sendiri yang disebut Terminal.
Prompt perintah adalah platform yang terletak di sistem operasi windows tempat Anda dapat menjalankan perintah. Sebelum menjalankan program java di cmd prompt harus ada JDK (java development kit) yang terinstal di PC Anda. Tanpa JDK tidak mungkin untuk mengkompilasi dan menjalankan program java di cmd Prompt. Untuk menjalankan program java di command prompt, Anda perlu melakukan dua langkah utama: Instal JDk di PC Anda.
- Instal JDK di PC Anda.
- Atur Jalur JDK di Pengaturan Komputer.
- Jadi, pertama-tama, kami akan menunjukkan cara mengunduh JDK di PC Anda.
Cara Mengunduh JDK di PC Anda.
- Langkah 1: Kunjungi situs web resmi Oracle dan cari JDK.
- Langkah 2: Temukan Versi yang Cocok dari Java JDK SE Development Kit.
- Langkah 3: Pastikan Anda mengambil versi windows.
- Langkah 4: Sekarang Unduh JDK dan instal di PC Anda.
Sekarang akhirnya JDK terinstal di komputer kita Sekarang mari kita belajar bagaimana menjalankan program java di Cmd menggunakan notepad.
Cara Mengatur Jalur untuk JDK
- Langkah 1: Klik Kanan pada My Computer atau This PC dan klik Properties.
- Langkah 2: Klik Pengaturan Sistem Lanjutan. Sekarang Di dalam Tab Lanjutan klik opsi Variabel Lingkungan.
- Langkah 3: Sebuah jendela akan muncul Jadi di System Variable klik New. Sekarang beri nama variabel sebagai “var” dan Di jalur, bidang letakkan jalur JDK C:\ProgramFiles\Java\jdk1.8.0_251\bin .
- Langkah 4 : Klik OK.
Sekarang Jalan telah ditetapkan. Untuk menjalankan program java, program Anda harus diprogram dalam Aplikasi bawaan Microsoft yang disebut Notepad. Sebelum mulai belajar mari kita perhatikan contoh program java. Kami akan mengambil contoh program java Hello World.Output dari contoh java di atas adalah “ Hello World! “. Jadi kita akan melihat bagaimana mengkompilasi kode di atas dalam Cmd menggunakan Notepad.
Langkah-langkah Menjalankan Program Java Di Cmd.
- Langkah 1: Ketik kode java yang sama di atas dalam aplikasi bawaan Microsoft bernama Notepad seperti yang ditunjukkan pada gambar di bawah ini.
- Langkah 2: Sekarang simpan file Notepad di folder tertentu di mana pun Anda inginkan. saat menyimpan file ekstensi file itu harus “.java” contoh test.java seperti yang ditunjukkan pada gambar di bawah ini.
- Langkah 3: Sekarang buka command prompt dari menu. Jangan langsung membuka command prompt. Pertama klik kanan pada command prompt dan kemudian klik Run as administrator seperti yang ditunjukkan pada gambar. Setelah mengklik Jalankan sebagai administrator, prompt perintah akan dibuka di layar Anda.
- Langkah ke-4: Sekarang menggunakan perintah cd (direktori perintah), ubah lokasi direktori kerja. Di pc saya, saya telah menyimpan file java di lokasi C->users->btbj->test program->test.java. Sekarang kita akan menemukan lokasi file java yang tepat menggunakan command prompt. Kami telah menemukan file java yang tepat di command prompt.
- Langkah ke-5: Sekarang kompilasi program menggunakan perintah kompiler java “javac” . Untuk mengkompilasi pengujian file java ketik javac(yourfilename .java ) dan tekan enter. Setelah mengkompilasi file java file .class telah ditambahkan ekstra. Untuk memeriksa apakah file .class telah ditambahkan atau belum ketik dir di command prompt.
- Langkah 6: Sekarang jalankan program menggunakan perintah java yaitu ketik “java yourfileclassname” dan tekan enter. Sekarang compiler telah menampilkan output di layar yaitu Hello World!.
Cara Menjalankan Program Java Di Windows 10
- Langkah 1: Ketik kode java di notepad dan simpan di folder tertentu dengan ekstensi .java .
- Langkah 2: Sekarang buka command prompt.
- Langkah 3: Atur jalur JDK dan cari file di command prompt.
- Langkah 4: kompilasi file menggunakan perintah java compiler javac yourfilename.java .
- Langkah 5: Setelah mengkompilasi file, jalankan program menggunakan perintah java classname dan tekan enter.
- Langkah 6: Sekarang output dicetak di layar.
Cara Menjalankan Program Java di cmd Youtube
Dalam video Youtube ini , kami telah menunjukkan cara menjalankan program java di cmd Menggunakan Notepad. Video ini mencakup pengaturan jalur JDK dan proses kompilasi dan menjalankan tautan program java .
Jalankan Program Java Online
Tahukah kamu? program java juga dapat dikompilasi secara online. Ada juga kompiler java online yang tersedia. OnlineGDB adalah kompiler online terbaik yang akan saya rekomendasikan secara pribadi.
Jalankan Java Dari Baris Perintah Linux
OpenJDK adalah yang terbaik untuk bekerja di Linux. Saya tidak pernah menghadapi masalah dalam menggunakannya di Linux. Untuk Menjalankan Java dari Command Line di Linux Cukup ikuti langkah-langkahnya:
- Langkah 1: Dengan bantuan terminal instal buka JDK menggunakan perintah “Sudo apt-get install openjdk-7-jdk”
- Langkah 2: Sekarang tulis kode java di Text Editor dan simpan di root dengan ekstensi filename.java .
- Langkah 3: Sekarang kompilasi program menggunakan java compiler javac yaitu ketik javac filename.java di terminal.
- Langkah 4: Sekarang file kelas baru telah dibuat.
- Langkah 5: Sekarang jalankan file java dengan mengetikkan nama kelas java di terminal.
- Langkah 6: Sekarang output telah ditampilkan di layar.
Kesimpulan
Jadi kita telah melihat bagaimana program java dijalankan dan dikompilasi di command prompt. Semoga Anda telah mempelajari dan memahami cara menjalankan program java di cmd menggunakan notepad. Jika Anda memiliki keraguan dan pertanyaan, jangan ragu untuk bertanya di bagian komentar di bawah.
![]()
![]()
![]()
![]()
![]()
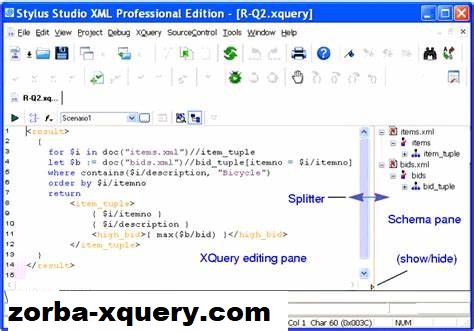
Kiat Kinerja dan Pengoptimalan untuk XQuery
Kiat Kinerja dan Pengoptimalan untuk XQuery – Saat pertama kali kueri dijalankan, persentase yang signifikan dari total waktu kueri dihabiskan untuk menyiapkan kueri, yang mencakup pengoptimalan kueri dan membuat rencana kueri. Karena sebagian besar program memanggil kueri lebih dari sekali, kami menghabiskan waktu yang diperlukan untuk menemukan cara yang efisien untuk memproses kueri, meskipun itu membuat kueri pertama menjadi lebih lambat. Untungnya, upaya ini tidak perlu diulang.
Kiat Kinerja dan Pengoptimalan untuk XQuery

zorba-xquery – Salah satu cara untuk memastikan bahwa kueri disiapkan hanya sekali dalam program Anda adalah dengan menggunakan kueri yang disiapkan. (Cara lain adalah dengan menggunakan Query Pooling, dijelaskan di bagian berikut).Untuk membuat parameter kueri, gunakan variabel eksternal untuk mengubah nilai yang digunakan untuk kueri setiap kali kueri dipanggil. Misalnya, kueri berikut membuat portofolio untuk pengguna tertentu:
Baca Juga : Semua Yang Perlu Anda Ketahui Sebelum Memilih Prosesor
Contoh 1. Query dengan Variabel Eksternal
declare variable $user as xs:string external;
collection(‘holdings’)/holdings[userid=$user]
Dalam kueri ini, $user adalah variabel eksternal yang harus diikat sebelum mengeksekusi kueri. Kode XQJ berikut menunjukkan cara menyiapkan kueri dan mengikat nilai ke $user.
Contoh 2. Menyiapkan Query
// Get a connection, prepare the query
XQDataSource dataSource = new DDXQDataSource();
dataSource.setJdbcUrl(“jdbc:xquery:sqlserver://server1:1433;databaseName=stocks”);
XQConnection connection = dataSource.getConnection();
XQPreparedExpression preparedExpression = connection.prepareExpression(xqueryText);
// Bind variable $user to ‘Jonathan’ and execute
preparedExpression.bindString(new QName(“user”), “Jonathan”);
XQSequence xqSequence = preparedExpression.executeQuery();
Kode berikut menunjukkan cara mengikat $user ke nilai yang berbeda dan menjalankan lagi kueri yang disiapkan.
Contoh 3. Mengeksekusi Query yang Disiapkan dengan Nilai Baru
// Bind variable $user to ‘Minollo’ and execute
preparedExpression.bindString(new QName(“user”), “Minollo”);
xqSequence = preparedExpression.executeQuery();
Tolok ukur yang mengukur kecepatan kueri harus mencerminkan penggunaan yang Anda harapkan dalam program Anda. Karena sebagian besar program menjalankan kueri berkali-kali, saat Anda mendesain tolok ukur, Anda harus menyiapkan kueri, lalu menjalankannya berkali-kali.
Pengumpulan Kueri
Ekspresi yang disiapkan memungkinkan pemrogram memutuskan kapan kueri harus disiapkan dan kapan kueri yang disiapkan tidak lagi diperlukan. Dalam program yang menggunakan ratusan atau ribuan kueri, umumnya lebih baik membiarkan DataDirect XQuery® melacak kueri mana yang benar-benar digunakan, mempersiapkannya saat pertama kali dijalankan, dan membuang kueri siap yang paling jarang digunakan jika ada banyak pertanyaan. Ini disebut pengumpulan kueri.
Di DataDirect XQuery®, Anda mengaktifkan kumpulan kueri dengan menentukan jumlah kueri yang disiapkan untuk disimpan di kumpulan. Jika Anda mengonfigurasi koneksi Anda dengan menyetel properti di Java API, Anda dapat menyetel properti MaxPooledQueries untuk melakukan ini; misalnya, kode berikut menetapkan ukuran kumpulan kueri menjadi 20:
Contoh 4. Mengaktifkan Pengumpulan Kueri dengan Java API
XQDataSource dataSource = new DDXQDataSource();
dataSource.setJdbcUrl(“jdbc:xquery:sqlserver://server1:1433;
databaseName=stocks”);
dataSource.setMaxPooledQueries(20);
XQConnection connection = dataSource.getConnection();
Jika Anda mengonfigurasi koneksi menggunakan File Konfigurasi Sumber, Anda dapat mengatur ukuran kumpulan kueri menggunakan elemen maxPooledQueries:
Contoh 5. Mengaktifkan Pengumpulan Kueri dalam File Konfigurasi
<?xml version=”1.0″ encoding=”UTF-8″?>
<XQJConnection xmlns=”http://www.datadirect.com/xquery”>
<maxPooledQueries>20</maxPooledQueries>
<JDBCConnection name=”stocks”>
<url>jdbc:xquery:sqlserver://localhost:1433</url>
<sqlxmlMapping>
<forest>true</forest>
<identifierEscaping>none</identifierEscaping>
</sqlxmlMapping>
</JDBCConnection>
</XQJConnection>
Meminta File XML Besar
DataDirect XQuery menyediakan beberapa cara untuk mengkueri file XML. Di DataDirect XQuery, Anda akan mendapatkan kinerja yang lebih baik, terutama untuk file XML besar, jika Anda menggunakan fn:doc() untuk mengakses XML dalam kueri. Anda akan mendapatkan kinerja yang jauh lebih buruk jika Anda mengurai XML untuk membuat pohon DOM, mengikat pohon DOM ke variabel eksternal, dan menanyakan variabel eksternal.
Di sebagian besar prosesor XQuery, sebagian besar waktu yang diperlukan untuk kueri file XML besar dihabiskan untuk menguraikan file dan membuat representasi dalam memori yang dapat ditanyakan. Representasi dalam memori mungkin beberapa kali ukuran file XML asli, dan Java VM kehabisan memori kesalahan dapat terjadi pada waktu berjalan. Saat kueri Anda mengalamatkan file XML menggunakan fn:doc(), DataDirect XQuery menggunakan teknik yang dikenal sebagai Proyeksi Dokumen, yang memungkinkannya membuat hanya bagian dokumen yang diperlukan oleh kueri. Ini menghasilkan peningkatan dramatis dalam penggunaan memori dan skalabilitas, dan peningkatan kinerja yang signifikan. Menggunakan proyeksi dokumen, Anda biasanya dapat menanyakan dokumen berkali kali ukuran memori yang tersedia. Kebetulan, jika aplikasi Anda menggunakan XML Deployment Adapters, ini menangani adaptor ini menggunakan fn:doc(), dan DataDirect XQuery menggunakan Proyeksi Dokumen dengan tepat untuk adaptor ini seperti halnya untuk dokumen XML.
Proyeksi dokumen menggunakan ekspresi jalur dalam kueri untuk menentukan bagian dokumen apa yang perlu dibuat. Ekspresi jalur yang menggunakan karakter pengganti memberikan lebih sedikit informasi untuk proyeksi dokumen, sehingga harus dihindari saat menanyakan dokumen besar. Misalnya, dalam contoh di bawah ini, ekspresi jalur kedua akan tampil jauh lebih baik untuk dokumen besar.
Contoh 6. Hindari ekspresi jalur dengan wildcard
doc(“scenario.xml”)*[role=’teacher’]
Contoh 7. Proyeksi dokumen bantuan ekspresi jalur khusus
doc(“scenario.xml”) scenario people person[role=’teacher’]
Jika Anda mengurai dokumen untuk membuat pohon DOM, lalu mengikat pohon DOM ke variabel eksternal, Anda melewati Proyeksi Dokumen DataDirect. Ini memaksa program Anda untuk membuat seluruh representasi dalam memori dari dokumen XML Anda bukan hanya bagian yang dibutuhkan DataDirect XQuery untuk memproses kueri Anda. Selain penghematan karena Proyeksi Dokumen, representasi internal DataDirect dari dokumen XML jauh lebih efisien daripada kebanyakan implementasi DOM, jadi menggunakan fn:doc memberi Anda dua pengoptimalan substansial yang hilang jika Anda mengurai dokumen sendiri.
DataDirect XQuery juga mendukung teknik kedua yang dikenal sebagai Streaming. Streaming memproses dokumen secara berurutan, membuang bagian dokumen yang tidak lagi diperlukan untuk menghasilkan hasil kueri lebih lanjut. Ini mengurangi penggunaan memori karena hanya sebagian dari dokumen yang diperlukan pada tahap tertentu dari pemrosesan kueri yang dibuat dalam memori. Streaming dapat mengurangi konsumsi memori, tetapi umumnya melibatkan penalti kinerja (relatif kecil).
Tidak seperti proyeksi dokumen, streaming umumnya bukan merupakan kemenangan kinerja. Selain itu, beberapa kueri memerlukan banyak dokumen untuk dipakai pada waktu tertentu, sehingga mengurangi manfaat streaming. Namun, untuk beberapa kueri, streaming bisa menjadi kemenangan yang substansial, terutama jika hasil kueri melebihi memori yang tersedia; oleh karena itu, kami mengizinkan streaming untuk diaktifkan, tetapi kami tidak mengaktifkannya secara default.Untuk mengaktifkan streaming, setel opsi ddtek:xml-streaming ke ‘yes’ di XQuery Prolog:
Contoh 8. Mengaktifkan Streaming di Prolog Kueri
declare option ddtek:xml streaming ‘yes’;
Anda juga dapat mengaktifkan streaming di tingkat DataSource, yang berarti streaming akan digunakan untuk semua kueri yang menggunakan DataSource. Salah satu cara untuk melakukannya adalah dengan menyetel properti Pragmas dari kelas DDXQDataSource.
Contoh 9. Mengaktifkan Streaming untuk DataSource di Java API
XQDataSource dataSource = new DDXQDataSource();
dataSource.setJdbcUrl(“jdbc:xquery:sqlserver://server1:1433;
databaseName=stocks”);
dataSource.setPragmas(“xml-streaming=yes”);
Cara lain untuk mengaktifkan streaming di tingkat DataSource adalah dengan menentukan opsi deklarasi menggunakan elemen pragma dalam File Konfigurasi Sumber:
Contoh 10. Mengaktifkan Streaming untuk Sumber Data dalam File Konfigurasi
<?xml version=”1.0″ encoding=”UTF-8″?>
<XQJConnection
<maxPooledQueries>20</maxPooledQueries>
<pragma name=”xml-streaming”>yes</pragma>
<JDBCConnection name=”stocks”>
<url>jdbc:xquery:sqlserver://localhost:1433</url>
<sqlxmlMapping>
<forest>true</forest>
<identifierEscaping>none</identifierEscaping>
</sqlxmlMapping>
</JDBCConnection>
</XQJConnection>![]()
![]()
![]()
![]()
![]()

Semua Yang Perlu Anda Ketahui Sebelum Memilih Prosesor
Semua Yang Perlu Anda Ketahui Sebelum Memilih Prosesor – Saat Anda berbelanja komputer, mudah kewalahan oleh semua spesifikasi yang menatap Anda. Di antara berbagai ukuran layar, resolusi, dan faktor bentuk, ada banyak hal yang harus Anda perhatikan.
Semua Yang Perlu Anda Ketahui Sebelum Memilih Prosesor

zorba-xquery – Bahkan jika Anda memiliki semua itu, Anda masih harus mencari tahu prosesor mana yang sesuai dengan kebutuhan Anda, yang dapat menjadi tugas tersendiri mengingat nomor model yang tampaknya tidak dapat diuraikan yang sepertinya tidak memberi tahu Anda banyak tentang apa chip sebenarnya dimaksudkan untuk dilakukan.
Kabar baiknya adalah bahwa deretan angka dan huruf yang panjang itu memang memiliki arti, dan mereka jauh lebih mudah untuk diuraikan daripada dibiarkan. Setelah Anda memahami sintaks dan mengetahui apa yang Anda butuhkan, Anda akan dapat mengintip chip apa pun dan mengetahui apakah chip tersebut akan berhasil.
Baca Juga : Bagaimana Proses Menjalankan Program Java Di CMD
Tapi sebelum kita masuk ke barang, penting untuk mengetahui satu atau dua hal tentang cara kerja prosesor.
Apa itu CPU?
Unit Pemrosesan Pusat (juga dikenal sebagai CPU, prosesor, atau chip), bertindak sebagai pusat perintah komputer Anda, yang mengambil semua tugas sistem Anda dan mendelegasikannya ke komponen perangkat keras yang berbeda. Setiap prosesor memiliki “jumlah inti”, yang memberi tahu Anda berapa banyak inti fisik—hub individual yang dapat menangani tugas tertentu, sehingga komputer Anda dapat mendistribusikan beban kerjanya secara lebih merata—yang ada di dalamnya.
Terakhir, beberapa chip (biasanya untuk laptop) mungkin berisi apa yang dikenal sebagai GPU terintegrasi, atau prosesor grafis berdaya rendah. Itu dibangun langsung ke dalam chip sehingga Anda tidak perlu mengambil ruang ekstra dengan GPU diskrit (AKA standalone).
Jadi ada titik awal yang baik. Dengan itu, inilah cara memilih prosesor yang tepat dari semua produsen chip utama.
Intel
Entah itu dari lonceng “Intel Inside” lama yang masih muncul di kepala Anda dari waktu ke waktu beberapa dekade kemudian atau hanya stiker kecil yang Anda lepaskan dari sudut laptop Anda saat pertama kali Anda mem-boot-nya, Anda mungkin akrab dengan Intel . Prosesor perusahaan memberi daya pada komputer di perpustakaan lokal Anda, laptop yang dikeluarkan untuk pekerjaan Anda, dan server cloud yang tak terhitung jumlahnya.
Sekilas, jajaran prosesor Intel yang luas tidak akan memberi tahu Anda banyak. Ada sedikit konteks untuk mengumpulkan apa perbedaan antara Xeon dan chip Atom, tetapi struktur penamaan Intel sebenarnya berguna. Setiap chip dimulai dengan nama mereknya —Xeon, Pentium, Celeron, atau Core—dan masing-masing chip memberi tahu Anda jenis kinerja yang dimaksudkan.
Di kelas atas, Anda akan menemukan chip Core, yang tersedia dalam varian i3, i5, i7, dan i9. Ini biasanya ditemukan di laptop, 2-in-1, dan desktop kelas atas; varian i5 akan lebih cepat dari i3, dan seterusnya. Saat inti naik, begitu juga jumlah utas: chip i3 dengan dua atau empat inti akan datang dengan empat atau delapan utas, i5 dengan enam inti akan memiliki 12, dan i9 dengan delapan inti akan memiliki 16 utas. Ada beberapa pengecualian, tetapi ini adalah aturan umum.
Setelah pengubah “i”, Anda akan melihat serangkaian angka dan huruf yang akan memberi Anda detail yang lebih baik dari chip yang diberikan. Dua angka pertama akan memberi tahu Anda dari generasi mana chip itu berasal, jadi prosesor Core i7-1065G7 akan menjadi chip generasi ke-10, sedangkan prosesor Core i7-1165G7 akan menjadi generasi ke-11. Dua angka kedua akan memberi tahu Anda seberapa cepat chip apa pun dalam barisan tertentu. Jadi, Core i7-1165G7 tidak akan secepat Core i7-1185G7, tetapi angka-angka itu tidak terlalu penting untuk kecepatan garis Core mana yang cocok dengan chip.
Akhirnya, di akhir string panjang itu, Anda memiliki akhiran lini produk, yang akan memberi tahu Anda kemampuan chip dan kasus penggunaan yang ideal. Anda dapat menemukan semua sufiks di sini , tetapi ada beberapa yang penting untuk diketahui sebelum memasukkan komputer ke keranjang Anda. Jika Anda menginginkan laptop dengan grafis terintegrasi (tidak ada GPU terpisah), katakanlah untuk penjelajahan biasa atau hanya untuk menyelesaikan pekerjaan, Anda pasti ingin mencari chip yang memiliki akhiran “G”.
Di sisi lain, laptop dengan akhiran “F” akan membutuhkan grafis diskrit, yang berarti kartu grafis terpisah. Chip seri U dan Y dimaksudkan untuk konsumsi energi rendah, sehingga tidak akan sekuat beberapa chip kelas atas, dan ada beberapa chip lain yang mungkin tidak akan Anda temui untuk chip yang lebih spesifik seperti chip tinggi. -power yang mobile.
Chip desktop Intel memiliki beberapa sufiks sendiri, jika Anda ingin membuat PC sendiri. Misalnya, sebuah chip dengan akhiran K “tidak terkunci”, yang berarti Anda dapat melakukan overclock prosesor jika beban kerja Anda sangat berat. Sufiks X juga berarti tidak terkunci, tetapi chip ini akan mengemas lebih banyak keuletan daripada varietas K. CPU dengan akhiran F memerlukan kartu grafis diskrit karena tidak memiliki grafis terintegrasi.
Hal-hal dengan garis prosesor Pentium dan Celeron entry-level sedikit lebih sederhana, tetapi tidak terlalu jauh dari klasifikasi chip Core. Chip Pentium dimulai dengan awalan satu huruf, diikuti dengan nomor model empat digit, lalu akhiran. Semakin tinggi angkanya, semakin baik kinerjanya. Chip Pentium Gold akan difokuskan pada kecepatan cepat, sedangkan Pentium SIlver akan lebih condong ke arah efisiensi biaya. Intel tidak memberikan banyak info tentang prosesor Celeron, tetapi hal yang sama berlaku semakin tinggi jumlah chip yang diberikan, semakin cepat kecepatannya, meskipun prosesor Celeron tidak akan seefisien chip Pentium Silver.
AMD
AMD mungkin tidak ada di mana-mana seperti Intel, tetapi chipnya masih dapat ditemukan di beberapa laptop terkenal, jadi ada baiknya memahami cara chipnya diklasifikasikan. Untungnya, ini sedikit lebih ramping dan lebih mudah dipahami daripada Intel.
Di kelas atas, Anda memiliki jajaran Ryzen , yang dapat ditemukan di desktop dan laptop. Chip Ryzen terbagi dalam lima kategori: Ryzen 3, 5, 7, 9, dan Threadripper.
Setiap chip disertai dengan nomor model semakin tinggi semakin baik untuk mendapatkan gambaran yang lebih baik tentang seberapa cepat setiap chip dalam kelas tertentu. X yang ditempelkan di akhir angka itu hanya berarti itu sedikit lebih cepat. Misalnya, jika Anda mencari chip murah, AMD menawarkan dua opsi: Ryzen 3 3100 dan Ryzen 3 3300X, yang terakhir lebih cepat dari keduanya.
Chip Ryzen 3 , semuanya mengemas empat inti dan hingga delapan utas, sedangkan Ryzen 5 akan memberi Anda enam inti dan 12 utas. Ryzen 7 menabrak hingga delapan core dan 16 thread, dan chip Ryzen 9 akan membawa Anda ke 16 core dan 32 thread.
Lalu, ada Threadripper yang diberi nama tepat, yang mengemas pukulan kasar dengan opsi inti mulai dari 24 hingga 128 utas, jika kasus penggunaan Anda memerlukan penggilingan yang serius.
Semuanya hampir sama dengan chip laptop AMD, tetapi ada beberapa perbedaan yang harus diwaspadai. Setiap chip dengan akhiran G akan memiliki kartu grafis AMD Radeon terintegrasi di dalamnya, sementara akhiran GE menunjukkan bahwa chip tersebut berdaya rendah dan memiliki grafis terintegrasi. Jika Anda melihat H di akhir, itu adalah chip seluler berkinerja tinggi, U untuk seluler standar, dan M menunjukkan daya rendah.
AMD juga memiliki jajaran CPU super-budget yang disebut Athlon . Anda akan menemukan prosesor ini sebagian besar di Chromebook, dan ada tiga varietas berbeda: Dua “emas” dan satu “perak”. Seperti yang Anda duga, emas lebih cepat dari keduanya—prosesor emas adalah 4-core/4-thread, dan perak adalah 2-core/4-thread.
![]()
![]()
![]()
![]()
![]()
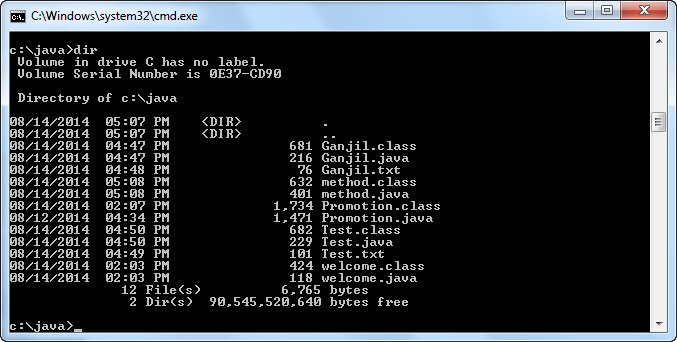
Bagaimana Proses Menjalankan Program Java Di CMD
Bagaimana Proses Menjalankan Program Java Di CMD – Ada banyak cara di mana Anda dapat menjalankan program Java. Namun, menurut para ahli di bidangnya, cara terbaik untuk menjalankan program Java adalah dengan melakukannya melalui CMD prompt. Ingin tahu bagaimana melakukannya?
Bagaimana Proses Menjalankan Program Java Di CMD

zorba-xquery – Jangan khawatir kami mendukungmu. Di sini, di blog ini, kami akan memberi tahu Anda semua yang perlu Anda ketahui tentang menjalankan program Java di CMD. Untuk membantu Anda memahami nuansa proses dengan cara yang lebih baik, kami telah membagi blog menjadi beberapa segmen berikut-
Java dimaksudkan untuk memiliki tampilan dan nuansa bahasa pemrograman C++, namun lebih mudah untuk menggunakan dan mempertahankan model pemrograman yang diatur item. Java dapat digunakan untuk membuat aplikasi total yang dapat tetap berjalan pada satu PC atau diedarkan di antara server dan pelanggan dalam suatu sistem. Hal ini juga dapat digunakan untuk membuat modul aplikasi kecil atau applet untuk digunakan sebagai bagian utama dari sebuah halaman web.
Baca Juga : Mengapa Java Begitu Populer Bagi Para Pengembang Dan Pemrogram
Pengembangan program Java memerlukan unit peningkatan pemrograman Java (SDK) yang secara teratur menggabungkan kompiler, penerjemah, generator dokumentasi, dan berbagai instrumen yang digunakan untuk membuat aplikasi yang lengkap. Waktu pengembangan dapat dipercepat menggunakan situasi kemajuan terkoordinasi (IDE) -, misalnya, JBuilder, Netbeans, Eclipse, atau JCreator. IDE mendorong kemajuan GUI, yang menggabungkan tangkapan, kotak konten, papan, garis besar, bilah gulir, dan berbagai artikel menggunakan aktivitas yang disederhanakan dan tunjuk dan klik.
Program yang dibuat di Java menawarkan keserbagunaan dalam sebuah sistem. Kode sumber diurutkan ke dalam apa yang disebut Java sebagai bytecode, yang dapat dijalankan di mana saja dalam sistem, pada server, atau pada pelanggan yang memiliki mesin virtual Java (JVM).
JVM menguraikan bytecode menjadi kode yang akan terus berjalan pada peralatan PC. Menariknya, sebagian besar dialek pemrograman, misalnya, COBOL atau C++, akan mengurutkan kode ke dalam catatan ganda.
Dokumen paralel bersifat eksplisit, sehingga program yang dibuat untuk mesin Windows yang disatukan oleh Intel tidak dapat menjalankan Mac, perangkat berbasis Linux, atau komputer terpusat IBM. Sebagai pilihan yang berbeda dengan menerjemahkan satu panduan bytecode sekaligus, JVM menggabungkan kompiler discretionary in nick of time (JIT) yang secara progresif mengatur bytecode menjadi kode yang dapat dieksekusi. Umumnya,
Apa itu Command Prompt?
Command Prompt adalah aplikasi penerjemah jalur langsung yang dapat diakses di banyak kerangka kerja Windows. Ini digunakan untuk mengeksekusi petunjuk yang dimasukkan. Sebagian besar dari arahan tersebut mengkomputerisasi bisnis menggunakan konten dan dokumen cluster, melakukan peningkatan kapasitas otoritas, dan menyelidiki atau menyelesaikan jenis masalah Windows tertentu.
Command Prompt secara resmi disebut Windows Command Processor, tetapi juga kadang-kadang disebut sebagai shell perintah atau singkatan cmd, atau bahkan dengan nama filenya, cmd.exe
Command Prompt adalah beberapa waktu yang secara keliru disinggung sebagai “DOS brief” atau sebagai MS-DOS itu sendiri. Command Prompt adalah program Windows yang meniru sejumlah besar kapasitas garis arah yang dapat diakses di MS-DOS, tetapi itu bukan MS-DOS.
Anda membuka Command Prompt melalui Command Prompt, rute mudah yang terletak di menu Start atau di layar Aplikasi, bergantung pada versi Windows Anda.
Cara lain untuk mengakses Command Prompt adalah menggunakan perintah Run cmd atau di area uniknya di C:\Windows\system32\cmd.exe, namun menggunakan rute alternatif lebih cepat bagi banyak orang.
Perintah singkat itu sendiri sebenarnya adalah program CLI yang dapat dieksekusi, cmd.exe. Pada arahan singkat, klien mengetikkan pengumuman termasuk catatan klaster dasar atau nama pesanan dan setiap pertentangan untuk menentukan kondisi berjalan, pencatatan, dll. untuk program.
Memesan antarmuka singkat bisa menjadi luar biasa dan ringkas, dan beberapa perangkat yang tidak dapat diakses melalui GUI dapat diakses melaluinya. Mereka juga menawarkan robotisasi umum melalui skrip, tetapi mungkin menunjukkan harapan yang tinggi untuk belajar dan beradaptasi dengan informasi utama perintah.
Memahami Program Java
Untuk menjalankan Program Java, perlu ditulis dengan benar. Oleh karena itu, mari kita lihat lebih dekat detail menit dari program Java.
public class FirstJavaProgram {
Ini adalah baris utama dari setiap program java. Setiap aplikasi Java setidaknya harus memiliki satu definisi kelas yang terdiri dari semboyan kelas yang diikuti oleh nama kelas. Ketika saya menyebutkan semboyan, itu berarti bahwa itu tidak boleh diubah, kita harus menggunakannya untuk apa yang layak. Juga, nama kelas bisa apa saja yang kamu mau
Saya telah membuat kelas terbuka dengan memanfaatkan pengubah gratis; Saya akan membahas pengubah get to di posting yang berbeda, semua yang harus Anda ketahui karena dokumen Java dapat memiliki sejumlah kelas namun hanya dapat memiliki satu kelas terbuka dan nama rekaman harus sama dengan nama kelas publik.
public static void main(String[] args) {
Ini seharusnya menjadi baris berikutnya dalam program; kami akan memecahnya untuk memahaminya dengan lebih baik:
Publik: Ini membuat prinsip strategi terbuka yang menyiratkan bahwa kita dapat memanggil teknik dari luar kelas.
KOMPILER JDK
Sementara banyak kondisi pemrograman akan memungkinkan Anda untuk memesan dan menjalankan program di bumi, Anda juga dapat merakit dan menjalankan menggunakan Command Prompt. Kedua jendela dan Mac memiliki versi Command Prompt mereka sendiri, meskipun sebenarnya disebut Terminal di Mac OS. Prosedur ini pada dasarnya tidak dapat dibedakan untuk Windows dan Mac.
Sebelum Anda dapat menjalankan program Java di PC Anda, Anda harus memperkenalkan kompiler Java. Itu menyertai Java Development Kit atau JDK. Ini adalah perangkat dasar untuk membuat di Java pada tahap apa pun. JDK tidak sama dengan Java Runtime Environment, atau JRE, yang sekarang telah Anda perkenalkan jika Anda pernah menggunakan aplikasi Java di komputer Anda.
![]()
![]()
![]()
![]()
![]()

Mengapa Java Begitu Populer Bagi Para Pengembang Dan Pemrogram
Mengapa Java Begitu Populer Bagi Para Pengembang Dan Pemrogram – Bahkan juga saat makin bertambah bahasa pemrograman berkembang, Java nampaknya makin menyebar luas dari tahun ke tahun . Maka, kenapa masih terkenal sesudah 22 tahun?
Mengapa Java Begitu Populer Bagi Para Pengembang Dan Pemrogram

zorba-xquery – Sesudah rayakannyaulang tahun ke 22 pada tahun 2017, Java sudah alami peningkatan yang stabil dalam efektivitas pemrograman sepanjang beberapa dasawarsa. Ini merupakan salah satunya bahasa pemrograman terpopuler di penjuru dunia dan direncanakan untuk selalu berjalan pada tiap bagian secara stabil.
Kenapa Jawa demikian terkenal?
Salah satunya dalih paling besar kenapa Java demikian terkenal ialah independensi basis. Program bisa berjalan di sejumlah ragam computer yang berbeda; sepanjang computer mempunyai Java Runtime Environment (JRE) terinstal, program Java bisa berjalan didalamnya.
Baca Juga : Tips untuk Mengoptimalkan Kinerja Kode Java
Mayoritas ragam computer akan cocok dengan JRE terhitung PC yang berjalan pada Windows, computer Macintosh, computer Unix atau Linux, dan computer mainframe besar, dan handphone.
Karena telah ada berlama-lama, sejumlah organisasi paling besar di dunia dibuat memakai bahasa itu. Beberapa bank, retail, perusahaan asuransi, utilitas, dan pabrikasi segalanya memakai Java.
Steve Zara, seorang programmer sepanjang lebih dari 40 tahun, menerangkan seperti diketahui ada indikasi Java turun pemakaiannya. Kebalikannya, ini merupakan bahasa yang berkembang yang nyaris secara unik menyatukan kestabilan dengan pengembangan.
Menerangkan usia panjang bahasa, Zaramenyatakanbahwa code yang barangkali sudah Anda catat 15 tahun lalu akan jalan pada JVM terkini dan memperoleh keuntungan kecepatan dari pembikinan profile terkini, penafsiran code asli, dan management memory.
Java pada intinya fokus object. Code ini sangat tangguh karena object Java tidak berisi rekomendasi ke data di luar dirinya.
Bahasanya dinilai amat sederhana; akan tetapi, dia datang dengan perpustakaan kelas yang tawarkan peranan utilitas yang biasa dipakai yang mayoritas program Java tak dapat bekerja tanpa dia.
Java API, perpustakaan kelas, ialah sisi dari Java seperti bahasa tersebut. Pada realitanya, rintangan sejati pelajari langkah memakai Java bukan pelajari bahasanya, tapi pelajari API.
Bahasa ini terbagi dalam 50 ugkap kunci, tapi Java API mempunyai beberapa ribu kelas dengan beberapa puluh ribu sistem yang bisa Anda pakai dalam program Anda.
Meski begitu, pengembang tidak diharap untuk pelajari semua Java API, dan mayoritas pada mereka cuma eksper dan pintar dengan sejumlah kecil saja.
Apa Java patut didalami?
Java masih adalah bahasa pemrograman yang berkaitan yang tak menampilkan indikasi pengurangan reputasi dan, oleh oleh sebab itu, patut untuk didalami. Mayoritas pengembang ambilnya sebagai bahasa pemrograman pertama mereka karena lumayan gampang didalami.
Karena bahasa itu mempunyai sintaksis seperti bahasa Inggris dengan watak khusus minimal, Java bisa didalami dalam bentang saat yang singkat dan dipakai untuk membuat program yang cocok.
Java ialah sisi dari keluarga bahasa yang amat diakibatkan oleh C++ (sekaligus C#), oleh oleh sebab itu pelajari Java tawarkan banyak faedah saat pelajari dua bahasa yang lain.
Swarnim Srivastava, seorang Java Enthusiast, sepakat jika bahasa itu patut untuk didalami. Ia menerangkan tempat krisis di mana dia dipakai:
Membuat program Android
Walau ada langkah lain untuk membikin program Android, mayoritas program dicatat dalam Java memakai API Android Google. Walau Android memakai JVM dan sistem pengepakan yang lain, kodenya masih dikuasai Java.
Program situs Java
Banyak departemen pemerintahan, kesehatan, asuransi, pengajaran, dan benteng mempunyai program situs yang dibuat di Jawa. Contoh krusial dari hal ini merupakan Gmail Google.
Alat piranti lunak
Banyak piranti lunak dan alat peningkatan yang bermanfaat dicatat dan diperkembangkan di Java, misalkan Eclipse, IntelliJ IDEA dan NetBeans IDE.
Program ilmiah
Sekarang ini, Java kerap jadi opsi standar untuk program ilmiah, terhitung pemrosesan bahasa alami. Dalih intinya ialah karena aman, portabel, bisa dipiara, dan memiliki fasilitas alat konkurensi tingkat tinggi yang lebih bagus ketimbang C++ atau bahasa yang lain.
Bergantung pada prospect karier Anda, Java bisa bawa Anda ke lajur karier yang lain. Baik Anda terpikat untuk membikin games, program mobile, program desktop, atau program situs, Java sanggup bekerja di lingkungan ini.
Lepas dari apa Anda memakai Java dalam karier atau peranan aktivitas Anda atau pergi, Anda akan pelajari sintaks, gagasan, skema, alat, style, dan kelebihan yang dapat ditransfer ke bahasa pemrograman lain.
Belajar Java akan memberikan Anda peluang untuk menyaksikan bagaimana satu bahasa membuat suatu hal dibanding dengan lainnya. Apalagi, ketahui apa yang berperan untuk Java dan bahasa lain akan membuat Anda jadi pengembang yang lebih bagus.
![]()
![]()
![]()
![]()
![]()

Tips untuk Mengoptimalkan Kinerja Kode Java
Tips untuk Mengoptimalkan Kinerja Kode Java – Saat mengerjakan aplikasi Java apa pun, kami menemukan konsep pengoptimalan. Kode yang kita tulis perlu tidak hanya bersih, dan tanpa cacat tetapi juga dioptimalkan yaitu waktu yang dibutuhkan oleh kode untuk mengeksekusi harus berada dalam batas yang diinginkan. Untuk mencapai ini, kita perlu mengacu pada standar pengkodean Java dan meninjau kode kita untuk memastikannya sesuai standar.
Tips untuk Mengoptimalkan Kinerja Kode Java

zorba-xquery – Namun terkadang kami tidak memiliki waktu untuk benar-benar meninjau kode karena batasan tenggat waktu. Dalam kasus seperti itu, kami memberikan beberapa tip yang dapat diingat oleh pengembang saat melakukan pengkodean persyaratan apa pun sehingga ia perlu membuat sedikit perubahan pada kode untuk memperbaiki kinerja selama fase pengujian atau sebelum memindahkannya ke produksi.
Hindari Menulis Metode Panjang
Metode tidak boleh terlalu panjang dan harus spesifik untuk melakukan fungsionalitas tunggal. Lebih baik untuk pemeliharaan serta kinerja karena saat pemuatan kelas dan selama pemanggilan metode, metode tersebut dimuat dalam memori tumpukan. Jika metode berukuran besar dengan terlalu banyak pemrosesan, mereka akan menghabiskan memori serta siklus CPU untuk dieksekusi.
Baca Juga : Keterampilan yang Dapat Dipelajari Pemrogram Java
Cobalah untuk memecah metode menjadi yang lebih kecil pada poin logis yang sesuai. Juga, jika Anda ingin memperkuat keterampilan Anda di Java, daftarkan diri Anda di Geeksforgeeks Java Programming Foundation – kursus Self-Paced dan pelajari konsep dasar, tipe data, operator, fungsi & lainnya.
Hindari Beberapa Pernyataan If-else
Kami menggunakan pernyataan bersyarat dalam kode kami untuk pengambilan keputusan. Pernyataan bersyarat tidak boleh digunakan secara berlebihan. Jika kita menggunakan terlalu banyak pernyataan if-else bersyarat, itu akan memengaruhi kinerja karena JVM harus membandingkan kondisinya. Ini bisa menjadi lebih buruk jika hal yang sama digunakan dalam pernyataan perulangan seperti untuk, sementara, dll.
Jika ada terlalu banyak kondisi dalam logika bisnis Anda, cobalah untuk mengelompokkan kondisi dan mendapatkan hasil boolean dan menggunakannya dalam pernyataan if. Juga, kita dapat memikirkan untuk menggunakan pernyataan switch alih-alih beberapa if-else jika memungkinkan. Pernyataan switch memiliki keunggulan kinerja dibandingkan if – else.
Hindari Menggunakan Objek String Untuk Penggabungan
String adalah kelas yang tidak dapat diubah, objek yang dibuat oleh String tidak dapat digunakan kembali. Jadi, jika kita perlu membuat string besar jika ada kueri SQL, dll., adalah praktik yang buruk untuk menggabungkan objek String menggunakan operator ‘+’.
Ini akan menyebabkan beberapa objek String dibuat yang mengarah ke lebih banyak penggunaan memori tumpukan. Dalam hal ini, kita dapat menggunakan StringBuilder atau StringBuffer, yang pertama lebih disukai daripada yang terakhir karena memiliki keunggulan kinerja karena metode yang tidak disinkronkan.
Gunakan Tipe Primitif Sedapat Mungkin
Penggunaan tipe primitif di atas objek bermanfaat karena tipe data primitif disimpan di memori tumpukan dan objek disimpan di memori tumpukan. Jika memungkinkan, kita dapat menggunakan tipe primitif daripada objek karena akses data dari memori tumpukan lebih cepat daripada memori tumpukan. Jadi selalu bermanfaat untuk menggunakan int over Integer atau double over Double.
Hindari Menggunakan Kelas BigDecimal
Kita tahu bahwa kelas BigDecimal memberikan presisi yang akurat untuk nilai desimal. Penggunaan berlebih dari objek ini menghambat kinerja secara drastis khususnya ketika hal yang sama digunakan untuk menghitung nilai-nilai tertentu dalam satu lingkaran.
BigDecimal menggunakan banyak memori lebih lama atau dua kali lipat untuk melakukan perhitungan. Jika presisi bukan kendala atau jika kami yakin kisaran nilai yang dihitung tidak akan melebihi panjang atau ganda, kami dapat menghindari penggunaan BigDecimal dan menggunakan long atau double dengan casting yang tepat sebagai gantinya.
Hindari Sering Membuat Objek Besar
Ada kelas-kelas tertentu yang bertindak sebagai pemegang data dalam aplikasi. Benda-benda ini berat dan pembuatannya harus dihindari beberapa kali. Contoh objek tersebut adalah objek koneksi DB atau objek konfigurasi sistem atau objek sesi untuk pengguna setelah login.
Objek-objek ini menggunakan banyak sumber daya saat dibuat. Kita harus menggunakan kembali objek-objek ini alih-alih membuatnya karena pembuatan akan secara drastis menghambat kinerja aplikasi karena penggunaan memori yang lebih banyak. Kita harus menggunakan pola Singleton sedapat mungkin untuk membuat satu instance objek dan menggunakannya kembali di mana pun diperlukan atau mengkloning objek alih-alih membuat yang baru.
Gunakan Prosedur Tersimpan Alih-alih Query
Lebih baik menulis prosedur tersimpan daripada kueri yang rumit dan panjang dan memanggilnya saat memproses. Prosedur tersimpan disimpan sebagai objek dalam database dan telah dikompilasi sebelumnya.
Waktu eksekusi prosedur tersimpan lebih sedikit dibandingkan dengan kueri dengan logika bisnis yang sama saat kueri dikompilasi dan dieksekusi setiap kali di mana pun ia dipanggil melalui aplikasi. Selain itu, prosedur tersimpan memiliki keuntungan dalam transfer data dan lalu lintas jaringan karena kami tidak mentransfer kueri kompleks untuk dieksekusi setiap kali ke server basis data.
Menggunakan Pernyataan Siap alih-alih Pernyataan
Saat menjalankan kueri SQL melalui aplikasi, kami menggunakan JDBC API dan kelas untuk hal yang sama. PreparedStatement memiliki keunggulan dibandingkan Statement untuk eksekusi kueri berparameter karena objek readystatement dikompilasi satu kali dan dieksekusi beberapa kali.
Objek pernyataan di sisi lain dikompilasi dan dieksekusi setiap kali dipanggil. Juga , objek pernyataan yang disiapkan aman untuk menghindari serangan injeksi SQL untuk keamanan Aplikasi Web.
![]()
![]()
![]()
![]()
![]()

Keterampilan yang Dapat Dipelajari Pemrogram Java
Keterampilan yang Dapat Dipelajari Pemrogram Java – Artikel ini benar-benar konsentrasi pada pemikiran kenaikan Java dan saya menyebutkan Anda sudah mengusai pada beberapa hal penting seperti Coding , Data Structures and Algorithms , dan gagasan pengetahuan komputer seperti Networking, Protocols, Object-oriented programming , dan sebagainya.
Keterampilan yang Dapat Dipelajari Pemrogram Java

zorba-xquery – Beberapa strategi ini sama berguna untuk pengembang Core Java, destinasi saya pribadi Java yang menulis program sisi server tetapi tidak begitu ikut serta dengan kapabilitas kenaikan situs seperti JSP , Servlet , dan JEE , dan untuk pengembang Situs Java yang aktivitas pokoknya adalah menulis program situs menggunakan teknologi Java.
Walau sebenarnya, aku sudah pergi dari banyak hal situs seperti belajar JSF atau Servlet 4.0 untuk hari lain supaya tabel ini masih tetap singkat dan simpel. Ngomong-ngomong, tanpa basa-basi kembali, berikut beberapa ketrampilan, panduan, dan anjuran menjadi pengembang Java yang lebih bagus pada tahun 2020.
Baca Juga : Tips Mudah Menjadi Programmer Java Di Tahun 2022
Bila Anda ingin percepat karier Anda dan jadi programmer Java yang lebih bagus, ini merupakan ketrampilan yang hendak menjadi perbedaan Anda dari programmer lain.
Dalami Design dan Arsitektur Piranti Lunak
Design dan arsitektur piranti lunak dapat disebut adalah babak paling penting dari metode peningkatan piranti lunak. Sanggup menyaksikan deskripsi besar dan pikirkan problem yang dilawan, dan putuskan arsitektur dan timbunan tehnologi yang pas untuk menerapkan program Anda ialah ketrampilan krusial untuk pengembang piranti lunak mana saja, tidak cuma pengembang Java.
Bila Anda ingin percepat karier Anda pada tahun 2020 dan ingin jadi perusahaan pengembang Java senior yang dicari, aku anjurkan Anda belajar Arsitektur Piranti Lunak. Bila Anda memiliki cita-cita jadi seorang arsitek jalan keluar karena itu ketrampilan ini pun bisa banyak menolong Anda dan menjadi perbedaan dari pengembang lain.
Bila Anda membutuhkan sumber daya untuk pelajari beberapa hal dasar mengenai design dan Arsitektur Piranti Lunak, karena itu aku anjurkan Anda mengecek pelatihan Program Situs dan Arsitektur Piranti Lunak 101 mengenai Eductive. Ini merupakan pelatihan yang apik untuk pelajari skema arsitektur yang lain seperti Microservice, client-server, dan program terbagi.
Sebenarnya, ini merupakan pelatihan terbaik untuk tak cuma pengembang senior tapi juga tiap pengembang piranti lunak di luaran sana karena ini bakal meluaskan metode berpikiran Anda dan akan membuat pengembang situs lebih optimis. Ada potongan harga yang berarti untuk pelatihan saat ini, dan ada cukup dengan $44, harga asli $79, cukup mahal untuk pelatihan Udemy tapi sebanding.
Di lain sisi, bila Anda menyenangi Mendidik sebagai basis, Anda pun bisa beli berlangganan cukup dengan $17 /bulan ( potongan harga 50% ) , aku punyai satu, dan aku amat memberi saran Anda untuk memperolehnya.
Dalami alat Container dan DevOps (Jenkins, Docker, dan Kubernetes)
Untuk pengembang Java kekinian, pengetahuan mengenai DevOps amat krusial. Ia paling tidak harus terlatih dengan integratif terus-menerus dan implementasi terus-menerus dan bagaimana Jenkins menolong meraihnya.
Ini jadi lebih krusial kembali untuk pengembang Java senior yang kerap bertanggungjawab untuk atur praktek terbaik pengkodean dan membangun lingkungan, membuat skrip dan dasar.
Aku memberi saran Anda habiskan waktu dan pelajari selanjutnya mengenai DevOps pada umumnya dan beberapa alat seperti Docker , Chef, Kubernetes, dan lain-lain bersama dengan Maven dan Jenkins.
Bila Anda membutuhkan sejumlah sumber daya, Dalami DevOps: CI/CD dengan Jenkins memakai Pipelines dan Docker di Udemy barangkali ialah pelatihan terbaik untuk mengawali. Anda tak hanya akan belajar mengenai CI dan CD tapi juga mengenai Maven dan Jenkins secara dalam.
Dalami Rangka Musim Semi (Sepatu Musim Semi)
Sekarang ini nyaris krusial untuk pengembang Java untuk pelajari rangka kerja Spring karena mayoritas perusahaan lebih sukai membuat peningkatan memakai rangka kerja Spring seperti Spring MVC , Spring Boot, dan Spring Cloud untuk meningkatkan program situs, REST APIs Microservices.
Ini pun mempromokan praktek terbaik seperti injeksi keterikatan dan membuat program Anda dapat lebih dites yang adalah syarat khusus untuk piranti lunak kekinian.
Bila Anda seorang pengembang Java anyar karena itu aku anjurkan Anda untuk mengawali dengan panduan Java dan Spring ini untuk pelajari beberapa dasar rangka kerja yang sangat hebat ini apabila Anda telah terlatih dengan Spring karena itu Anda harus menelusuri Spring Boot dan Spring Cloud untuk meningkatkan Java angkatan selanjutnya. program.
Bila Anda cari beberapa rekomendasi, karena itu Spring Frame-work 5: Beginner to Guru ialah pelatihan terbaik untuk mengawali.
Dalami Pengetesan Unit (JUnit dan Mockito)
Bila terdapat sebuah hal biasa yang menjadi perbedaan pengembang Java yang bagus dari pengembang Java rerata, karena itu itu merupakan ketrampilan pengetesan unit.
Pengembang Java yang bagus dan professional nyaris sering menulis test unit untuk kodenya apabila ia betul-betul pengembang Rockstar, Anda bisa menyaksikannya dari code dan pengetesannya.
Pengetesan sudah berkembang cepat saat ini dengan beberapa alat untuk pengetesan unit, pengetesan integratif, dan pengetesan mekanisasi yang ada untuk pengembang Java.
Anda bisa habiskan banyak tahun 2020 untuk mempertajam ketrampilan pengetesan Anda di Java tapi mereka yang anyar mengenali dunia Java dan pengetesan unit, JUnit ialah perpustakaan terbaik untuk mengawali. Versus terkini JUnit 5 kuat dan fleksibel dan tiap pengembang Java harus ketahuinya.
Bila Anda cari rangkuman yang apik mengenai JUnit dan pengetesan unit di Java, karena itu Pelatihan Singkat JUnit dan Mockito ialah pelabuhan yang prima untuk mengawali. Ini bukanlah yang terkini karena tidak meliputi JUnit 5 namun tetap cukup bermanfaat untuk yang baru memulai.
Dalami API dan Perpustakaan
Bila Anda sudah bekerja dengan pengembang Java yang luar biasa, Anda barangkali sudah mengamati pengetahuan mereka keseluruhannya mengenai Ekosistem Java dan API adalah sisi khusus darinya.
Java ialah bahasa pemrograman terpopuler dan masak di dunia dan ada beberapa perpustakaan dan API yang ada untuk membuat sebagian besar sesuatu yang barangkali.
Tentunya, Anda tidak diharap untuk ketahui segalanya, tapi Anda harus terlatih dengan beberapa API khusus seperti API pemrosesan JSON seperti Jackson dan Gson , API pemrosesan XML seperti JAXB dan Xerces, Pustaka pengetesan unit seperti Mockito dan JUnit dan lain-lain.
Bila Anda tidak ketahuinya, Anda bisa pelajarinya atau paling tidak memperoleh gambaran singkat mengenainya di tahun 2020. Untuk mengawali, Anda bisa menyaksikan tabel 20 perpustakaan Java aku yang penting dipahami oleh tiap pengembang Java , yang meliputi perpustakaan dari tempat khusus seperti parsing, bytecode kecurangan, konkurensi, koleksi, dan lain-lain.![]()
![]()
![]()
![]()
![]()
Tips Mudah Menjadi Programmer Java Di Tahun 2022
Tips Mudah Menjadi Programmer Java Di Tahun 2022 – Aku kerap terima e-mail dari pembaca aku mengenai bagaimana mereka dapat dijadikan pengembang Program Java yang lebih bagus, beberapa hal apa yang perlu mereka dalami, dan sektor yang mana bisa mereka lakukan menjadi pengembang Di Java Rockstar.
Tips Mudah Menjadi Programmer Java Di Tahun 2022

zorba-xquery – Akan tetapi, saat sebelum mengulasnya, aku ingin mengutamakan jika programmer yang lebih bagus sering adalah pengembang Program Java yang lebih bagus dan itu merupakan kenapa semua panduan yang sudah aku bagi awalnya untuk menaikkan ketrampilan pemrograman Anda dan jadi programmer yang lebih bagus masih berlaku.
Bila Anda belum membacanya, Anda bisa membacanya sesudah artikel ini, mereka akan menolong Anda menaikkan ketrampilan pemrograman dan pengkodean Anda yang krusial menjadi pengembang Java yang lebih bagus.
Baca Juga : Bahasa Kode : Mengapa Bahasa Inggris adalah Lingua Franca Pemrograman
Artikel ini betul-betul fokus pada sudut pandang peningkatan Java dan aku menyebut Anda telah mengusai dalam beberapa hal krusial seperti Coding , Data Structures and Algorithms , dan ide pengetahuan computer seperti Jaringan, Prosedur, Pemrograman fokus object, dan lain-lain.
Beberapa kiat ini sama bermanfaat untuk ke-2 pengembang Core Java, tujuan aku semua orang Java yang menulis program segi server tapi tak begitu turut serta dengan ketrampilan peningkatan situs seperti JSP , Servlet , dan JEE , dan untuk pengembang Situs Java yang pekerjaan intinya ialah menulis program situs memakai tehnologi Java.
Padahal, saya telah meninggalkan beberapa hal web seperti belajar JSF atau Servlet 4.0 untuk hari lain agar daftar ini tetap singkat dan sederhana. Bagaimanapun, tanpa basa-basi lagi, berikut adalah beberapa tips dan saran untuk menjadi pengembang dan Insinyur Perangkat Lunak Java yang lebih baik.
Pelajari JVM Internal dan Java Performance Tuning
Jika Anda serius ingin menjadi Rockstar Java Developer maka Anda harus terlebih dahulu meluangkan waktu untuk mempelajari internal JVM seperti apa saja bagian-bagian yang berbeda dari JVM, cara kerjanya, JIT , JVM options , Garbage collections , dan collector, dll.
Jika Anda mengetahui JVM dengan baik, Anda dapat menulis aplikasi Java yang kuat dan berkinerja tinggi dan itulah yang dilakukan pengembang Rockstar Java.
Sebagai bagian dari ini, Anda juga harus mempelajari cara membuat profil aplikasi Java Anda, cara menemukan kemacetan kinerja seperti objek mana yang mengambil sebagian besar memori Anda, dan memakan CPU.
Untuk evaluasi terancang, aku mereferensikan The Definitive Guide to Java Performnce oleh Scott Oaks yang adalah buku apik yang sudah aku baca pada beberapa tahun akhir.
Untuk mereka yang lebih tertarik pelatihan online ketimbang buku, Pahami seri Java Virtual Machine di Pluralsight adalah koleksi luar biasa untuk kuasai intern JVM.
Omong-omong, Anda memerlukan keanggotaan Pluralsight untuk bergabung dengan kursus ini, dengan biaya sekitar $29 per bulan atau $299 per tahun (diskon 14%). Jika Anda tidak memiliki rencana ini, saya sangat merekomendasikan bergabung karena ini meningkatkan pembelajaran Anda dan sebagai seorang programmer, Anda selalu perlu mempelajari hal-hal baru.
Pelajari Layanan Mikro dan Cloud
Arsitektur terus berubah dan banyak perusahaan beralih dari aplikasi monolitik ke layanan mikro.
Sudah saatnya bagi pengembang Java untuk mempelajari arsitektur Layanan Mikro dan cara membuat Layanan Mikro di Jawa untuk memanfaatkan gelombang terbaru ini.
Untungnya, kerangka kerja Spring menyediakan Spring Cloud dan Spring Boot yang sangat menyederhanakan pengembangan layanan mikro di Jawa.
Jika Anda mencari kursus, maka Master Microservices dengan Spring Boot dan Spring Cloud adalah pilihan yang baik untuk memulai.
Dan, jika Anda lebih suka buku maka saya sarankan Anda memeriksa Cloud Native Java oleh Josh Long , yang menyediakan panduan komprehensif untuk mengembangkan aplikasi Java untuk cloud.
Pelajari Kerangka Musim Semi (Sepatu Musim Semi)
Saat ini hampir penting bagi pengembang Java untuk mempelajari kerangka kerja Spring karena sebagian besar perusahaan lebih suka melakukan pengembangan menggunakan kerangka kerja Spring seperti Spring MVC , Spring Boot , dan Spring Cloud untuk mengembangkan aplikasi web, REST API, dan Microservices .
Ini juga mempromosikan praktik terbaik seperti injeksi ketergantungan dan membuat aplikasi Anda lebih dapat diuji yang merupakan persyaratan utama untuk perangkat lunak modern.
Jika Anda seorang pengembang Java baru maka saya sarankan Anda memulai dengan tutorial Java dan Spring ini untuk mempelajari dasar-dasar kerangka kerja yang luar biasa ini dan jika Anda sudah terbiasa dengan Spring maka Anda harus menjelajahi Spring Boot dan Spring Cloud untuk mengembangkan aplikasi Java generasi berikutnya .
Jika Anda mencari beberapa referensi, maka Learn Spring Boot Rapid Spring Application Development oleh Dan Vega adalah tempat yang baik untuk memulai.
Pelajari Java API dan Library
Jika Anda telah bekerja dengan pengembang Java yang hebat, Anda mungkin telah memperhatikan pengetahuan mereka secara keseluruhan tentang Ekosistem Java dan API merupakan bagian utama darinya.
Java adalah bahasa pemrograman paling populer dan matang di dunia dan ada banyak perpustakaan dan API yang tersedia untuk melakukan hampir semua hal yang mungkin.
Tentu saja, Anda tidak diharapkan untuk mengetahui semuanya, tetapi Anda harus terbiasa dengan beberapa API utama seperti API pemrosesan JSON seperti Jackson dan Gson , API pemrosesan XML seperti JAXB dan Xerces, Pustaka pengujian unit seperti Mockito dan JUnit , dll.
Jika Anda tidak mengetahuinya, Anda dapat mempelajarinya atau setidaknya mendapatkan gambaran umum tentang mereka. Untuk memulainya, Anda dapat melihat daftar 20 perpustakaan Java saya yang harus diketahui oleh setiap pengembang Java , yang mencakup perpustakaan dari area utama seperti penguraian, manipulasi bytecode, konkurensi , koleksi , dll.![]()
![]()
![]()
![]()
![]()

Bahasa Kode : Mengapa Bahasa Inggris adalah Lingua Franca Pemrograman
Bahasa Kode : Mengapa Bahasa Inggris adalah Lingua Franca Pemrograman – Menurut Ethnologue: Languages of the World , katalog bahasa dunia, ada hampir 7.000 bahasa yang dikenal. Namun, bahasa Inggris tetap dominan sebagai standar de facto dalam ekonomi global, terutama dalam bisnis internasional.
Bahasa Kode : Mengapa Bahasa Inggris adalah Lingua Franca Pemrograman

zorba-xquery – Dalam dunia pemrograman komputer, bahasa Inggris tampaknya menjadi lingua franca untuk coding. Terlepas dari bahasa pemrograman aslinya, sebagian besar kata kunci masih dalam bahasa Inggris.
Baca Juga : 5 Bahasa Pemrograman Dasar (Pengertian, Jenis, dan Tips)
Evans Data Corporation, yang secara rutin melakukan survei mendalam terhadap populasi pengembang global, memperkirakan ada 23 juta pengembang perangkat lunak di seluruh dunia pada tahun 2018. Pada tahun 2023, mereka diproyeksikan menjadi 28 juta.
Sekitar 4,5 juta dari mereka berbasis di AS, dengan jumlah terbesar bekerja di Silicon Valley. Sekitar 70% dari pengembang ini lahir di luar AS. Sementara AS saat ini memiliki populasi pengembang perangkat lunak terbesar, populasi pengembang India akan menyusul AS pada tahun 2023. Negara teratas untuk pertumbuhan ada di China, di mana ia diproyeksikan tumbuh antara 6-8% menjelang tahun 2023.
Investasi asing baru-baru ini di bidang teknologi oleh perusahaan AS juga menyebar di luar Lembah Silikon ke pusat teknologi yang tumbuh paling cepat di Eropa seperti Berlin, Dublin, dan Paris. Pertumbuhan pesat China dalam teknologi canggih dan meningkatnya jumlah pengembang berbahasa China berpotensi mengubah status quo.
Salah satu proyek desain favorit kami adalah Root Robot , robot pendidikan yang dirancang khusus untuk memberikan cara interaktif bagi anak-anak untuk belajar coding. Dengan semakin pentingnya pendidikan STEM untuk kepemimpinan global, mau tidak mau kami bertanya-tanya apakah bahasa Inggris akan terus menjadi bahasa yang umum digunakan dalam pengembangan perangkat lunak.
DI MANA SEMUANYA DIMULAI
Charles Babbage, seorang ahli matematika, filsuf, penemu, dan insinyur mesin Inggris, mencetuskan konsep komputer yang dapat diprogram digital. Dianggap sebagai “bapak komputer”, ia menemukan komputer mekanis pertama di awal abad ke-19. Hal ini akhirnya menyebabkan desain elektronik yang lebih kompleks, yang membentuk semua ide penting dari komputer modern yang kita kenal sekarang.
Tokoh kunci lain dalam sejarah pemrograman komputer adalah Ada Lovelace, sezaman dengan Babbage. Dia sering disebut sebagai programmer komputer pertama di dunia. Putri penyair Lord Byron dan istri pertamanya, Anne Isabella Noel Byron, Lovelace adalah seorang ahli matematika yang brilian, seorang wanita di depan waktunya di tahun 1840-an. Dia terutama dikenal karena karyanya pada komputer tujuan umum mekanis yang diusulkan Babbage, Analytical Engine.
Lovelace adalah seorang visioner, yang pertama di antara rekan-rekannya untuk mengenali potensi penuh dari “mesin komputasi”. Dia menulis algoritma pertama yang dimaksudkan untuk dilakukan oleh mesin tersebut dan mengusulkan untuk menggunakan input data yang memprogram mesin untuk menghitung Bernoulli angka, yang sekarang dianggap sebagai program komputer pertama.Dia juga meramalkan bahwa mesin seperti Analytical Engine dapat digunakan untuk membuat musik, menghasilkan grafik, dan berguna untuk sains.
Untuk dua alasan ini saja, ada orang yang mungkin menggunakan ini sebagai argumen untuk pengkodean agar memiliki “garis keturunan Inggris” secara historis. Dan mereka tidak salah. Karya kolektif Babbage dan Lovelace sangat berpengaruh pada komputasi modern. Ada juga teori lain yang sangat diyakini (meskipun dianggap salah oleh sejarawan) bahwa kesamaan bahasa Inggris dalam pengkodean dimulai selama Perang Dunia II. Industri komputer memang tumbuh dari teknologi yang dikembangkan oleh Sekutu, kebanyakan digunakan oleh Amerika dan Inggris.
Dikatakan juga bahwa kebanyakan orang belajar bahasa Inggris untuk menggunakan bahasa pemrograman yang sudah ada, jadi itu berlanjut dengan nada yang sama saat membuat yang baru.
Dengan mencoba menggunakan bahasa lain untuk pengkodean, itu akan memotong komunikasi yang efektif antara programmer yang mayoritas sudah terbiasa dengan standar yaitu pengkodean dalam bahasa Inggris. Namun, ada gerakan dan advokasi yang berkembang untuk mengembangkan kode non-Inggris.
MEMBUAT KODE DALAM BAHASA INGGRIS
Sebagian besar kode baru sebenarnya dikembangkan oleh individu berbahasa Inggris. Tetapi tidak semua kode pemrograman dalam bahasa Inggris. Meskipun sebagian besar kata kunci ditulis dalam bahasa Inggris, komentar, kelas dan metode yang ditulis pengguna variabel sering kali dalam bahasa pemrogram sendiri.
Lebih dari sepertiga bahasa pemrograman dikembangkan di negara-negara berbahasa Inggris. Tetapi beberapa bahasa pengkodean yang terkenal dan banyak digunakan dikembangkan di negara-negara yang tidak berbahasa Inggris, misalnya Swiss (PASCAL), Denmark (PHP), Jepang (Ruby), Brasil (Lua), dan Belanda (Python).
Prancis mengembangkan bahasa pemrograman LSE (Langage Symbolique d’Enseignement – Symbolic Language for Teaching) berdasarkan kata kunci Prancis. Karena kurangnya pengetahuan bahasa Prancis, bahasa pemrograman itu akhirnya mati. Penggunaan bahasa Inggris untuk PASCAL merupakan reaksi atas kegagalan LSE.
KODE BICARA
Saat meneliti topik ini, kami juga telah membaca banyak forum pengembang untuk perspektif para ahli. Ini mengungkap banyak pendapat oleh programmer tentang mengapa mereka berpikir bahasa Inggris menang dalam pengkodean. Berikut beberapa kutipan pilihan:
“Memiliki kata kunci bahasa Inggris membuat pemrograman disarikan dari bahasa normal bagi kami…Kami TIDAK ingin kata kunci bahasa lokal untuk pemrograman. Siapa pun yang telah membuat bahasa pemrograman sendiri di universitas dan mencoba kata kunci lokal akan setuju dengan saya tentang betapa membingungkannya membaca kode.”
“Kata-kata bahasa Inggris lebih sering digunakan, berkat industri teknologi. Sebagian masalahnya adalah bahwa mengubah kata kunci saja tidak cukup. Tata bahasa asing akan membuat pernyataan yang diterjemahkan dengan hafalan membingungkan. Urutan kata bisa sangat berbeda dari satu bahasa ke bahasa lain. ” “ Di pasar ekonomi global yang telah menjadi perkembangan komputer, bahasa umum tampaknya paling masuk akal. ”
“Salah satu kesulitan dalam mengizinkan kata kunci untuk dialihkan dengan cepat ke bahasa lain adalah bahwa kata kunci harus ‘dipesan’ sehingga tidak dapat digunakan sebagai pengenal. Beralih bahasa dengan cepat akan menyebabkan serangkaian kata khusus yang berbeda ikut bermain dan memiliki potensi yang sangat kuat untuk menimbulkan konflik. ”
“ Bahasa Inggris memiliki keuntungan karena digunakan oleh ratusan juta orang. Bahasa yang menggunakan kata kunci non-Inggris mungkin tidak akan memiliki permintaan yang diperlukan untuk mendukungnya . Satu-satunya pengecualian tampaknya adalah orang Cina. Itu diucapkan oleh lebih banyak orang daripada bahasa Inggris, dan perbedaan besar antara bahasa Inggris dan Mandarin akan membuat belajar bahasa Inggris lebih menjadi penghalang bagi pembelajaran bahasa Mandarin untuk memprogram.”
![]()
![]()
![]()
![]()
![]()

5 Bahasa Pemrograman Dasar (Pengertian, Jenis, dan Tips)
5 Bahasa Pemrograman Dasar (Pengertian, Jenis, dan Tips) – Dalam artikel ini, kami mengikuti Sarah, seorang insinyur perangkat lunak yang bekerja dari jarak jauh, untuk menunjukkan kepada Anda seperti apa kehidupan seorang insinyur perangkat lunak sebenarnya, termasuk jam kerja, lingkungan kerja, dan tugas pekerjaan.
5 Bahasa Pemrograman Dasar (Pengertian, Jenis, dan Tips)

zorba-xquery – Pemrograman adalah proses membangun aplikasi atau perangkat lunak dengan tujuan tertentu. Dengan sebagian besar bisnis maju secara signifikan dalam aplikasi teknologi, memperoleh keterampilan komputer menjadi penting.
Baca Juga : 10 Bahasa Pemrograman Teratas Dunia
Belajar coding menggunakan bahasa pemrograman terbaik dapat membantu Anda mengelola proyek secara efisien dan membuat karier Anda sebagai pengembang perangkat lunak lebih memuaskan.
Dalam artikel ini, kami menemukan arti dari bahasa pemrograman dasar, membahas pentingnya mempelajari cara membuat kode, menjelajahi lima bahasa berbeda yang dapat Anda gunakan untuk mengembangkan aplikasi, dan menawarkan tip untuk mempelajari bahasa pemrograman baru.
Apa itu bahasa pemrograman dasar?
Bahasa pemrograman dasar mencakup satu set kosakata yang digunakan coders dalam pengembangan komputer dan perangkat lunak untuk membuat dan memelihara aplikasi, kueri, dan skrip untuk aplikasi yang berbeda. Komputer menggunakan berbagai bahasa untuk berkomunikasi.
Komputer hanya dapat memahami bahasa ini karena dalam format yang dapat dibaca mesin. Sebagai pengembang perangkat lunak, Anda dapat menggunakan satu bahasa untuk membuat kode untuk mengontrol mesin industri, untuk bertindak sebagai sistem titik penjualan untuk toko kelontong lokal, atau membuat aplikasi seluler untuk digunakan secara global.
Sama seperti bahasa kita, pemrograman memiliki sintaks, aturan, dan struktur dalam bahasanya. Bahasa dapat bekerja dalam kondisi tertentu atau kompatibel dengan sebagian besar sistem.
Selain penelitian dan pemeliharaan, pengkodean adalah elemen kunci dalam siklus pengembangan perangkat lunak. Sebagai pengembang, setelah Anda memahami cara menggunakan suatu bahasa, Anda dapat menulis kode sumber dalam editor teks, menjalankannya pada juru bahasa, atau mengompilasinya untuk dieksekusi.
Pentingnya mempelajari cara membuat kode
Berikut ini adalah beberapa manfaat mempelajari bahasa pemrograman dasar:
- meningkatkan jumlah kesempatan kerja
- mengarah ke promosi karir di dalam departemen atau organisasi Anda
- meningkatkan jumlah pendekatan yang dapat Anda gunakan untuk
- memecahkan masalah atau kebutuhan
- mengarah ke kontrak atau peluang sebagai pekerja lepas
- mengajarkan Anda bagaimana menggabungkan keterampilan teknis dan kreativitas
- membekali Anda dengan pengetahuan tentang cara kerja sistem perangkat lunak
- mengajarkan Anda ketekunan, fleksibilitas organisasi, dan keterampilan memecahkan masalah
5 bahasa pemrograman terbaik untuk dipelajari
Ada beberapa bahasa yang dapat Anda pelajari untuk memulai karir Anda sebagai programmer atau menambah keterampilan Anda yang sudah ada. Jika Anda seorang pemula, Anda dapat mengidentifikasi bahasa untuk memulai dan kemudian maju ke tingkat menengah.
Setiap bahasa memiliki kelebihan dan area penerapannya. Mengidentifikasi mereka dapat membantu Anda memutuskan bahasa mana yang akan dipelajari. Berikut adalah lima bahasa pemrograman dasar untuk dijelajahi:
1. Python
Ini adalah bahasa tingkat tinggi dan tujuan umum yang berfokus pada keterbacaan kode. Ini adalah salah satu bahasa pemula yang paling populer karena kemudahan penggunaannya, aplikasi yang luas, komunitas yang aktif, dan kebebasan penggunaan. Pemrogram dapat menggunakannya untuk tugas-tugas berorientasi objek, terstruktur, atau fungsional.
Python memiliki pustaka standar yang komprehensif, yang menjadikan bahasa tersebut sebagai judul “termasuk baterai.” Perpustakaan menyediakan alat untuk banyak tugas, seperti membuat aplikasi internet, antarmuka pengguna grafis, dan analisis data.
Kemudahan penggunaan bahasa ini karena sintaks dan tata bahasanya yang sederhana dan tidak berantakan dengan kebebasan metodologi selama pemrograman. Tidak seperti kebanyakan bahasa, python menggunakan kata-kata bahasa Inggris alih-alih tanda baca.
Ini juga memiliki lebih sedikit kasus luar biasa dan pengecualian sintaksis daripada bahasa C. Pengusaha dapat menggunakannya dalam teknologi informasi, teknik, layanan profesional, dan desain. Python membantu Anda bekerja cepat untuk mengintegrasikan sistem sebagai bahasa lem. Ini juga merupakan bahasa pengembangan aplikasi cepat (RAD) yang populer. Berikut ini adalah beberapa area aplikasi python:
- analisis data
- database
- dokumentasi
- pembelajaran mesin
- pengikisan web
- aplikasi seluler
- pengolahan citra
- jaringan komputer
- kerangka kerja web
- komputasi ilmiah
- sistem administrasi
2. Java
Pengembang sebagian besar menggunakan Java untuk antarmuka back-end aplikasi web atau antarmuka pemrograman aplikasi layanan umum (API) yang ditingkatkan oleh kerangka kerja seperti Spring dan Dropwizard. Java berbeda dari JavaScript karena ini adalah bahasa yang diketik dengan kuat, diterjemahkan ke kurva belajar yang lebih dalam.
Kompleksitas merupakan keunggulan yang membuat Java memiliki performa yang lebih tinggi. Java memaksakan kinerjanya dengan pekerjaan multi-utas yang dapat berjalan secara bersamaan. JavaScript hanya menggunakan satu utas. Java juga menyeimbangkan kompleksitas dan kinerja dengan menghindari banyak item yang dapat dikelola oleh pembuat kode dalam bahasa lain.
Pengembang juga menggunakan Java untuk membuat aplikasi android untuk ponsel. Mesin virtual Java memungkinkan bahasa untuk berjalan di banyak platform. Scala dan Kotlin juga berjalan di mesin virtual java, membuat semua bahasa ini kompatibel dan diperlukan untuk mengembangkan aplikasi seluler. Industri khusus seperti komputasi awan, internet elemen, dan arsitektur perusahaan menggunakan Java.
3. JavaScript
Ini adalah bahasa pemrograman paling populer di dunia. Coders terutama menggunakannya di world wide web untuk membuat antarmuka web atau situs web. Ini bisa menjadi bahasa yang mudah dipelajari. Pemrogram dapat mengklasifikasikan JavaScript sebagai bahasa tingkat tinggi, multi-paradigma, dan dikompilasi tepat waktu.
Ini fitur pengetikan dinamis, fungsi kelas satu, dan orientasi objek berbasis prototipe. JavaScript dapat menjadi enabler yang signifikan dari interaktivitas dan kekayaan situs web. Sementara HTML membangun fondasi untuk situs web, JavaScript mendorong situs web. JavaScript memiliki perpustakaan terkenal yang disebut JQuery yang digunakan oleh sebagian besar situs web.
Bahasa ini menjadi mudah untuk diadaptasi, terutama dengan pembuatan alat standar industri seperti VueJS yang ramah pemula dan reactJS tingkat tinggi. Dengan JavaScript, Anda dapat berkembang dalam bakat visual dan pengalaman pengguna yang luar biasa dalam pengembangan web.
Aplikasi bahasa pemrograman ini berjalan di luar front-end saja. Pengembang juga menggunakannya di back-end untuk memberi daya pada aplikasi seluler dan aplikasi web atau bertindak sebagai API mandiri untuk menggabungkan perusahaan dan layanan lain.
4. C and C++
C adalah bahasa tingkat rendah. Ini berarti bahwa pemrogram harus memahami perangkat keras komputer yang mendasarinya. Bahasa tingkat tinggi telah mengabstraksi detail komputer. Misalnya, saat menggunakan bahasa tingkat rendah, program Anda dapat menangani manajemen memori dalam kode. Biasanya, bahasa pemrograman yang lebih tinggi mengotomatiskan proses manajemen memori untuk komputer.
Meskipun C adalah level rendah, itu mengimbangi kinerja yang lebih baik daripada bahasa lain yang mudah dipelajari. Meskipun kinerja mungkin tidak menjadi perhatian yang signifikan untuk aplikasi media sosial, ini merupakan pertimbangan penting untuk aplikasi game, perangkat lunak efek khusus film, dan bagian dari sistem operasi.
C++ berasal dari C dan digunakan untuk menyederhanakan pemrograman, meskipun masih merupakan bahasa tingkat rendah. Anda dapat dengan mudah menerjemahkan program C ke C++. Sebagai perbandingan, coders dapat digunakan untuk embedded system, sedangkan C++ lebih terstruktur untuk pengembangan aplikasi.
Bjarne Stroustrup menciptakan C++ pada tahun 1985, 13 tahun setelah penemuan C. C dan C++ adalah salah satu bahasa pemrograman paling awal, yang berarti mempelajari bahasa ini dapat menempatkan Anda sebagai karyawan penting bahkan saat waktu berubah.
5. SQL
Structured Query Language (SQL) banyak digunakan untuk query data. Komputer mengirim kueri data SQL ke server yang merespons dengan data yang diminta. SQL memungkinkan Anda untuk mengambil, menyisipkan, memperbarui, menghapus, dan membuat data dalam database.
Ada banyak varian SQL dan semua varian memiliki beberapa kesamaan. Persyaratan standar ANSI memberlakukan kesamaan ini bahwa varian menyertakan perintah yang signifikan, seperti di mana, pilih, dan hapus.
Server database SQL berguna di situs web dan aplikasi dalam menyimpan informasi seperti posting dan profil pengguna. Pekerjaan SQL dan peluang karir termasuk pekerjaan bergaji tinggi dalam intelijen bisnis dan ilmu data.
Kiat untuk membantu Anda mempelajari bahasa pemrograman baru
Mempelajari bahasa baru atau melanjutkan ke pemrograman tingkat lanjut bisa menyenangkan. Dengan strategi yang tepat, Anda dapat unggul dalam mempelajari cara membuat kode. Ikuti langkah-langkah ini untuk mempelajari bahasa pemrograman baru:
Tentukan tujuan dan keterampilan Anda
Memilih bahasa terbaik untuk dipelajari melibatkan pemahaman tujuan dan keterampilan Anda. Penting untuk mengetahui apa yang ingin Anda ciptakan dan bagaimana Anda ingin mempelajari bahasa tersebut, terutama karena setiap bahasa mendominasi area tertentu dalam pengembangan perangkat lunak. Misalnya, jika Anda ingin mengembangkan untuk web, Anda bisa mulai dengan JavaScript.
Mempelajari banyak bahasa diperlukan untuk menjadi pengembang perangkat lunak yang sukses. Memahami tujuan dan keterampilan Anda dapat membantu Anda memilih bahasa terbaik untuk dipelajari. Pertimbangan lain adalah untuk mengetahui bagaimana Anda belajar. Jika Anda belajar dengan menyiapkan segalanya di awal untuk mengembangkan dasar yang kuat dalam pengkodean, C adalah bahasa yang sangat baik untuk memulai. Python atau Ruby mungkin merupakan bahasa sederhana terbaik untuk dipelajari jika Anda suka belajar sambil melakukan.
Memahami pemikiran komputasi
Pemikiran komputasional adalah keterampilan penting dalam pemrograman yang membantu Anda mendekati masalah secara sistematis dan menciptakan solusi sedemikian rupa sehingga komputer dapat memproses dan memenuhi tugas.
Keterampilan ini membantu Anda memahami dan menerapkan logika komputer. Anda dapat memulai proses belajar Anda dengan menggunakan abstraksi, pengenalan pola, dan algoritma. Ini dapat membantu Anda lebih intuitif saat mempelajari bahasa baru setelah memahami jargon dan logika komputer.
Gunakan sumber daya online
Setelah memutuskan bahasa mana yang akan dipelajari, Anda dapat mencari sumber online yang dapat mengajari Anda dengan baik. Jika Anda seorang programmer yang lebih suka belajar secara otodidak, Anda dapat mencari kelas online, aplikasi web, dan sumber daya yang membuat pembelajaran bahasa lebih mudah diakses. Jika Anda lebih suka suasana formal, Anda dapat memilih gelar universitas atau sertifikasi.
![]()
![]()
![]()
![]()
![]()
10 Bahasa Pemrograman Teratas Dunia
10 Bahasa Pemrograman Teratas Dunia – Jika Anda seorang pemula di bidang pengembangan perangkat lunak, pertanyaan pertama yang muncul di benak Anda adalah “Dari mana harus memulai?” Itu tidak diragukan lagi benar!
10 Bahasa Pemrograman Teratas Dunia

zorba-xquery – Ada ratusan untuk dipilih, tetapi bagaimana Anda akan menemukan bahwa ya, itu dia? Mana yang paling cocok untuk Anda, minat dan tujuan karir Anda? Salah satu cara termudah untuk memilih bahasa pemrograman terbaik untuk dipelajari adalah dengan mendengarkan apa yang dikatakan pasar, ke mana arah tren teknologi…
Baca Juga : 5 Fakta Coding Keren yang Mungkin Belum Kamu Ketahui
Pindah ke bawah, Anda akan menemukan beberapa bahasa pemrograman terbaik dan paling menuntut untuk pengembangan web, pengembangan seluler, pengembangan game, dan banyak lagi. Pada akhirnya, Anda akan memiliki gagasan yang jelas tentang bahasa pemrograman yang dapat membantu Anda memajukan karir Anda di tahun-tahun mendatang dan seterusnya.
1. JavaScript
Tampaknya mustahil untuk menjadi pengembang perangkat lunak hari ini tanpa menggunakan JavaScript. Yang pertama dalam daftar adalah JavaScript, tampaknya mustahil untuk membayangkan pengembangan perangkat lunak tanpa JavaScript.
Melihat Survei Pengembang 2018 dari Stack Overflow , JavaScript adalah bahasa paling populer di kalangan pengembang berturut-turut selama 6 tahun. Dan sekitar 65% dari mereka telah menggunakan bahasa ini dalam satu tahun terakhir.
Terutama, JavaScript ringan, ditafsirkan dan memainkan peran utama dalam pengembangan front-end. Bahkan beberapa platform media sosial utama percaya bahwa JavaScript menyediakan cara mudah untuk membuat halaman web interaktif dengan lancar dan didorong oleh karir.
JavaScript paling disukai karena kompatibilitasnya dengan semua browser utama dan sangat fleksibel dengan sintaks yang dimilikinya. Menjadi bahasa Front-end, JavaScript juga digunakan di sisi server melalui Node.js. Yang terpenting, jadikan JavaScript sebagai bahasa pemrograman terindah di antara para pemula.
2. Python
Ini mungkin mengejutkan Anda; Saya telah menyimpan python di nomor # 2, di banyak survei itu diposisikan di nomor # 5. Tapi, saya pasti akan membiarkan Anda percaya, inilah alasannya? Python adalah salah satu tujuan umum, bahasa pemrograman yang ramah pengguna di sini di daftar saya. Apa yang membuatnya begitu? Seperti Java, sintaks Python jelas, intuitif dan hampir mirip dengan bahasa Inggris. Subset “berbasis objek” Python mirip dengan JavaScript.
Menurut Stack Overflow, ada satu bagian yang mengatakan “Untuk diadopsi atau dimigrasi menjadi—atau untuk bermigrasi terlalu cepat” , dan untuk python, itu adalah 12% yang tertinggi. Secara umum, orang yang bermigrasi ke python hampir 42%, yang berarti berada di nomor #2. Jika Anda tertarik untuk berkarir dalam pengembangan back-end, seperti Django – Kerangka kerja sumber terbuka, ditulis dengan python, yang membuatnya mudah dipelajari dan penuh fitur, namun populer. Selain itu, python memiliki berbagai aplikasi yang menjadikannya serbaguna dan kuat.
Menjadi sangat populer di bidang-bidang seperti komputasi ilmiah, dan pembelajaran mesin dan teknik, Python mendukung gaya pemrograman yang menggunakan fungsi dan variabel sederhana tanpa banyak menginterogasi dalam definisi kelas.
3. Java
Jika ada yang bertanya mengapa java, kalimat yang paling sering muncul adalah “tulis sekali, jalankan di mana-mana” – Java telah menjadi bahasa pemrograman yang berkuasa selama 20 tahun terakhir. Java 99% berorientasi objek dan kuat karena objek Java tidak mengandung referensi ke data eksternal untuk dirinya sendiri. Ini lebih sederhana daripada C++ karena Java menggunakan alokasi memori otomatis dan pengumpulan sampah.
Java sangat kompatibel lintas platform atau platform independen. Karena Anda dapat membuat kode di mana saja (maksud saya di semua perangkat), kompilasi menjadi kode mesin tingkat rendah, dan akhirnya, jalankan di platform apa pun menggunakan JVM – Java Virtual Machine (yang bergantung pada platform).
Java membentuk basis untuk sistem operasi Android dan memilih sekitar 90% perusahaan peruntungan 500 untuk membuat berbagai aplikasi back-end. Saya tidak akan ragu untuk mengambil sensasi terbesar pengolahan data Apache Hadoop, dijalankan oleh Amazon Web Services dan Windows Azure. Dengan begitu banyak alasan bagus dan berbagai aplikasi bisnis, memiliki fleksibilitas luar biasa dan java adalah favorit pemula sepanjang masa.
4. C / CPP
“Lama adalah emas” – C telah membuktikan kutipan ini dengan cara yang berbeda. Diperkenalkan pada akhir 1970-an, C telah memberikan kontribusi yang kuat bagi dunia pemrograman. C telah menjadi bahasa induk dari segelintir orang; beberapa berasal dari C atau terinspirasi oleh sintaks, konstruksi, dan paradigmanya, termasuk Java, Objective-C, dan C#.
Bahkan, saat ini terlihat, setiap kali ada kebutuhan untuk membangun aplikasi berperforma tinggi, C tetap menjadi pilihan paling populer. OS Linux berbasis C. Dan CPP adalah versi hibrida dari C. C++ adalah bahasa pemrograman berorientasi objek dan dibangun di atas C; oleh karena itu lebih disukai daripada yang lain untuk merancang aplikasi tingkat yang lebih tinggi.
C++ terlihat lebih berkinerja daripada bahasa yang diketik secara dinamis karena kodenya diperiksa tipenya sebelum dieksekusi dengan alasan nyata. Area inti pengembangan adalah Virtual Reality, game, grafik komputer, dll.
5. PHP
Fakta ini benar-benar akan membuat Anda takjub, bahasa yang dibuat untuk tujuan memelihara Personal Home Page (PHP) untuk Rasmus, sebenarnya telah mengambil alih sekitar 83% situs web secara global saat ini.
PHP adalah singkatan dari Hypertext Preprocessor, adalah bahasa pemrograman tujuan umum. Jelas, PHP adalah bahasa scripting, yang berjalan di server, dan digunakan untuk membuat halaman web yang ditulis dalam HTML. Ini populer karena gratis, murah, mudah diatur dan mudah digunakan untuk programmer baru.
PHP adalah pilihan yang sangat kuat untuk pengembang web di seluruh dunia. Ini banyak digunakan untuk membuat konten halaman web dinamis, dan gambar yang digunakan di situs web. Ini mencapai nomor # 5 karena jangkauan penggunaannya yang luas. Selain itu, PHP juga cocok untuk WordPress CMS (Content Management System). Salah satu alasannya, telah tertinggal ke nomor # 5, PHP menurunkan kinerja situs web dan memengaruhi waktu pemuatan.
6. Swift
Berikutnya dalam daftar adalah Swift. Sehalus namanya, Swift adalah tujuan umum, open-source, bahasa pemrograman yang dikompilasi yang dikembangkan oleh Apple Inc. Jika Anda ingin mengembangkan aplikasi iOS atau Mac OS asli, Swift hampir tidak diperlukan untuk pengembangannya.
Swift sangat dipengaruhi oleh Python dan Ruby dan dirancang agar ramah-pemula dan menyenangkan untuk digunakan. Swift dianggap lebih cepat, lebih aman, dan lebih mudah dibaca dan di-debug daripada Objective-C pendahulunya.
Tidak seperti Objective-C, Swift membutuhkan lebih sedikit kode, mirip dengan bahasa Inggris alami. Oleh karena itu, menjadi lebih mudah bagi teknisi yang ada dari JavaScript, Java, Python, C#, dan C++ untuk beralih ke Swift tanpa kerumitan.
Selain itu, beberapa tantangannya adalah talent pool yang terbatas. Anda mungkin tidak menemukan banyak pengembang Swift di sekitar Anda dibandingkan dengan bahasa sumber terbuka lainnya. Survei terbaru mengatakan, hanya 8,1% dari 78.000 responden menggunakan Swift, yang lebih rendah dibandingkan dengan yang lain. Dan karena seringnya update, Swift dianggap kurang stabil dengan setiap rilis baru.
7. C# (C-sharp)
C-sharp adalah bahasa pemrograman berorientasi objek yang kuat yang dikembangkan oleh Microsoft pada tahun 2000. C-sharp digunakan dalam mengembangkan aplikasi desktop dan baru-baru ini, aplikasi Windows 8/10 dan membutuhkan kerangka kerja .NET agar berfungsi.
Microsoft mengembangkan C# sebagai saingan Java. Sebenarnya, Sun tidak ingin campur tangan Microsoft membuat perubahan di Java. Jadi, itu diciptakan. C# memiliki berbagai fitur yang membuatnya lebih mudah dipelajari untuk pemula. Kode ini konsisten, dan logis dibandingkan dengan C++. Menemukan kesalahan dalam C# sangatlah mudah karena ini adalah bahasa yang diketik secara statis, di mana kode diperiksa sebelum mengubahnya menjadi aplikasi.
Singkatnya, sangat cocok untuk mengembangkan aplikasi web, aplikasi desktop dan juga membuktikan dirinya dalam game VR, 2D, dan 3D. Alat lintas platform seperti Xamarin telah ditulis dalam C # membuat semua perangkat kompatibel.
8. Ruby
Sebuah open source, bahasa pemrograman dinamis, berfokus pada kesederhanaan dan produktivitas, dikembangkan pada pertengahan 1990 di Jepang. Ini dikembangkan dengan tujuan membuat lingkungan pemrograman lebih mudah dan lebih menyenangkan.
Ruby telah mendapatkan popularitas dengan kerangka kerja Ruby on Rails, kerangka kerja web full-stack. Ruby adalah bahasa yang diketik secara dinamis, tanpa aturan tetap dan bahasa tingkat tinggi yang sangat mirip dengan bahasa Inggris.
Singkatnya, Anda dapat membangun aplikasi dengan lebih sedikit baris kode. Tetapi tantangan Ruby adalah bahasa yang diketik secara dinamis, pemeliharaannya tidak mudah dan fleksibilitasnya membuatnya lambat.
9. Objective-C
Objective-C (ObjC) adalah bahasa pemrograman berorientasi objek. Ini digunakan oleh Apple untuk sistem operasi OS X dan iOS dan antarmuka pemrograman aplikasi (API). Ini dikembangkan pada 1980-an dan mulai digunakan oleh beberapa sistem operasi paling awal. Objective-C berorientasi objek, tujuan umum. Anda dapat menyebutnya hybrid C karena fitur yang ditambahkan ke bahasa pemrograman C.
10. SQL
SQL (es-que-el) adalah singkatan dari Structured Query Language, adalah bahasa pemrograman untuk mengoperasikan database. Ini termasuk menyimpan, memanipulasi dan mengambil data yang disimpan dalam database relasional.
SQL menjaga data tetap akurat dan aman, dan juga membantu menjaga integritas database, terlepas dari ukurannya. SQL digunakan saat ini di seluruh kerangka kerja web dan aplikasi basis data. Jika Anda fasih dalam SQL, Anda dapat memiliki perintah yang lebih baik atas eksplorasi data, dan pengambilan keputusan yang efektif .
Jika Anda berencana untuk memilih manajemen database sebagai karir Anda, pertama-tama melalui C atau C++. Pengembang SQL sangat diminati dan ditawarkan skala gaji tinggi oleh organisasi terkenal.
![]()
![]()
![]()
![]()
![]()

5 Fakta Coding Keren yang Mungkin Belum Kamu Ketahui
5 Fakta Coding Keren yang Mungkin Belum Kamu Ketahui – Saat pertama kali mulai mempelajari bahasa pemrograman baru , kemungkinan besar Anda akan mulai dengan membaca tentang sintaks dan berbagai konsep yang digunakan dalam bahasa tersebut.
5 Fakta Coding Keren yang Mungkin Belum Kamu Ketahui

zorba-xquery – Apa yang mungkin tidak Anda lakukan adalah mempelajari fakta pengkodean yang keren dan sejarah yang menarik — dan masa depan — pengkodean. Tapi ada lebih banyak untuk pengkodean daripada yang terlihat.
Baca Juga : Sejarah Bahasa Pemrograman Komputer
Untuk memberi Anda gambaran tentang dunia yang menarik ini, berikut adalah beberapa fakta menarik tentang pengkodean.
1. Ada lebih dari 700 bahasa pengkodean
Anda kemungkinan besar pernah mendengar tentang Python , JavaScript , C++ , HTML, dan CSS , tetapi pernahkah Anda mendengar tentang Chef, bahasa pemrograman yang kodenya terlihat seperti resep, lengkap dengan daftar bahan dan instruksinya?
Bagaimana dengan CLWNPA (Bahasa Kompilator tanpa Akronim yang Dapat Diucapkan), di mana Anda perlu menambahkan “Tolong” ke kode Anda atau kompilator menganggap Anda tidak sopan? Dan bagaimana dengan Velato, bahasa untuk pemrogram musik dengan kode sumber yang sebenarnya adalah file MIDI?
Ini hanyalah beberapa contoh dari lebih dari 700 bahasa pemrograman di luar sana saat ini — itu dua kali jumlah bahasa yang digunakan di AS saja .
2. “Bug komputer” pertama adalah bug yang sebenarnya
Pada tahun 1947, sebuah tim ilmuwan dan insinyur komputer di Harvard menyadari bahwa komputer mereka tidak berfungsi dengan baik. Mereka memutuskan untuk melihat perangkat keras komputer dan menemukan ngengat terperangkap di dalamnya.
Saat itulah Grace Hopper , ilmuwan komputer dan penemu kompilator pemrosesan data berbahasa Inggris pertama, mencatat “kasus bug pertama yang ditemukan” di buku catatan komputer. Tentu saja, hari ini kita menyebut “bug” sebagai kesalahan atau kekurangan dalam kode atau sistem komputer — dan men- debug kode adalah bagian besar dari menjadi pemrogram komputer. Tapi bug pertama yang direkam melibatkan ngengat sial yang terjebak di komputer.
3. Virus komputer pertama tidak berbahaya
Penjelasan paling sederhana dari virus komputer adalah kode yang dapat menyalin dirinya sendiri dan pindah ke komputer lain, sebuah konsep yang berasal dari tahun 1940-an. Tetapi baru pada tahun 1971 Creeper, virus komputer pertama, dikembangkan. Virus Creeper dirancang sebagai tes keamanan, dan yang dilakukannya hanyalah menampilkan pesan: “I’M THE CREEPER. TANGKAP AKU JIKA KAMU BISA.”
Lima belas tahun kemudian, dua bersaudara Pakistan mengembangkan virus siluman pertama, Brain, yang disembunyikan di floppy disk perangkat lunak. Saudara-saudara menciptakan virus karena mereka bosan dengan orang-orang yang membuat salinan ilegal dari perangkat lunak medis mereka. Saat ini, ketika kita memikirkan virus komputer, kita memikirkan efek negatifnya, seperti menghapus data atau merusak seluruh jaringan komputer. Tetapi semua virus pertama memiliki satu kesamaan: Mereka tidak dirancang untuk mencuri atau merusak data.
4. Coding bukan hanya untuk industri teknologi
Silicon Valley, Austin, Seattle, San Francisco, dan pusat teknologi lainnya penuh dengan programmer, tetapi Anda dapat menemukan pekerjaan pengkodean di setiap negara bagian di AS (dan terpencil ) dan di setiap industri. Faktanya, sekitar 70% pekerjaan pengkodean yang diiklankan berada di luar industri teknologi. Jadi, meskipun pekerjaan coding di industri teknologi adalah pilihan karir yang sangat baik, Anda dapat memperluas prospek Anda hanya dengan mencari pekerjaan di luar industri teknologi.
Ini adalah berita bagus bagi siapa saja yang ingin beralih karir ke coding dan pengembangan, karena itu berarti Anda memiliki pilihan untuk tetap berada di industri Anda saat ini bahkan jika Anda ingin menjadi programmer komputer. Misalnya, jika Anda seorang pemasar di industri perawatan kesehatan tetapi peran pemasaran Anda tidak sesuai lagi, perusahaan perawatan kesehatan membutuhkan orang yang tahu cara membuat kode — dari Ilmuwan Data hingga Pakar Keamanan Siber dan semua orang di antaranya. Jadi Anda dapat melamar ke perusahaan yang membuat produk perawatan kesehatan yang Anda kenal, dan membawa pengetahuan dan keahlian Anda ke tim pengembangan.
Dengan kata lain, coding memberi Anda banyak fleksibilitas dalam memutuskan bagaimana mengelola karir Anda. Jika Anda ingin bekerja untuk perusahaan rintisan Lembah Silikon yang bergerak cepat, Anda dapat melakukannya dengan keterampilan pengkodean Anda . Jika panggilan sejati Anda adalah dalam pekerjaan nirlaba lingkungan , keterampilan pengkodean Anda dapat membantu Anda mencapai impian itu juga.
5. Perusahaan tidak dapat mempekerjakan cukup pembuat kode
Meskipun setiap industri besar membutuhkan orang yang tahu cara membuat kode, inilah ironi: Pemrogram terampil tidak cukup untuk berkeliling. Selama beberapa tahun terakhir, permintaan akan keterampilan pengkodean telah jauh melebihi pasokan orang yang tahu cara membuat kode. Dan ini bukan hanya sebuah fase.
Biro Statistik Tenaga Kerja (BLS) memperkirakan bahwa pekerjaan komputer dan teknologi informasi (TI) akan tumbuh sebesar 13% antara tahun 2020 dan 2030. Itu hampir dua kali lipat perkiraan tingkat pertumbuhan di semua pekerjaan lain.
Lebih khusus lagi, peran untuk Pengembang Perangkat Lunak dan Analis Jaminan Kualitas diproyeksikan tumbuh sebesar 22% , pekerjaan dalam pengembangan web dan desain digital diproyeksikan akan meningkat 13% , dan Administrator Basis Data dan Arsitek dapat mengalami lonjakan 8% .
Ini adalah berita bagus jika Anda mempertimbangkan untuk berkarir di bidang pemrograman atau sedang dalam perjalanan untuk menjadi pengembang, karena perusahaan di seluruh dunia akan mencari untuk mempekerjakan orang dengan keahlian Anda. Ini juga berarti Anda akan memiliki kesempatan untuk menjelajahi posisi di berbagai bagian negara, dan di berbagai industri.
Siap untuk memulai pengkodean?
Jika Anda merasa termotivasi untuk mempelajari cara membuat kode, pastikan untuk memeriksa kursus online kami , di mana Anda dapat memilih dari banyak bahasa pemrograman teratas, termasuk Python , C++ , dan Java .
Anda juga dapat mendalami pengembangan web , ilmu data , pengembangan game , atau pengembangan seluler dan mempelajari bahasa pemrograman selama prosesnya, serta semua yang perlu Anda ketahui untuk memulai di salah satu jalur karier ini.
![]()
![]()
![]()
![]()
![]()