Penyusunan Html Menggunakan Xquery – Format html yang disusun dengan sangat baik menjadi salah satu kunci utama kesuksesan sebuah situs html. Tentu saja dengan adanya situs html yang terstruktur dengan rapi memungkinkan para penggunanya dapat menyesuaikan dengan lebih mudah.
Fleksibilitas dari prosesor xquery yang digunakan memungkinkan para pembangun website memiliki kesempatan yang lebih luas untuk membangun sebuah situs website yang lebih mudah dipahami oleh penggunanya. Xquery memberikan fasilitas kepada pembangun situs untuk membuat situs yang lebih informatif. Penggunaan bahasa program yang lebih terstruktur memungkinkan para penggunanya bisa lebih mudah dalam melakukan penyusunan html dari sumber data yang lebih akurat. Bahasa program yang lebih sederhana dan tidak terlalu menyulitkan memudahkan penggunanya untuk menyusun website dengan format yang lebih mudah.
Prosesor xquery memiliki bahasa perintah program yang sama sekali tidak rumit. Kesederhanaan dari bahasa perintah diwujudkan dalam bentuk infrastruktur program yang lebih rapi. Infrastruktur program dan perintah program yang digunakan berbentuk seperti infrastruktur berupa pohon yang lebih rapi. Penggunaan bentuk infrastruktur seperti pohon memungkinkan prosesor ini untuk bekerja dengan lebih maksimal. Infrastruktur seperti pohon merupakan infrastruktur program yang sangat sederhana. Di dalam infrastruktur tersebut terdapat banyak sekali simpul yang mudah dioperasikan. Seperti atribut, dokumen, teks, kolom komentar, kolom untuk nama dan beberapa atribut pendukung lainnya yang mendukung terciptanya sebuah website yang informatif.
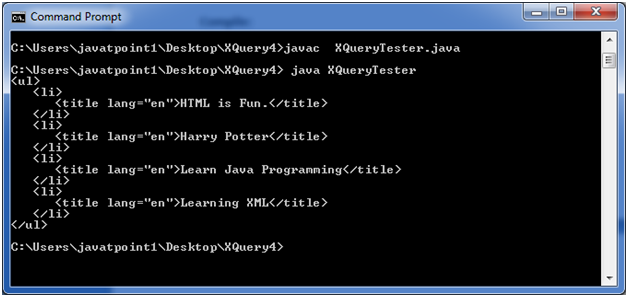
Prosesor xquery bisa dikatakan sebagai salah satu prosesor yang cukup tua. Mengingat bahwa prosesor ini sudah mulai digunakan sejak awal tahun 90 an. Meskipun merupakan prosesor yang sudah cukup tua, namun untuk membangun html hingga kini masih bisa dimanfaatkan sebagai salah satu media untuk membangun situs yang akurat dan juga informatif. Akurasi dan juga semua informasi yang bersumber dari sumber data yang jelas bisa dimasukkan secara sempurna. Bahasa pemrogramannya yang sangat sederhana meskipun sudah cukup tua akan tetapi masih sesuai digunakan sampai saat ini untuk membangun sebuah website yang informatif dengan gaya yang lebih sederhana. Sebagai contohnya, Anda bisa melihat langsung ke website yang menggunakan bahasa pemrograman Prosesor xquery.
Meskipun bahasa program dan atribut-atributnya tergolong sederhana, namun pada kenyataannya komponen atribut tersebut masih layak dijadikan salah satu alat untuk membangun sebuah website yang informatif. Strukturnya yang lebih sederhana namun lebih rapi memungkinkan siapa saja yang menggunakannya bisa membuat website dengan lebih mudah dan lebih sederhana. Itulah sebabnya mengapa prosesor xquery masih dianggap sesuai untuk membangun situs html yang sederhana dengan banyak informasi dan konten yang bisa dimasukkan di dalam website. Kesesuaian inilah yang membuat xquery masih dipilih sebagai prosesor yang cukup ampuh untuk membuat situs html dengan konten yang cukup padat. Proses penyusunannya yang lebih mudah dan relatif lebih cepat memastikan bahwa xquery menjadi komponen bahasa program html yang cocok untuk digunakan sebagai pembuat html yang sesuai sepanjang masa.

Sejarah Bahasa Pemrograman Komputer
Sejarah Bahasa Pemrograman Komputer – Pemrograman komputer sangat penting di dunia kita saat ini, menjalankan sistem untuk hampir setiap perangkat yang kita gunakan. Bahasa pemrograman komputer memungkinkan kita memberi tahu mesin apa yang harus dilakukan. Mesin dan manusia “berpikir” sangat berbeda, jadi bahasa pemrograman diperlukan untuk menjembatani kesenjangan itu.
Sejarah Bahasa Pemrograman Komputer

zorba-xquery – Bahasa pemrograman komputer pertama dikembangkan pada tahun 1883 ketika seorang wanita bernama Ada Lovelace bekerja dengan Charles Babbage pada mesin analisis, komputer mekanis awal. Sementara Babbage hanya peduli dengan menghitung angka, Lovelace melihat bahwa angka-angka yang digunakan komputer dapat mewakili sesuatu selain dari jumlah hal.
Baca Juga : 10 Ekstensi Chrome Terbaik Untuk Menemukan XPath
Dia menulis algoritma untuk Analytical Engine yang merupakan yang pertama dari jenisnya. Karena kontribusinya, Lovelace dikreditkan dengan menciptakan bahasa pemrograman komputer pertama. Karena kebutuhan yang berbeda telah muncul dan perangkat baru telah dibuat, lebih banyak bahasa telah mengikuti.
1883 : Algoritma untuk Analytical Engine : Dibuat oleh Ada Lovelace untuk Analytical Engine Charles Babbage untuk menghitung bilangan Bernoulli , ini dianggap sebagai bahasa pemrograman komputer pertama.
1949 : Bahasa Perakitan : Pertama kali digunakan secara luas dalam Kalkulator Otomatis Penyimpanan Penundaan Elektronik , bahasa rakitan adalah jenis bahasa pemrograman komputer tingkat rendah yang menyederhanakan bahasa kode mesin, instruksi khusus yang diperlukan untuk memberi tahu komputer apa yang harus dilakukan.
1952 : Autocode: Autocode adalah istilah umum untuk keluarga bahasa pemrograman komputer awal. Yang pertama dikembangkan oleh Alick Glennie untuk komputer Mark 1 di University of Manchester di Inggris. Beberapa menganggap autocode sebagai bahasa pemrograman komputer pertama yang dikompilasi, artinya dapat diterjemahkan langsung ke dalam kode mesin menggunakan program yang disebut compiler.
1957 : Fortran : Sebuah bahasa pemrograman komputer yang dibuat oleh John Backus untuk pekerjaan ilmiah, matematika, dan statistik yang rumit, Fortran adalah singkatan dari For mula Tran slation. Ini adalah salah satu bahasa pemrograman komputer tertua yang masih digunakan sampai sekarang.
1958 : Algol : Dibuat oleh sebuah komite untuk penggunaan ilmiah, Algol adalah singkatan dari Algo rithmic L anguage . Algol berfungsi sebagai titik awal dalam pengembangan bahasa seperti Pascal, C, C++, dan Java.
1959 : COBOL : Dibuat oleh Dr. Grace Murray Hopper sebagai bahasa pemrograman komputer yang dapat berjalan di semua merek dan tipe komputer, COBOL adalah singkatan dari CO mmon B usiness O oriented L anguage . Ini digunakan di ATM, pemrosesan kartu kredit, sistem telepon, komputer rumah sakit dan pemerintah, sistem otomotif, dan sinyal lalu lintas. Dalam film The Terminator , potongan kode sumber COBOL digunakan dalam tampilan visi Terminator.
1959 : LISP : Dibuat oleh John McCarthy dari MIT, LISP masih digunakan. Itu singkatan dari bahasa pemrosesan LIS t P. Ini awalnya dibuat untuk penelitian kecerdasan buatan tetapi hari ini dapat digunakan dalam situasi di mana Ruby atau Python digunakan.
1964 : DASAR : Dikembangkan oleh John G. Kemeny dan Thomas E. Kurtz di Dartmouth College sehingga mahasiswa yang tidak memiliki pemahaman teknis atau matematis yang kuat tetap dapat menggunakan komputer, itu singkatan dari B eginner’s A ll-purpose S ymbolic I ntruction C syair pujian. Sebuah versi modifikasi dari BASIC ditulis oleh Bill Gates dan Paul Allen. Ini menjadi produk Microsoft pertama.
1970 : Pascal : Dikembangkan oleh Niklaus Wirth, Pascal dinamai untuk menghormati matematikawan, fisikawan, dan filsuf Prancis Blaise Pascal. Mudah dipelajari dan awalnya dibuat sebagai alat untuk mengajar pemrograman komputer. Pascal adalah bahasa utama yang digunakan untuk pengembangan perangkat lunak di tahun-tahun awal Apple.
1972 : Smalltalk : Dikembangkan oleh Alan Kay, Adele Goldberg, dan Dan Ingalls di Xerox Palo Alto Research Center, Smalltalk memungkinkan pemrogram komputer untuk memodifikasi kode dengan cepat dan juga memperkenalkan aspek lain yang sekarang ada dalam bahasa pemrograman komputer umum termasuk Python, Java, dan Rubi.
1972 : C : Dikembangkan oleh Dennis Ritchie di Bell Labs, C dianggap oleh banyak orang sebagai bahasa tingkat tinggi pertama. Bahasa pemrograman komputer tingkat tinggi lebih dekat dengan bahasa manusia dan lebih jauh dari kode mesin. C dibuat agar sistem operasi yang disebut Unix dapat digunakan di berbagai jenis komputer. Ini telah mempengaruhi banyak bahasa lain, termasuk Ruby, C#, Go, Java, JavaScript, Perl, PHP, dan Python.
1972 : SQL : SQL dikembangkan oleh Donald D. Chamberlin dan Raymond F. Boyce di IBM. SQL adalah singkatan dari S tructured Q uery L anguage . Hal ini digunakan untuk melihat dan mengubah informasi yang disimpan dalam database. SQL menggunakan kalimat perintah yang disebut query untuk menambah, menghapus, atau melihat data.
1978 : MATLAB : Dikembangkan oleh Cleve Moler. MATLAB adalah singkatan dari Mat rix Lab oratory. Ini adalah salah satu bahasa pemrograman komputer terbaik untuk menulis program matematika dan terutama digunakan dalam matematika, penelitian, dan pendidikan. Ini juga dapat digunakan untuk membuat grafik dua dan tiga dimensi.
1983 : Objective-C : Dibuat oleh Brad Cox dan Tom Love, Objective-C adalah bahasa pemrograman komputer utama yang digunakan saat menulis perangkat lunak untuk macOS dan iOS, sistem operasi Apple.
1983 : C++ : C++ merupakan perpanjangan dari bahasa C dan dikembangkan oleh Bjarne Stroustrup. Ini adalah salah satu bahasa yang paling banyak digunakan di dunia. C++ digunakan dalam mesin game dan perangkat lunak berkinerja tinggi seperti Adobe Photoshop. Sebagian besar perangkat lunak yang dikemas masih ditulis dalam C++.
1987 : Perl : Perl awalnya dikembangkan oleh Larry Wall pada tahun 1987 sebagai bahasa scripting yang dirancang untuk penyuntingan teks. Tujuannya adalah untuk mempermudah pemrosesan laporan. Sekarang banyak digunakan untuk berbagai tujuan, termasuk administrasi sistem Linux, pengembangan Web, dan pemrograman jaringan.
1990 : Haskell : Dinamakan setelah Haskell Brooks Curry, seorang ahli logika dan matematika Amerika. Haskell disebut bahasa pemrograman komputer yang berfungsi murni, yang pada dasarnya berarti sebagian besar bersifat matematis. Ini digunakan oleh banyak industri, terutama yang berhubungan dengan perhitungan, pencatatan, dan penghitungan angka yang rumit.
1991 : Python : Dirancang oleh Guido Van Rossum, Python lebih mudah dibaca dan membutuhkan lebih sedikit baris kode daripada banyak bahasa pemrograman komputer lainnya. Itu dinamai grup komedi Inggris Monty Python. Situs populer seperti Instagram menggunakan kerangka kerja yang ditulis dengan Python.
1991 : Visual Basic : Dikembangkan oleh Microsoft, Visual Basic memungkinkan pemrogram untuk memilih dan mengubah potongan kode yang telah dipilih sebelumnya dengan cara drag-and-drop melalui antarmuka pengguna grafis (GUI).
1993 : R : Dikembangkan oleh Ross Ihaka dan Robert Gentleman di University of Auckland, Selandia Baru, R dinamai menurut nama depan dua penulis pertama. Ini sebagian besar digunakan oleh ahli statistik dan mereka yang melakukan berbagai jenis analisis data.
1995 : Java: Awalnya disebut Oak, Java dikembangkan oleh Sun Microsystems. Itu dimaksudkan untuk kotak kabel dan perangkat genggam tetapi kemudian ditingkatkan sehingga dapat digunakan untuk menyampaikan informasi di World Wide Web. Java ada di mana-mana, mulai dari komputer hingga smartphone hingga meteran parkir. Tiga miliar perangkat menjalankan Java!
1995 : PHP : Dibuat oleh Rasmus Lerdorf, PHP sebagian besar digunakan untuk pengembangan Web dan biasanya dijalankan di server Web. Awalnya adalah singkatan dari Personal Home Page , karena digunakan oleh Lerdorf untuk mengelola informasi online- nya sendiri . PHP sekarang banyak digunakan untuk membangun website dan blog. WordPress, alat pembuatan situs web populer, ditulis menggunakan PHP.
1995 : Ruby : Ruby diciptakan oleh Yukihiro “Matz” Matsumoto, yang menggabungkan bagian dari bahasa favoritnya untuk membentuk bahasa pemrograman komputer serba guna baru yang dapat melakukan banyak tugas pemrograman. Ini populer dalam pengembangan aplikasi Web. Kode Ruby dieksekusi lebih lambat, tetapi memungkinkan pemrogram komputer dengan cepat menyusun dan menjalankan program.
1995 : JavaScript: Dibuat hanya dalam 10 hari oleh Brendan Eich, bahasa ini banyak digunakan untuk meningkatkan banyak interaksi browser Web. Hampir setiap situs web besar menggunakan Javascript.
2000 : C# : Dikembangkan oleh Microsoft dengan tujuan menggabungkan kemampuan komputasi C++ dengan kesederhanaan Visual Basic, C# didasarkan pada C++ dan mirip dengan Java dalam banyak aspek. Ini digunakan di hampir semua produk Microsoft dan terutama digunakan untuk mengembangkan aplikasi desktop.
2003 : Scala: Dibuat oleh Martin Odersky. Scala adalah bahasa pemrograman komputer yang menggabungkan pemrograman fungsional, yang matematis, dengan pemrograman berorientasi objek, yang diatur di sekitar data yang mengontrol akses ke kode. Kompatibilitasnya dengan Java membuatnya membantu dalam pengembangan Android.
2003 : Groovy : Dikembangkan oleh James Strachan dan Bob McWhirter, Groovy berasal dari Java dan meningkatkan produktivitas pengembang karena mudah dipelajari dan ringkas.
2009 : Go : Go dikembangkan oleh Google untuk mengatasi masalah yang dapat terjadi pada sistem perangkat lunak besar. Karena penggunaan komputer dan teknologi saat ini jauh berbeda dibandingkan ketika bahasa seperti C++, Java, dan Python diperkenalkan dan digunakan, masalah muncul ketika sistem komputer besar menjadi umum. Go dimaksudkan untuk meningkatkan lingkungan kerja bagi pemrogram sehingga mereka dapat menulis, membaca, dan memelihara sistem perangkat lunak besar dengan lebih efisien.
2014 : Swift : Dikembangkan oleh Apple sebagai pengganti C, C++, dan Objective-C, Swift seharusnya lebih mudah digunakan dan memungkinkan lebih sedikit ruang untuk kesalahan. Ini serbaguna dan dapat digunakan untuk aplikasi desktop dan seluler serta layanan cloud.
Bahasa Pemrograman Komputer Saat Ini
Sebagian besar bahasa pemrograman komputer terinspirasi oleh atau dibangun di atas konsep dari bahasa pemrograman komputer sebelumnya. Saat ini, sementara bahasa lama masih berfungsi sebagai dasar yang kuat untuk bahasa baru, bahasa pemrograman komputer yang lebih baru membuat pekerjaan pemrogram menjadi lebih sederhana. Bisnis sangat bergantung pada program untuk memenuhi semua kebutuhan data, transaksi, dan layanan pelanggan mereka.
Sains dan kedokteran membutuhkan program yang akurat dan kompleks untuk penelitiannya. Aplikasi seluler harus diperbarui untuk memenuhi permintaan konsumen. Dan semua kebutuhan baru dan berkembang ini memastikan bahwa bahasa pemrograman komputer, baik lama maupun baru, akan tetap menjadi bagian penting dari kehidupan modern.
10 Ekstensi Chrome Terbaik Untuk Menemukan XPath
10 Ekstensi Chrome Terbaik Untuk Menemukan XPath – Di sini saya akan menyajikan 10 ekstensi Google Chrome terbaik untuk menemukan XPath di Selenium yang membantu Anda menemukan XPath dengan mudah.
10 Ekstensi Chrome Terbaik Untuk Menemukan XPath

zorba-xquery – Selenium telah mendapatkan popularitas besar di bidang otomatisasi pengujian. Sebagian besar perusahaan mengadopsi alat ini. Sebagai penguji otomatisasi, saya tahu tantangan yang kami hadapi saat menemukan XPath yang kuat di Selenium.
Baca Juga : Panduan Pemula Untuk XRX
Mari kita lihat Ekstensi XPath Untuk Chrome secara detail:
1. SelectorsHub
XPath dan cssSelector dapat ditulis dalam waktu kurang dari 5 detik. Anda membacanya dengan benar!! SelectorsHub otomatis menyarankan semua atribut, teks, dan semuanya untuk menyelesaikan Selectors dengan cepat.
Sekarang Anda tidak perlu lagi menyalin dan menempelkan nilai atribut dari DOM untuk membangun XPath dan cssSelector. Ini juga mendukung elemen shadowDOM, iframe, dan SVG. Ini memberikan pesan kesalahan yang tepat seperti apa yang salah di xpath dan cssSelector Anda. Ini adalah satu-satunya alat untuk mendukung pemilih shadowDOM.
2. XPath Helper
Anda dapat mengekstrak, mengedit, dan mengevaluasi kueri XPath di halaman web mana pun dengan mudah menggunakan XPath Helper. Ini sangat sederhana dan basis pengguna lebih dibandingkan dengan plugin lain dalam daftar ini. Cukup klik pada ekstensi untuk membuka konsol untuk menulis atau mengedit XPath.
3. ChroPath
Ekstensi ini digunakan untuk menghasilkan dan memvalidasi pemilih unik seperti relatif xpath, xpath absolut, cssSelectors, linkText, dan partialLinkText dengan satu klik. Itu membuat mudah untuk menulis, mengedit, mengekstrak, dan mengevaluasi kueri XPath di halaman web mana pun. Ini juga mendukung iframe.
4. Scraper
Scraper mengeluarkan data dari halaman web dan ke dalam spreadsheet. Ini adalah ekstensi penambangan data yang sangat sederhana (namun terbatas) untuk memfasilitasi penelitian online ketika Anda perlu memasukkan data ke dalam bentuk spreadsheet dengan cepat. Ini dimaksudkan sebagai alat yang mudah digunakan untuk pengguna tingkat menengah hingga mahir yang merasa nyaman dengan XPath.
5. Relative XPath Helper
Relative XPath Helper digunakan untuk mengetahui ekspresi XPath relatif dari dua elemen web. Cukup klik kanan pada elemen pertama dan kedua untuk mendapatkan XPath relatif.
6. Xpath Helper Wizard
XPath Helper Plus membuat xpaths yang pendek dan kecil kemungkinannya untuk rusak jika situs web berubah. Jika bidang Xpath induk berisi Xpath maka semua Xpath berikutnya dihasilkan relatif terhadap Xpath induk tersebut.
7. Xpath Finder
Xpath Finder menemukan elemen menurut Xpath Di Chrome DevTools. Ini menandai elemen yang cocok dengan garis besar dan latar belakang yang disorot dan juga mencatat riwayat xpath Anda.
8. XPather
Ekstensi ini beroperasi pada dokumen saat ini. Ini mendukung XPath 2.0. Ini menyoroti hasil dan menunjukkan semua node cocok yang tersedia di sidebar. Anda dapat menemukan simpul yang cocok di halaman dengan mengekliknya di bilah sisi.
9. Firebug Lite for Google Chrome:
Ingat bahwa Firebug Lite bukan pengganti Firebug atau Alat Pengembang Chrome. Ini memberikan representasi visual yang kaya dalam hal elemen HTML, elemen DOM, dan bayangan Model Kotak. Ini juga menyediakan pemeriksaan elemen HTML dengan mouse Anda.
10. Eskry
Ini membantu untuk menghasilkan pencari lokasi dalam metode titik dan penangkapan untuk elemen HTML. Mengklik elemen web apa pun di halaman web Anda akan menghasilkan Pemilih XPath / CSS.
11. xPath Analyzer
XPath Analyzer memungkinkan evaluasi ekspresi XPath/XSLT terhadap XML dari tab browser saat ini. Ini memungkinkan Anda untuk mengevaluasi ekspresi XPath terhadap XML yang tersedia di URL yang diberikan.
![]()
![]()
![]()
![]()
![]()
Panduan Pemula Untuk XRX
Panduan Pemula Untuk XRX – Berikut ini adalah Panduan Pemula untuk membuat aplikasi XRX baru dengan server aplikasi eXist. Ini ditujukan untuk orang-orang yang baru mengenal eXist dan tertarik untuk membangun aplikasi web pertama mereka.
Panduan Pemula Untuk XRX

zorba-xquery – Panduan ini menunjukkan kode minimal yang diperlukan untuk membuat aplikasi yang melakukan operasi “CRUDS”. Operasi ini adalah: C reate , Read (atau view), Update , D elete dan Stelinga. Membuat aplikasi XRX pertama Anda bisa jadi agak rumit, karena ada beberapa struktur yang perlu “dihubungkan” dengan benar agar komponen CRUDS berfungsi dengan benar.
Baca Juga : Balisage Paper: Pola Desain XQuery
Contoh ini mencoba menggunakan kode sesedikit mungkin namun masih mencakup banyak komponen utama dari aplikasi web XRX yang berfungsi penuh.
Audiens yang dituju
Membuat aplikasi web baru dari awal adalah keterampilan inti yang diperlukan untuk memahami kekuatan arsitektur aplikasi web XRX. Pengalaman kami telah menunjukkan bahwa begitu pengguna mendapatkan pemahaman tentang bagaimana aplikasi XRX dibangun, mereka dapat dengan cepat menjadi produktif dalam membangun aplikasi web baru. Mereka juga memiliki pemahaman yang jauh lebih baik tentang bagian kompleks dari aplikasi XRX dan mengapa bagian ini biasanya diotomatisasi dalam kerangka kerja XRX.
Dokumen ini dirancang untuk pengguna eXist-db baru yang ingin membuat aplikasi XRX pertama mereka. Untuk proses ini, kami berasumsi bahwa Anda memiliki pemahaman dasar tentang XML dan memahami konsep seperti elemen XML dan ekspresi XPath. Pengguna juga harus agak akrab dengan markup HTML yang sangat dasar, termasuk struktur file XHTML dan penggunaan daftar HTML dan tabel HTML. Kami juga akan menjelaskan bagaimana XQuery digunakan untuk membuat daftar item dan melihat item individual. Pengguna harus meninjau struktur dasar ekspresi XQuery FLOWR (for, let, order by, where, dan return) dan sintaks dasar XQuery.
Harap dicatat bahwa ada beberapa alat GUI drag-and-drop yang mudah digunakan yang tersedia yang dapat membuat XForms, dan ada sistem yang juga dapat secara otomatis membuat aplikasi XRX yang berfungsi penuh langsung dari Skema XML. Tetapi menggunakan alat dan kerangka kerja ini menyembunyikan sebagian besar cara kerja aplikasi XRX. Jadi tutorial ini untuk mereka yang ingin memiliki pemahaman yang jelas tentang cara kerja sistem XRX.
Istilah dan Konsep yang Digunakan
XRX adalah nama arsitektur aplikasi web yang kami perkenalkan dalam panduan ini. Istilah XRX berasal dari kombinasi XForms, REST, dan XQuery. XForms digunakan di klien (browser web), REST adalah antarmuka antara klien dan server, dan XQuery adalah bahasa server. Dua keuntungan paling signifikan dari XRX dibandingkan arsitektur lain adalah: (1) tidak mengharuskan pengguna untuk menerjemahkan data ke objek Java atau .Net, dan (2) tidak mengharuskan pengguna untuk “menghancurkan” dokumen ke dalam baris relasional. basis data.
XForm adalah standar W3C yang terdiri dari sekitar 25 tag XML yang digunakan untuk mendefinisikan struktur web. XForms jauh lebih maju daripada formulir HTML tradisional, tetapi dapat tampak menakutkan bagi pengguna pertama kali. Namun, sebagian besar bentuk sederhana hanya memerlukan beberapa jenis kontrol, dan ini dapat dipelajari dengan cepat. XForms mengikat kontrol antarmuka pengguna ke setiap elemen daun dalam instance XML. XForms menyimpan data dalam elemen model dalam tag HTML HEAD dan kemudian mengikat elemen daun dalam model ke kontrol input web.
Permintaan X adalah bahasa query standar W3C untuk memilih dan mengubah struktur XML. Jika Anda tidak memiliki pengalaman pemrograman, XQuery tidak sulit untuk diambil. Jika Anda memiliki pengalaman pemrograman, XQuery sedikit berbeda dari bahasa lain yang mungkin pernah Anda gunakan sebelumnya.
Ini adalah bahasa pemrograman “fungsional” yang membuatnya sangat mudah untuk membuat program sisi server yang kuat — program yang tidak memiliki banyak “efek samping” dari bahasa lain. Ini mirip dengan bahasa SQL dalam beberapa hal, tetapi secara khusus dirancang untuk struktur XML. Dipasangkan dengan database XML seperti eXist, XQuery adalah bahasa yang ideal untuk membuat aplikasi web. ada’
Catatan untuk Pengguna XQuery Baru . Ada beberapa hal yang sangat berbeda di XQuery yang harus Anda ketahui. Secara umum, semua variabel XQuery tidak dapat diubah , artinya variabel tersebut dirancang untuk disetel sekali tetapi tidak pernah diubah. Jadi fungsi seperti let $x := $x + 1 di dalam loop tidak akan bertambah seperti dalam bahasa prosedural. Ada juga batasan tentang apa yang dapat dilakukan di dalam pernyataan FLOWR. Kami akan mengilustrasikannya dalam contoh di Panduan Pemula di masa mendatang.
ISTIRAHAT adalah jantung dari arsitektur World Wide Web. Kami menggunakan pendekatan “RESTful” untuk menyampaikan informasi di aplikasi XRX kami hanya dengan menempatkan parameter di akhir URL. Misalnya, untuk meneruskan kata kunci kueri ke layanan pencarian aplikasi XRX kami, formulir kami menambahkan parameter q=myword ke URL: search.xq?q=myword. Jika Anda pernah menggunakan arsitektur SOAP, REST adalah angin segar. Tidak diperlukan alat pengujian antarmuka SOAP yang rumit. Yang Anda butuhkan untuk menguji layanan web Anda adalah browser web. M
Beberapa istilah dan konsep tambahan sangat membantu dalam memahami pendekatan XRX:
WebDAV adalah protokol untuk mentransfer file, dan kami menggunakan antarmuka WebDAV eXist untuk memindahkan file ke dan dari eXist dan untuk membuat daftar file dalam koleksi eXist. Jika Anda ingin menambahkan folder ke eXist, Anda dapat melakukannya melalui antarmuka WebDAV. Saat Anda menggunakan oXygen atau editor lain, Anda juga akan menggunakan antarmuka WebDAV.
Binding Tampilan Model adalah istilah yang kami gunakan untuk menggambarkan bagaimana elemen antarmuka pengguna (kontrol) dalam formulir dikaitkan dengan elemen tingkat daun dalam model XForms. Ini mirip dengan arsitektur Model-View-Controller (MVC) di sistem lain, tetapi dalam kasus kontrol acara XForms adalah bagian dari tampilan.
Dengan menggunakan pernyataan XPath dalam atribut ref untuk kontrol antarmuka pengguna, browser membuat grafik ketergantungan untuk menjaga model dan tampilan tetap sinkron. Ini membuat pengembangan formulir menjadi lebih mudah karena pengembang formulir tidak perlu memindahkan data secara manual antara model dan tampilan.
Konvensi tentang Konfigurasi adalah praktik umum di antara kerangka kerja aplikasi web modern seperti XRX dalam menggunakan konvensi seperti koleksi standar dan nama file, untuk mengurangi jumlah konfigurasi dan dengan demikian mengurangi kerumitan dan waktu yang diperlukan untuk membuat prototipe dan menyelesaikan aplikasi.
Tentu saja, pengguna memiliki kemampuan untuk mengubah konvensi ini, tetapi mereka kemudian bertanggung jawab untuk mempertahankan adaptasi mereka sendiri atau kerangka kerja yang terpisah.
Konvensi Pengumpulan dan File
Konvensi pertama aplikasi XRX melibatkan pengumpulan data dan file yang akan menyusun aplikasi kita. Meskipun Anda tidak harus menggunakan konvensi koleksi yang digunakan dalam contoh ini, Anda akan menemukan bahwa kerangka kerja yang menggunakan konvensi ini akan jauh lebih mudah untuk dibangun dan dipelihara.
Berikut adalah standar yang sangat kami sarankan untuk Anda gunakan untuk aplikasi pertama Anda:
Aplikasi Semua aplikasi XRX harus dikelompokkan dalam satu koleksi. Misalnya /db/apps atau /db/org/mycompany/apps . Lokasi yang tepat dari kumpulan aplikasi di database tidak relevan, tetapi semua aplikasi harus disimpan bersama dalam kumpulan yang disebut aplikasi.
Aplikasi Setiap aplikasi XRX harus dikelompokkan dalam koleksi. Nama koleksi ini harus mencerminkan fungsi aplikasi. Misalnya, aplikasi istilah bisnis kami mungkin disimpan di koleksi /db/apps/terms . Konvensinya adalah menggunakan bentuk jamak (“istilah” daripada “istilah”) untuk jenis konten utama yang disimpan dalam aplikasi.
Data Setiap aplikasi XRX harus menyimpan datanya dalam kumpulan data terpisah. Misalnya, aplikasi manajer istilah kami akan menyimpan semua data di /db/apps/terms/data. Dalam contoh ini, istilah pertama akan disimpan dalam file 1.xml dan yang kedua dalam file 2.xml , dll. Ketika pengguna menyimpan istilah baru, kita dapat menambahkan penghitung untuk menambahkan istilah baru.
Tampilan Setiap aplikasi XRX harus menyimpan tampilan data hanya-baca dalam kumpulan tampilan . Dalam contoh kita, pengelola istilah akan menyimpan tampilan data hanya-baca dalam koleksi /db/term/apps/terms/views . Perhatikan bahwa tampilan adalah semua fungsi yang mengubah tetapi tidak mengubah data XML asli.
Koleksi tampilan biasanya terlihat oleh semua pengguna yang memiliki akses baca ke data. Tampilan tidak perlu khawatir tentang mengunci catatan untuk mencegah pembaruan yang hilang. Alat yang mengubah atau mengedit data dapat disimpan di koleksi lain seperti edit. Hal ini memungkinkan sistem kontrol akses untuk membatasi siapa yang mengubah atau menghapus data.
Edit Setiap aplikasi XRX harus menyimpan fungsi editnya dalam kumpulan yang disebut edit. Untuk aplikasi manajer istilah kami, ini adalah /db/apps/term/edit . Fungsi edit termasuk menyimpan istilah baru, memperbarui istilah, dan menghapus istilah. Dengan mengelompokkan semua fungsi edit bersama-sama, mudah untuk menolak akses ke pengguna yang tidak memiliki izin untuk mengubah item dan untuk membuat fungsi logging yang konsisten untuk jejak audit.
Pencarian Setiap aplikasi XRX harus menyimpan fungsi pencariannya dalam kumpulan yang disebut pencarian . Untuk aplikasi manajer istilah kami, ini adalah /db/apps/term/search . Ada dua fungsi yang disimpan di sini. Formulir pencarian HTML sederhana (search.html) dan pencarian RESTful (service.xq).
Aplikasi tingkat lanjut terkadang menggabungkan fungsi-fungsi ini menjadi satu XQuery yang menghasilkan HTML. (Selain dua fungsi pencarian ini, file konfigurasi tambahan harus disimpan di /db/system/config/db/apps/terms/ kumpulan data yang menjelaskan bagaimana file diindeks untuk pencarian.)
AppInfo Setiap aplikasi XRX harus menyimpan informasi yang berkaitan dengan aplikasi dalam file XML dalam kumpulan aplikasi utama. Menurut konvensi, file ini disebut file app-info.xml. Informasi seperti nama aplikasi, deskripsi, penulis, versi, lisensi, dependensi, dll. harus disimpan dalam file ini. Tutorial ini tidak akan membahas struktur file ini, tetapi Anda mungkin melihatnya di banyak contoh program. Ini akan dibahas dalam Panduan Pemula XRX lainnya.
Anda selalu bebas untuk mengubah nama koleksi atau kueri, tetapi seperti yang disebutkan di atas, Anda harus bertanggung jawab atas kerangka kerja Anda sendiri dan Anda mungkin kehilangan beberapa manfaat menggunakan konvensi umum. Alasan menggunakan nama file generik seperti list-items.xq alih-alih nama file yang mencerminkan data, seperti list-terms.xq , mungkin tidak jelas bagi Anda pada awalnya, tetapi seperti yang akan Anda lihat nanti, ini lebih konvensi penamaan file umum memiliki manfaat ketika banyak aplikasi sedang dikelola.
![]()
![]()
![]()
![]()
![]()

Balisage Paper: Pola Desain XQuery
Balisage Paper: Pola Desain XQuery – Pola desain banyak digunakan di dalam komunitas berorientasi objek. Mereka terbukti matang dan solusi yang dapat digunakan kembali yang memfasilitasi pengembangan modul dengan kopling minimal.
Balisage Paper: Pola Desain XQuery

zorba-xquery – Selain itu, pola desain juga merupakan konstruksi tingkat tinggi yang berkontribusi untuk meningkatkan komunikasi antar pengembang. Saat ini, XQuery dan keluarga spesifikasinya digunakan lebih dari sekadar menanyakan koleksi dan dokumen XML. XQuery semakin banyak digunakan sebagai bahasa pemrograman multi-paradigma yang lengkap.
Baca Juga : Tutorial Cara Menggunakan XQuery
Selama dekade terakhir, pola desain menjadi semakin populer sebagai solusi umum dan dapat digunakan kembali untuk masalah desain perangkat lunak yang umum terjadi di komunitas berorientasi objek. Saat ini, hampir setiap aplikasi, komponen, atau API yang dikembangkan yang ditulis dalam bahasa berorientasi objek dibangun menggunakan pola desain (mis. [ Cooper2000 , Cooper2002 ]). Pola seperti itu meningkatkan pengembangan perangkat lunak dalam perspektif berikut [ Gamma1994 ]:
- Perangkat Lunak dan Desain yang Dapat Digunakan Kembali : Pola Desain sering kali merupakan pendorong utama untuk menyediakan enkapsulasi yang lebih baik dan mengurangi sambungan antar komponen perangkat lunak. Akibatnya, perangkat lunak yang menunjukkan pola desain lebih dapat digunakan kembali, fleksibel, dan dapat diperluas.
- Dokumentasi : Menggunakan nama pola dalam dokumentasi perangkat lunak memungkinkan pengembang mengenali/mengingat struktur dan desain API secara instan.
- Komunikasi dan Pengajaran : Pola desain merupakan bahasa umum untuk meningkatkan komunikasi antara perancang perangkat lunak dan analis. Selain itu, kosakata yang mapan memudahkan diskusi antara pengembang dengan latar belakang bahasa pemrograman yang berbeda.
Meskipun, diterima secara luas dan diterapkan dalam komunitas berorientasi objek, pola desain jarang dievaluasi di luar komunitas ini. Misalnya, di dunia fungsional mereka tidak pernah dievaluasi pada tingkat pemrograman aplikasi yang kompleks.
Dalam “Pola Desain Logika Fungsional” [ AntoyHanus02FLOPS ] pola desain telah dievaluasi dalam bahasa fungsional untuk memecahkan masalah spesifik pada tingkat yang sangat rendah; sedangkan [ Narbel2007 ] membahas pada tingkat meta. Dari perspektif ini, ketakutan Tom DeMarco dari tahun 1996 telah terbukti masuk akal:
“Karena Pola Desain menyebut dirinya hanya peduli dengan perangkat lunak berorientasi objek saja, saya khawatir pengembang perangkat lunak di luar komunitas objek mungkin mengabaikannya. Ini akan memalukan. […] Semua perancang perangkat lunak menggunakan pola; lebih memahami abstraksi yang dapat digunakan kembali pekerjaan kita hanya dapat membuat kita lebih baik dalam hal itu.” [ DeMarco96 ]
XQuery [ XQ11 ] — bahasa fungsional dan deklaratif — telah dirancang oleh World Wide Web Consortium sebagai bahasa pemrosesan XML tujuan umum, berguna dalam berbagai arsitektur dan lingkungan. Meskipun, pada awalnya, XQuery terutama digunakan untuk meminta data XML dalam sistem basis data (mis. [ XQueryInAction]), semakin menjadi bahasa pemrograman aplikasi yang lengkap.
Salah satu skenario di mana XQuery digunakan sebagai bahasa pemrograman lengkap disebut arsitektur XML ujung ke ujung. Dalam arsitektur seperti itu, XML adalah bentuk utama di mana informasi disimpan dan diproses. Informasi ini terus-menerus di seluruh pemanggilan program yang berurutan, dan XQuery adalah bahasa utama untuk mengakses informasi ini untuk pencarian, filter, transformasi, pembaruan, dan untuk menulis alur kerja aplikasi yang lebih kompleks.
Selain itu, dalam program tersebut, XQuery juga menjadi fasih dengan entitas web seperti layanan web, Atom, JSON, pesan HTTP, dan teknik otentikasi umum seperti OpenID atau OAuth. Bersama dengan spesifikasi ekstensinya, Pembaruan XQuery [XQUF ], XQuery Scripting [ XQSE ], dan XQuery Full Text [ XQFT ], XQuery saat ini bermain di liga yang sama dengan bahasa pemrograman tujuan umum seperti Java, Python, atau Ruby sambil mempertahankan keunggulannya dalam hal ekspresif dan dukungan kelas satu untuk menangani sumber daya web.
Secara keseluruhan, perubahan terbaru ini secara langsung berkaitan dengan pertumbuhan aplikasi XQuery yang kompleks [ Kaufmann2009 ]. Salah satu contoh aplikasi semacam itu dikembangkan oleh pelanggan perusahaan tempat penulis bekerja. Aplikasi ini adalah aplikasi Enterprise Resource Planning (ERP) yang seluruhnya ditulis dalam XQuery di atas Server Aplikasi Web Sausalito [ Sausalito2010 ].
Aplikasi ini terdiri dari 28.000 baris kode XQuery yang diimplementasikan dalam 135 modul XQuery. Dengan mengaudit aplikasi ini, kami menemukan gejala umum di basis kode dan proses pengembangan:
- Modul memiliki kopling yang kuat antara satu sama lain. Mereka didasarkan pada kolaborasi kompleks yang mengurangi kegunaannya kembali dalam kerangka kerja atau aplikasi lain. Dalam kebanyakan kasus, memperluas atau menyusun modul akan memerlukan pemfaktoran ulang kode yang mengganggu.
- Beberapa desain struktural berulang dirujuk menggunakan kosakata yang berbeda. Meskipun mereka dapat dilihat sebagai identik dari sudut pandang abstrak. Ini meningkatkan penghalang masuk ke basis kode secara signifikan.
Seperti yang dijelaskan di awal bagian ini, masalah seperti itu telah dipecahkan dalam komunitas berorientasi objek dengan mengembangkan dan menerapkan pola desain. Didorong oleh pengamatan ini, kami memutuskan untuk mulai menggunakan pola desain untuk mengatasi ketidaksesuaian yang dijelaskan di atas.
Selain memotivasi penggunaan pola desain untuk XQuery, kontribusi makalah ini adalah (1) untuk mengidentifikasi ketidaksesuaian dalam aplikasi dunia nyata dan (2) menunjukkan bagaimana ketidaksesuaian ini dapat diperbaiki dengan menggunakan pola desain. Secara khusus, kami menyajikan empat pola desain dan menjelaskan bagaimana masing-masing pola tersebut memecahkan satu masalah desain tertentu dalam aplikasi contoh (yang sedang berjalan) kami.
Sisa dari makalah ini disusun sebagai berikut. Di Bagian 2 , kami menjelaskan kasus penggunaan untuk contoh kami yang sedang berjalan. Contoh ini akan digunakan untuk menunjukkan masalah desain yang ada dalam aplikasi dunia nyata. Di masing-masing dari empat bagian berikut (yaitu Bagian 3 , 4 , 5 , dan 6 ), kami menyajikan satu pola desain untuk memecahkan salah satu masalah desain yang diidentifikasi.
Menjalankan Contoh: Aplikasi AtomPub
Protokol Penerbitan Atom adalah protokol berbasis HTTP untuk membuat dan memperbarui sumber daya di web. Akhir-akhir ini, menjadi banyak digunakan untuk mengimplementasikan API untuk layanan cloud. Contoh yang paling menonjol mungkin adalah Protokol Data Google .
AtomPub dibangun di atas Format Sindikasi Atom yang merupakan representasi XML dari kumpulan sumber daya yang sewenang-wenang (misalnya umpan web). Oleh karena itu, XQuery sangat cocok untuk mengimplementasikan layanan (cloud) berbasis AtomPub.
Kami menggunakan aplikasi AtomPub untuk menyajikan pola desain untuk XQuery. Aplikasi ini sangat cocok untuk banyak pola (umum) karena sebagian besar komponennya harus dapat digunakan kembali oleh komponen aplikasi lainnya. Selain itu, memanfaatkan perpustakaan yang ada (misalnya untuk komunikasi dan otentikasi HTTP) memerlukan beberapa keputusan desain yang cermat untuk dibuat. Pada dasarnya, aplikasi AtomPub terdiri dari dua komponen utama: klien dan server. Klien adalah aplikasi XQuery yang harus mengimplementasikan dua kasus penggunaan dasar berikut:
- Kasus Penggunaan 1: Kirim permintaan HTTP untuk membuat entri Atom.
- Kasus Penggunaan 2: Kirim permintaan HTTP untuk mengambil entri Atom tertentu. Entri yang dihasilkan harus diubah menjadi HTML.
Server adalah aplikasi yang berjalan di dalam server aplikasi berkemampuan XQuery. Artinya, fungsinya dipicu oleh permintaan HTTP. Fungsi-fungsi tersebut memiliki akses ke konten permintaan HTTP menggunakan modul (HTTP) yang disediakan oleh server aplikasi. Server bertindak sebagai mitra dari permintaan klien. Secara khusus, itu harus dapat menyelesaikan dua kasus penggunaan berikut:
- Kasus Penggunaan 3: Terima entri AtomPub dan simpan. Seharusnya dimungkinkan untuk menyimpan entri di lokasi yang berubah-ubah seperti sistem file atau koleksi XQuery.
- Use Case 4: Posting pesan di Twitter untuk setiap entri yang dibuat di Use Case 3.
Di bagian selanjutnya dari makalah ini, kami menunjukkan bagaimana tantangan desain dalam mengimplementasikan kasus penggunaan yang dijelaskan dapat diselesaikan dengan memanfaatkan pola desain. Kita mulai dengan Kasus Penggunaan 1 dan 2 dari klien di Bagian 3 dan 4 , masing-masing. Setelah itu, Bagian 5 dan 6 menjelaskan desain dan implementasi Kasus Penggunaan 3 dan 4.
Rantai Tanggung Jawab
Di bagian ini, kita membahas implementasi Use Case 1. Artinya, kita ingin mengembangkan program XQuery yang memublikasikan entri Atom ke server berkemampuan AtomPub. Karena tidak semua orang diizinkan untuk memublikasikan entri, server AtomPub memerlukan autentikasi menggunakan mekanisme autentikasi HTTP dasar.
Protokol AtomPub menetapkan bahwa entri diterbitkan dengan mengirimkan permintaan HTTP POST ke server. Payload permintaan ini berisi entri yang akan dipublikasikan. Otentikasi HTTP dasar memerlukan nama pengguna dan kata sandi untuk menjadi bagian dari HTTP-Header.
Untuk membuat panggilan HTTP dalam program XQuery, kami memutuskan untuk mengandalkan (standar de-facto) Klien HTTP EXPath. Klien HTTP ini bekerja dengan melewatkan elemen XDM yang menjelaskan permintaan ke fungsi yang disebut send-request.
Untuk mengimplementasikan kasus penggunaan pertama kami, klien AtomPub dapat diimplementasikan dengan ketergantungan kabel antara modul yang bertanggung jawab untuk mengonfigurasi dan mengirim permintaan HTTP dan modul yang bertanggung jawab untuk otentikasi.
Namun, ini jelas akan membuat klien AtomPub kurang fleksibel dan dapat digunakan kembali dalam skenario lain. Misalnya, mengubah mekanisme otentikasi menjadi sesuatu seperti OAuth atau OpenID akan memerlukan perubahan yang mengganggu pada modul AtomPub atau akan menghasilkan basis kode lain yang sangat berlebihan.
Untuk meningkatkan fleksibilitas dan penggunaan kembali aplikasi kami, kami menetapkan dua persyaratan desain berikut. Klien AtomPub harus dipisahkan dari
- mekanisme otentikasi apa pun yang dapat berkolaborasi dengannya saat runtime.
- implementasi tertentu dari lapisan transport, yaitu klien HTTP.
Untuk memenuhi persyaratan ini, kami telah merancang klien AtomPub menggunakan pola Rantai Tanggung Jawab [ Gamma1994 ]. Maksud dari pola ini adalah sebagai berikut:
Kurangi penggabungan antara modul yang berbeda dengan memindahkan dependensi bersarang di luar modul dan mengintegrasikan fungsi dependen secara berurutan ke dalam rantai. Lewati item di sepanjang rantai dan berikan masing-masing fungsi ini kesempatan untuk memanipulasi atau memproses item tersebut.
![]()
![]()
![]()
![]()
![]()

Tutorial Cara Menggunakan XQuery
Tutorial Cara Menggunakan XQuery – W3C XQuery adalah bahasa kueri untuk XML. Kasus penggunaan paling umum untuk XQuery melibatkan penerbitan XML untuk membuat pesan XML untuk Web, situs web dinamis, atau aplikasi penerbitan. Data asli dapat ditemukan dalam file XML, atau mungkin dalam penyimpanan data seperti database relasional.
Tutorial Cara Menggunakan XQuery

zorba-xquery – Beberapa kueri dalam tutorial ini beroperasi pada XML yang disimpan dalam file, beberapa pada tampilan XML dari database relasional, dan beberapa bekerja pada keduanya. Semua contoh dalam tutorial ini telah diuji dengan DataDirect XQuery.
Baca Juga : Memfilter Kolom XML Menggunakan XQuery di SQL Server
Karena semua implementasi XQuery tidak mengakses data relasional dengan cara yang sama, tutorial ini menggunakan fn:collection(), yang digunakan DataDirect XQuery untuk mengakses tabel relasional.
Sebagian besar fungsi XQuery, seperti operator aritmatika, perbandingan, panggilan fungsi, dan fungsi, akrab bagi sebagian besar programmer. Tutorial ini berfokus pada tiga kemampuan utama XQuery yang membuatnya berbeda, dan yang mendasar untuk memproses dan membuat XML.
- Ekspresi jalur, yang dapat menemukan apa pun dalam dokumen XML.
- Konstruktor XML, yang dapat membuat dokumen XML apa pun.
- Ekspresi FLWOR (diucapkan “ekspresi bunga”), yang memungkinkan data digabungkan untuk membuat struktur XML baru. Mereka mirip dengan pernyataan SQL Select yang memiliki klausa From dan Where, tetapi disesuaikan untuk pemrosesan XML.
Bersama-sama, kemampuan ini mempermudah pemrosesan dan pembuatan XML dengan XQuery dibandingkan dengan bahasa lain saat menggunakan data dari XML atau sumber relasional.
Ringkasan
Tiga kemampuan utama XQuery yang membuatnya berbeda adalah kemampuan untuk:
- Temukan konten apa pun dalam dokumen XML
- Buat dokumen XML apa pun
- Gabungkan data untuk membuat struktur XML baru menggunakan ekspresi FLWOR
DataDirect XQuery, sebuah implementasi dari XQuery, memungkinkan Anda untuk mengkueri sumber relasional dan XML dan menggabungkan data menjadi satu hasil.
Menemukan Node XML: Ekspresi Jalur
Sama seperti SQL harus dapat mengakses setiap baris atau kolom dalam tabel relasional, XQuery harus dapat mengakses setiap node dalam dokumen XML. Struktur XML memiliki hierarki dan urutan, dan dapat berisi struktur kompleks.
Ekspresi jalur secara langsung mendukung hierarki dan urutan, dan memungkinkan Anda menavigasi struktur XML apa pun. Di bagian ini, kita membahas ekspresi jalur menggunakan dokumen XML, lalu memperlihatkan ekspresi jalur yang digunakan pada tampilan XML tabel relasional.
Ekspresi Jalur untuk Sumber Relasional
Ketika XQuery digunakan untuk mengkueri data relasional, tabel relasional diperlakukan seolah-olah mereka adalah dokumen XML, dan ekspresi jalur bekerja dengan cara yang sama seperti yang mereka lakukan untuk XML. Karena tabel relasional memiliki struktur yang sederhana, ekspresi jalur yang digunakan untuk tabel biasanya sederhana.
Tidak ada cara standar untuk mengakses tabel relasional di XQuery, jadi setiap implementasi XQuery memiliki caranya sendiri untuk melakukan ini. Di DataDirect XQuery, kami menggunakan fn:collection() untuk mengakses tabel relasional. Misalnya, ekspresi berikut mengakses tabel holding.
collection(‘holdings’)
Setiap implementasi XQuery juga harus memutuskan bagaimana memetakan tabel relasional ke dalam XML dalam tampilan XML. Standar SQL 2003 telah menetapkan satu set standar pemetaan untuk tujuan ini sebagai bagian dari SQL/XML.
Berikut adalah pemetaan SQL/XML dari tabel kepemilikan; pemetaan ini mewakili setiap baris sebagai elemen kepemilikan, dan mewakili setiap kolom tabel (userid, stockticker, saham) sebagai elemen yang merupakan anak dari elemen kepemilikan.
<holdings>
<userid>Jonathan</userid>
<stockticker>AMZN</stockticker>
<shares>3000</shares>
</holdings>
…
<holdings>
<userid>Minollo</userid>
<stockticker>AMZN</stockticker>
<shares>3000</shares>
</holdings>
…
Setelah Anda memahami struktur tampilan XML, Anda dapat dengan mudah melihat bagaimana ekspresi jalur diterapkan padanya. Misalnya, ekspresi berikut menemukan kepemilikan untuk pengguna yang userid-nya adalah “Minollo”.
collection(‘holdings’)/holdings[userid=’Minollo’]
Karena data relasional ditanyakan seolah-olah itu XML, beberapa orang berpikir bahwa tabel relasional sebenarnya diekstraksi dari database, diubah menjadi dokumen XML, dan kemudian ditanyakan, tetapi ini akan sangat tidak efisien. Bagi pengguna, DataDirect XQuery membuat semua data terlihat seperti XML, tetapi untuk database SQL, implementasinya menggunakan SQL. Sebelum mengevaluasi ekspresi sebelumnya, DataDirect XQuery mengonversinya menjadi ekspresi SQL yang mirip dengan ini:
SELECT userid, stockticker, shares
FROM holdings
WHERE userid=’Minollo’
Membuat XML: Konstruktor XML
Sekarang kita telah melihat bagaimana menemukan sesuatu dalam dokumen XML atau tabel relasional, mari kita pelajari cara membuat struktur XML baru menggunakan konstruktor XML.
Konstruktor XML literal
Konstruktor paling sederhana adalah konstruktor XML literal , yang menggunakan sintaks yang sama dengan XML. Misalnya, teks XML berikut juga merupakan ekspresi XQuery yang membuat struktur XML yang setara.
<stock role=’eg’>
<ticker>AMZN</ticker>
<shares>3000</shares>
</stock>
Contoh ini hanya menggunakan elemen dan atribut, tetapi instruksi pemrosesan, komentar, dan bagian CDATA juga dapat digunakan dalam konstruktor XML.
Ekspresi Terlampir
Dalam konstruktor XML literal, Anda bisa menggunakan kurung kurawal ({}) untuk menambahkan konten yang dihitung saat kueri dijalankan. Ini disebut ekspresi tertutup . Misalnya, ekspresi berikut membuat elemen tanggal yang isinya adalah tanggal saat ini, yang dihitung saat kueri dijalankan.
<date>{ current-date() }</date>
Hasilnya akan menjadi elemen bernama tanggal dengan tanggal saat ini. Untuk melihat mengapa ekspresi tertutup diperlukan, pertimbangkan ekspresi berikut:
<date> current-date() </date>
Ekspresi ini dievaluasi ke elemen XML berikut:
<date> current-date() </date>
Ekspresi jalur sering digunakan dalam ekspresi tertutup. Ekspresi berikut membuat elemen portofolio untuk Minollo, lalu mengekstrak kepemilikan Minollo dari tabel kepemilikan.
<portfolio name=’Minollo’>
{ collection(‘holdings’)/holdings[userid=’Minollo’] }
</portfolio>
Contoh Ikhtisar
Dokumen berikut menjelaskan cara menginstal, mengonfigurasi, dan menjalankan contoh DataDirect XQuery®. Unduh contoh gratis hari ini dan pelajari betapa mudahnya mengintegrasikan, membuat kueri, dan memublikasikan sumber data heterogen menggunakan DataDirect XQuery®.
designPreviewDemo.zip : Berisi semua file contoh, termasuk file XQuery, Skema XML, lembar gaya XSLT, file Database, dan file proyek Stylus Studio yang diperlukan untuk menjalankan contoh XQuery.
![]()
![]()
![]()
![]()
![]()
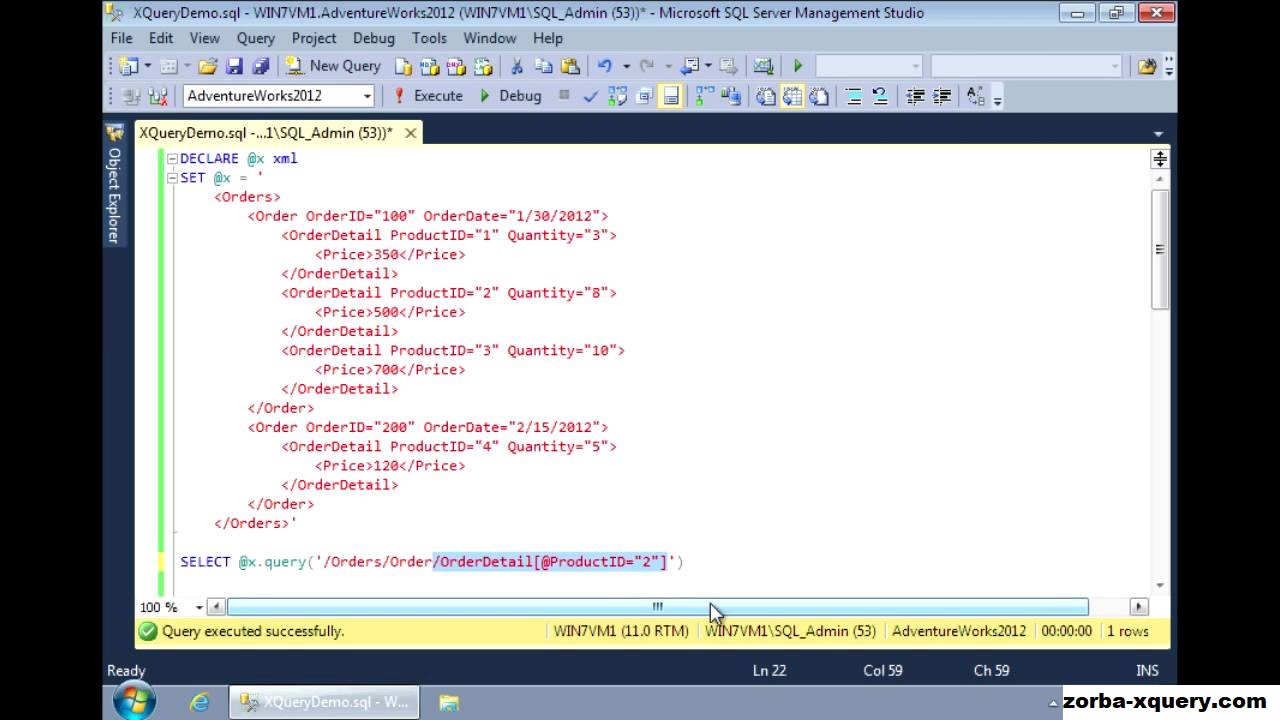
Memfilter Kolom XML Menggunakan XQuery di SQL Server
Memfilter Kolom XML Menggunakan XQuery di SQL Server – XQuery di SQL Server membantu untuk meminta dan mengekstrak data dari dokumen XML. XQuery memberikan pendekatan yang berbeda untuk mendapatkan informasi dari dokumen XML dan yang setara dapat digunakan untuk menerapkan filter data atau klausa where pada elemen XML juga.
Memfilter Kolom XML Menggunakan XQuery di SQL Server

zorba-xquery – SQL Server menyediakan fitur XQuery untuk menanyakan tipe data XML atau membuat kueri dengan kolom XML dengan XPATH. Menggunakan XQuery, pengguna dapat Menyisipkan, Memperbarui, dan Menghapus dengan node XML dan nilai node dalam kolom XML.
Baca Juga : XQuery Pengarsip: Alat Bantu Pencarian EAD sebagai Data
SQL Server 2005 atau edisi yang lebih baru, memungkinkan penggunaan parameter input tipe data XML dalam prosedur tersimpan dan mendukung penggunaan fungsi XML yang berbeda untuk mengekstrak informasi dari node XML dan sebaliknya dengan mendapatkan atribut di kolom tipe data XML juga.
Pada artikel ini, kita akan berlatih dengan tipe data Querying XML menggunakan XQuery untuk menyalurkan informasi dengan node XML dan atribut dengan beberapa contoh. Di sini, kami telah menggunakan satu tabel contoh dengan data sampel untuk penjelasan yang lebih baik.
Mengambil nilai dari node XML target
Format tabel dari dokumen XML dengan bifurkasi node XML sebagai nama kolom yang menggunakan SQL Server dapat diselesaikan dengan bantuan XQuery. XQuery akan mengembalikan nilai node XML dalam model tabel dengan kombinasi fungsi node() dan value() pada kolom XML. fungsi node() mengakui lokasi node XML sebagai XPATH dalam dokumen XML dan fungsi value() mengembalikan node XML atau nilai atribut yang node direferensikan di dalam fungsi dengan tipe data.
XPath di dalam XQuery digunakan untuk menemukan lokasi node XML di kolom XML. XQuery mengembalikan nilai dari simpul atau atribut XML yang ditentukan berdasarkan parameter. XQuery menyelesaikan logika bisnis dengan manipulasi data pada node XML dan nilai atribut di dalam kolom tipe data XML dengan permintaan tersebut.
Di sini, kami membuat kueri contoh tipe data XML menggunakan XQuery dengan CROSS APPLY & OUTER APPLY. Keduanya adalah kasus penggunaan yang sangat berbeda karena CROSS APPLY akan bekerja sebagai INNER JOIN dengan fungsi node(). Jika jalur ada di kolom XML, maka baris akan diambil di kumpulan hasil. Jika tidak ada, maka baris itu akan disaring. Nah, OUTER APPLY akan berfungsi sebagai OUTER JOIN; jika XPATH tidak ada di kolom tipe data XML, maka baris tersebut akan diambil dengan NULL sebagai nilai elemen XML dalam kumpulan hasil.
Dalam contoh Kueri di atas, kami baru saja mengembalikan nilai elemen XML dari dokumen XML. Tapi, pernyataan XQuery serupa juga berfungsi di klausa WHERE. Misalnya, kembalikan baris dari tabel di mana karyawan menggunakan “ Bank internasional ” sebagai “ nama bank ”. Sesederhana itu, pengguna dapat menerapkan filter pada nilai elemen XML dalam pernyataan WHERE menggunakan subquery dengan mengambil hasil kueri di dalam alias kueri.
Menerapkan filter pada simpul XML:
Fungsi node() jauh lebih matang untuk memisahkan informasi ke format tabel berbasis baris-kolom dari node XML dengan tipe data XML query yang menggunakan fungsi query() atau nilai(). Penggunaan fungsi-fungsi ini semakin diperlukan saat Anda menyalin atau memindahkan beberapa node dari kolom tipe data XML. Seperti contoh tipe data XML Kueri di atas, Data dikeluarkan dari XML dengan menentukan node XML dengan jalur. Sekarang, kita hanya membutuhkan baris-baris yang informasi XML-nya memenuhi kondisi WHERE dengan node XML.
Di sini, saya juga menggunakan nilai simpul XML AnnualRevenue yang diekstraksi dalam ketentuan WHERE dari SELECT Query di atas. Mirip dengan kueri normal, kita dapat menggunakan fungsi value() dalam klausa WHERE. Pengguna tidak dapat menggunakan alias pernyataan XQuery dalam ketentuan WHERE. Memang, jika kita mengambil seluruh pernyataan itu di dalam Query dalam dengan alias tabel. Namun, itu bukan cara yang tepat untuk kinerja kueri.
Di sini, notasi titik digunakan untuk menghubungkan logika kueri dengan nama kolom untuk node tertentu. Kami mengurai fungsi query() dengan pernyataan XPATH yang menyarankan tipe data Querying XML untuk mengambil Pendapatan Tahunan untuk karyawan; yang tokonya memiliki pendapatan lebih dari 100.000. Setiap garis miring dalam proklamasi XPATH mewakili indeks simpul ke dalam dokumen XML.
Metode ini mengambil pernyataan XQuery dalam Query normal dan mengembalikan casting nilai tunggal dengan tipe data seperti yang disebutkan dalam pernyataan XQuery. Sangat penting untuk menerapkan bahwa XPATH mengacu pada seluruh dokumen XML, yang telah digunakan dalam kueri. Ini akan mengambil setiap node atau atribut yang cocok dengan lokasi node yang telah ditentukan, yang dapat mengembalikan beberapa elemen juga, jika ada beberapa lokasi node dengan XPATH yang sama.
Tangani namespace di XQuery:
Dokumen XML dapat memiliki namespace dalam hierarki node XML. Jadi, Anda dapat menyebutkan pegangan namespace di XPATH atau menentukan * untuk melompati namespace.
ADA dengan XQuery
Fungsi XML existing() mengembalikan nilai BIT (0 atau 1) dan menunjukkan bahwa nilai tersebut ada atau tidak dengan pengaturan yang direferensikan. Misalnya, nilai elemen XML berkoordinasi dengan ekspresi XPATH dalam fungsi kemudian mengembalikan 1 lain 0. Dengan cara ini, kita harus memiliki kondisi sama dengan 1 atau 0. Ketika pengguna ingin mencocokkan kondisi, maka ada( ) sama dengan 1 dan untuk tidak ada bandingannya, seharusnya 0.
Klien dapat menempatkan berbagai kondisi dalam satu proklamasi XPATH. Pendekatan eksis() ini di mana penyediaan secara konsisten meningkatkan eksekusi ketika kita memiliki XML yang lebih besar dengan banyak data untuk diproses.
ADA termasuk nilai simpul XML:
Sesederhana pengguna dapat menggunakan beberapa kombinasi dari ada (), node (), nilai () dan kueri () dalam satu kueri SQL. Semuanya tergantung pada permintaan tentang sifat data untuk mencapai kinerja dan logika bisnis yang lebih baik.
Pengembang dapat menerapkan salah satu pendekatan di atas dengan simpul XML untuk memisahkan informasi dari kolom atau variabel XML dan dengan menggunakan ketentuan WHERE untuk menempatkan kondisi yang sama untuk menyaring nilai tertentu dari simpul atau elemen XML.
![]()
![]()
![]()
![]()
![]()

XQuery Pengarsip: Alat Bantu Pencarian EAD sebagai Data
XQuery Pengarsip: Alat Bantu Pencarian EAD sebagai Data – XQuery adalah sederhana, namun kuat, bahasa scripting yang dirancang untuk memungkinkan pengguna tanpa pelatihan pemrograman formal untuk mengekstrak, mengubah, dan memanipulasi data XML. Selain itu, bahasa ini merupakan standar yang diterima dan rekomendasi W3C seperti standar saudaranya, XML dan XSLT.
XQuery Pengarsip: Alat Bantu Pencarian EAD sebagai Data

zorba-xquery – Dengan kata lain, raison d’etre XQuery sangat sesuai dengan kebutuhan arsiparis saat ini. Berikut ini adalah gambaran singkat, pragmatis, XQuery untuk arsiparis yang akan memungkinkan arsiparis dengan pemahaman yang tajam tentang XML, XPath, dan EAD untuk mulai bereksperimen dengan memanipulasi data EAD menggunakan XQuery.
Baca Juga : Implementasi Bahasa pemrogaman XQuery
Pengarsip tidak perlu dijual di XML – repositori di seluruh negeri telah menjadi pengguna awal teknologi ini sejak tahun 1990-an. Pada dasarnya semua standar data arsip telah dikembangkan untuk XML (EAD) atau telah diadaptasi untuk penggunaannya (MARC). Keterbukaan, standarisasi, fleksibilitas struktural, dan kemudahan penggunaan telah membuktikan bahwa XML adalah alat yang kuat dan sentral bagi arsiparis abad ke-21.
Namun, sementara arsiparis telah lama menyimpan alat bantu pencarian di EAD, ada perbedaan keterampilan utama antara pengkodean alat bantu pencarian dan benar-benar melakukan apa pun dengan data itu. Cara paling umum yang digunakan arsiparis untuk menggunakan data XML adalah melalui lembar gaya XSLT, sering kali untuk menampilkan data dalam daftar yang panjang dan dapat digulir.
Baru-baru ini, ada gerakan untuk mengembangkan sistem informasi arsip yang lebih canggih dan ramah pengguna. Selain itu, arsip yang telah banyak berinvestasi dalam mengembangkan alat bantu pencarian EAD akan senang untuk mengotomatisasi penggunaan kembali data ini untuk akses yang lebih mudah, kegiatan penjangkauan, dan banyak lagi. Cukup sederhana, memanipulasi dan memformat ulang data XML telah menjadi keterampilan yang berharga bagi arsiparis dan XQuery menyediakan metode sederhana dan mudah dipelajari untuk melakukan hal itu.
Ini sama sekali bukan pengenalan yang komprehensif untuk XQuery – untuk itu, arsiparis perlu mencari sumber daya yang lebih tradisional seperti yang disediakan di akhir artikel ini. Namun, memulai dengan studi XQuery yang panjang dan komprehensif mungkin hanya menunda pengalaman langsung dan membuat frustrasi orang yang tidak sabar. Pengarsip mungkin merasa lebih mudah untuk menyelami dan bereksperimen dengan bahasa tersebut sebelum mencari pemahaman yang lebih luas. Yang dibutuhkan arsiparis adalah panduan sederhana dan mudah diakses untuk memulainya. Jika Anda mengalami masalah saat menggunakan panduan ini, coba cari masalah Anda di Stack Overflow atau dengan mesin pencari favorit Anda.
XQuery dan XSLT
Sekarang, bagi arsiparis yang memiliki pengalaman dengan XSLT, XQuery terdengar sangat mirip dengan transformasi lembar gaya XML ini. XSLT juga dapat digunakan untuk mengubah dan memanipulasi data XML, digunakan secara luas jauh sebelum XQuery, dan memiliki keuntungan karena dikompilasi oleh browser web. Ini berarti data XML dapat diproses di sisi server dengan XSLT sedangkan browser saat ini tidak dapat membaca XQuery tanpa add-on atau solusi khusus.
Pengarsip tidak harus belajar dan beradaptasi dengan perangkat lunak baru untuk mencoba XSLT – mereka baru saja bereksperimen dengan transformasi stylesheet dengan menggunakan browser web yang mereka kenal. Ini mungkin mengapa XSLT lebih banyak digunakan dalam komunitas arsip. Sekolah pascasarjana biasanya mengajarkan XSLT dan banyak arsiparis telah menghabiskan banyak waktu untuk mempelajari standar tersebut. Belum,
Mengapa XQuery?
Jadi mengapa menggunakan atau mempelajari XQuery? Yang terpenting, ini jauh lebih sederhana dan tidak terlalu bertele-tele daripada XSLT, yang ditulis dalam XML itu sendiri. Ini membuat XSLT membutuhkan lebih banyak karakter untuk melakukan tindakan yang sama daripada XQuery (lihat lampiran untuk perbandingan). Meskipun ini tidak tampak seperti keuntungan besar, itu sebenarnya. Skrip XQuery lebih bersih, lebih sederhana, seringkali lebih cepat untuk ditulis, dan lebih mudah dirawat.
Hal ini membuat pengguna lebih mungkin untuk benar-benar menggunakan bahasa tersebut dan memanfaatkan data XML mereka dengan lebih efektif. Seperti yang dikatakan Steve Krug tentang pengujian kegunaan: jika suatu tugas sulit, itu akan dihindari, sedangkan jika tugas lebih mudah, semakin besar kemungkinan itu akan dilakukan lebih sering. Pengarsip yang menghindari memperbarui file XSLT besar yang berasal dari buku masak EAD asli pasti akan bersimpati.
Kedua, XQuery lebih kuat dari XSLT. Itu dapat melakukan lebih banyak fungsi dan membuat tugas-tugas kompleks lebih mudah. Fungsi merupakan inti dari kedua bahasa – anggap mereka sebagai kata ajaib yang telah diprogram sebelumnya yang membantu pengguna untuk dengan mudah melakukan tindakan kompleks dengan data mereka. Di XQuery, pengguna tingkat lanjut bahkan dapat menulis fungsi mereka sendiri dengan lebih mudah daripada di XSLT. Sementara XSLT 3.0 telah memperkenalkan lebih banyak fungsi, ini bahkan tidak dapat dibandingkan dengan XQuery yang memiliki 225 fungsi bawaan yang dapat dengan mudah memeriksa apakah suatu elemen ada atau berisi data, mengedit string karakter dengan cara yang rumit, menentukan posisi relatif elemen, dan banyak lagi. lebih banyak alat yang memungkinkan pengguna mendapatkan hasil maksimal dari data mereka.
Jadi, XQuery memungkinkan arsiparis untuk berbuat lebih banyak dengan data mereka, dan membuat mereka lebih mungkin melakukannya. Namun, keuntungan terbesarnya mungkin karena memaksa mereka untuk menganggap file EAD sebagai data bukan sebagai daftar atau indeks. Tidak seperti XSLT, XQuery dirancang untuk query XML – ini dirancang agar pengguna menanyakan data apa yang mereka inginkan dan bagaimana mereka menginginkannya.
Ini akan memaksa arsiparis untuk melihat deskripsi mereka sebagai unit informasi yang terpisah. Deskripsi tidak hanya memiliki hubungan kontekstual dengan deskripsi sekitarnya yang menyampaikan urutan asli, tetapi juga dapat berguna untuk mengembalikan deskripsi terpisah sebagai hasil pencarian atau menyusun ulang data untuk menampilkan informasi dengan cara yang berbeda (dan mungkin lebih mudah diakses).Dengan demikian, EAD akan menjadi penyimpan data deskripsi arsip sementara antarmuka tambahan atau sistem informasi menanyakannya daripada mengubah atau memformat ulangnya.
Apa yang Saya Perlukan untuk Menggunakan XQuery?
Meskipun XQuery tidak dapat berjalan secara native di browser umum, ada beberapa cara untuk mulai bereksperimen dengan kueri XML. Pertama, Saxon memproses XQuery serta XSLT, jadi jika Anda memiliki akses ke perangkat lunak desktop seperti Oxygen XML Editor atau server yang menjalankan Saxon, Anda harus dapat menjalankan kueri seperti Anda menjalankan XSLT. Saxon juga dapat diatur untuk dijalankan di desktop menggunakan Java Runtime Environment melalui baris perintah.
Selain itu, eXist-db adalah database XML open source yang dibuat khusus untuk menjalankan XQuery dengan arsitektur RESTful – pada dasarnya, eXist dimaksudkan untuk menjadi bagian dari layanan web tipikal. Di sini perangkat lunak berjalan di server (atau disimulasikan menggunakan Java Runtime Environment) dan pengguna masuk ke antarmuka web untuk mengunggah dan mengelola data XML. Skrip XQuery kemudian dapat dijalankan di dalam halaman web oleh pengguna akhir. Karena HTML adalah XML itu sendiri, dengan eXist XQuery dapat mengedit, mengubah, dan meminta HTML dan berfungsi seperti bahasa skrip sisi server.
Alat Bantu Pencarian Perpustakaan Universitas Princeton memanfaatkan eXist-db. Terakhir, Zorba adalah prosesor XQuery yang dapat berjalan di baris perintah atau sebagai ekstensi untuk PHP atau Python. Ini memungkinkan XQuery dijalankan dalam aplikasi web PHP atau Python sisi server.
Metode di atas untuk menjalankan skrip XQuery mungkin tampak menakutkan atau membingungkan bagi banyak arsiparis, terutama mereka yang memiliki sedikit pengalaman dengan server dan arsitektur web. Ini, dibandingkan dengan dukungan browser asli, tampaknya menjadi salah satu alasan XSLT tetap populer. Namun, ada juga cara yang lebih mudah dan lebih mudah diakses untuk bereksperimen dengan XQuery. Lagi pula, itu hanya teks.
Mungkin cara termudah untuk mulai bermain dengan XQuery adalah menggunakan BaseX, database XML open-source yang dikembangkan bersama dengan antarmuka GUI desktop. Yang terpenting, BaseX adalah platform independen dan dapat diinstal pada mesin desktop Windows atau Mac terbaru seperti program biasa. Program ini juga berlisensi BSD, artinya gratis untuk diunduh dan digunakan dengan atribusi. Hal terbaik tentang BaseX GUI adalah kesederhanaannya. Secara default, antarmuka memiliki empat panel utama, atau jendela: panel Editor, yang mencakup panel Proyek untuk memilih file; panel Info Kueri; dan panel Hasil. Panel Editor dan Hasil paling penting bagi pengguna baru yang mungkin kewalahan dengan melihat terlalu banyak bagian belakang.
Panel Editor berfungsi seperti editor teks dasar: Skrip XQuery dapat ditulis secara manual dan file dapat dibuka atau disimpan menggunakan ikon. Setelah skrip ditulis, pengguna dapat menekan ikon “Jalankan kueri”, yang terlihat seperti simbol putar, dan hasilnya muncul di panel Hasil. Di sini hasilnya dapat disimpan atau ditimpa oleh hasil baru dengan menjalankan kueri lain. Kesederhanaan ini memungkinkan untuk percobaan dan kesalahan yang mudah, penting bagi arsiparis yang tidak berpengalaman dengan pemrograman untuk bereksperimen dengan memanipulasi data.
![]()
![]()
![]()
![]()
![]()

Implementasi Bahasa pemrogaman XQuery
Implementasi Bahasa pemrogaman XQuery – XQuery telah mendapatkan reputasi sebagai salah satu yang paling hati-hati dikembangkan dan, oleh karena itu, berkembang paling lambat standar W3C.
Implementasi Bahasa pemrogaman XQuery

zorba-xquery – Alasan utamanya adalah bahwa ada sedikit pengalaman industri dalam pengambilan informasi yang disimpan dalam XML.
Banyak perusahaan masih berinovasi di bidang ini dan menghasilkan banyak informasi empiris yang harus diproses dan disaring sebelum tingkat kenyamanan yang memuaskan dengan masalah query XML tercapai.
XQuery masih bukan Rekomendasi W3C. Draf kerja terbaru telah menjadi langkah maju yang signifikan dan kurang lebih diimplementasikan oleh sejumlah vendor yang berbeda. Beberapa pelaku pasar seperti BEA dan Software AG memutuskan untuk merilis produk berdasarkan draft kerja ini dan tidak mengikuti standar hingga menjadi rekomendasi W3C. Keterlambatan dalam rilis final adalah salah satu alasan mengapa kami belum melihat kampanye pemasaran implementasi skala besar.
Baca Juga : Mempelajari XQuery Dan EXist-db
Alasan lain untuk tingkat publisitas XQuery yang rendah adalah sejauh ini hanya ada sedikit bukti bahwa penyimpanan data XML dapat menjadi teknologi di mana-mana yang akan menggeser penyimpanan data relasional. Meskipun database XML menunjukkan banyak fitur berharga dan eksotis, mereka dapat dibandingkan dengan rekan-rekan mereka yang berorientasi objek dalam hal penetrasi pasar. Keduanya tampaknya sangat nyaman untuk memecahkan serangkaian masalah khusus dan keduanya tampaknya bekerja dengan baik dengan sistem ukuran kecil dan menengah. Namun, karena kompleksitas masalah penyimpanan meningkat, baik XML maupun toko berorientasi objek tampaknya tidak dapat menskalakan serta solusi relasional. Sebenarnya, melakukan serta solusi relasional mungkin tidak akan memotong mustard juga. Hanya lompatan kuantum dalam teknologi yang akan memindahkan gunung investasi dari warisan RDBMS.
XQuery akan menemukan tempatnya di bawah matahari di tanah yang sedikit diantisipasi oleh penulisnya. Kita sedang menyaksikan era integrasi perangkat lunak antar-perusahaan. Setelah puluhan tahun berinvestasi dalam infrastruktur TI, perusahaan mencapai titik di mana mempertahankan begitu banyak produk perangkat lunak yang berbeda lebih mahal daripada kenyamanan mereka. Karena semakin banyak program integrasi dimulai, menjadi jelas bahwa tidak ada solusi siap pakai yang akan menyelesaikan masalah dengan cepat. Tidak realistis untuk mengharapkan bahwa vendor perangkat lunak dengan ukuran yang cukup besar akan membangun paket integrasi yang menghasilkan jutaan cara berbeda untuk aplikasi perusahaan dapat berintegrasi satu sama lain.
Integrasi longgar adalah kata hari ini. Menulis ulang bagian penting dari sistem warisan untuk membuatnya bekerja sama adalah utopia yang tidak dapat diperoleh. Sebaliknya, setiap aplikasi, terlepas dari apakah itu berjalan pada mainframe, Java, Windows .NET, Unix, C++, CORBA, PHP atau Perl, memperlihatkan fungsionalitas intinya melalui pembungkus layanan web yang tipis. Setiap perusahaan yang menjalankan subset dari aplikasi ini memiliki cara unik untuk menggunakannya. Setelah persyaratan integrasi jelas,
Berkat sifat layanan web yang tidak mencolok, aplikasi yang ada dapat terus bekerja seperti biasanya selama beberapa waktu. Keuntungan lain dari layanan web adalah mereka tidak bergantung pada platform. Pertanyaan logisnya menjadi, lalu, apa cara terbaik untuk menjembatani dua antarmuka XML? Kami membutuhkan bahasa yang nyaman untuk menulis logika bisnis dan dapat memanipulasi data XML secara native. Di sinilah XQuery bersinar. Ini adalah bahasa fungsional yang sangat ekspresif dengan sintaks yang sederhana dan familiar serta koneksi organik ke struktur data XML.
Beberapa vendor server perusahaan yang lebih besar sudah bergabung dengan ide ini. BEA bergerak agresif ke arah ini dengan penawaran Integrasi Weblogic-nya. Vendor perangkat lunak perusahaan banyak berinvestasi dalam IDE visualnya untuk mempercepat proses pengembangan yang menghubungkan aplikasi, database, sistem informasi perusahaan, dan proses bisnis. Software AG juga menjajaki potensi XQuery untuk integrasi aplikasi, dengan Tamino Server 4.1, meskipun fokus utamanya masih pada penyimpanan data.
IBM, Oracle, dan Microsoft belum menjual produk komersial berdasarkan XQuery, meskipun mereka menawarkan kit pengembangan sampel. Di komunitas open source, QEXO implementasi GNU XQuery sedang dikembangkan secara aktif. Adopsi XQuery akan dipercepat jika ada jembatan yang nyaman untuk teknologi arus utama. IBM dan Oracle menyadari hal itu dan secara bersama-sama meluncurkan upaya untuk menghubungkan XQuery ke Java melalui paket API standar di bawah javax.xml.xquery.
Inisiatif ini sedang dikembangkan melalui JSR 225. Oracle akan menulis Implementasi Referensi, dan IBM akan menyediakan kit Kompatibilitas Teknologi. Visi API ini adalah menjadi perpanjangan dari JDBC, sehingga koneksi dan manajemen transaksi dapat dimanfaatkan. API juga akan dibangun di atas JAXP, JAXB, dan API XML lainnya. Setengah lusin pemain utama di pasar Java dan XML telah bergabung dengan kelompok kerja sebagai peninjau.
![]()
![]()
![]()
![]()
![]()
Mempelajari XQuery Dan EXist-db
Mempelajari XQuery Dan EXist-db – Artikel ini memberikan tips dan sumber daya untuk pendatang baru di XQuery dan eXist-db.
Mempelajari XQuery Dan EXist-db

zorba-xquery – Ini adalah panduan untuk membantu Anda mempelajari XQuery. Ini berisi beberapa informasi latar belakang singkat tentang XQuery dan kemudian mencantumkan sejumlah sumber daya yang dapat Anda gunakan untuk mempelajari XQuery. XQuery unik dalam tumpukan pengembangan karena menggantikan SQL dan lapisan perangkat lunak tradisional yang mengubah SQL menjadi format presentasi seperti HTML, PDF, dan ePub. XQuery dapat mengambil informasi dari database Anda dan memformatnya untuk presentasi.
Mempelajari cara memilih data dasar dari dokumen XML dapat dipelajari hanya dalam beberapa jam jika Anda sudah terbiasa dengan SQL dan bahasa pemrograman fungsional lainnya. Namun, mempelajari cara membuat fungsi XQuery kustom, cara mendesain modul XQuery, dan cara menjalankan pengujian unit pada XQuery membutuhkan waktu yang jauh lebih lama.
Baca Juga : Apa Itu XQuery Basis Data
Belajar dengan Contoh
Banyak orang menemukan bahwa mereka belajar bahasa baru paling baik dengan membaca contoh-contoh kecil kode. Salah satu lokasi yang ideal untuk ini adalah Contoh Awal Wikibook XQuery
Contoh-contoh ini semuanya dirancang dan diuji untuk bekerja dengan eXist. Beri tahu kami jika ada contoh spesifik yang ingin Anda lihat.
Belajar Pemrograman Fungsional
XQuery adalah bahasa pemrograman fungsional, sehingga banyak hal yang Anda lakukan dalam program prosedural tidak disarankan atau tidak mungkin. Di XQuery, semua variabel harus tidak dapat diubah, artinya variabel harus ditetapkan sekali tetapi tidak pernah diubah. Aspek XQuery ini memungkinkannya tanpa kewarganegaraan dan bebas efek samping.
Mempelajari pernyataan FLOWR
Iterasi di XQuery menggunakan pernyataan pemrograman paralel yang disebut pernyataan FLOWR. Setiap loop dari pernyataan FLOWR dilakukan di utas eksekusi yang terpisah. Akibatnya, Anda tidak dapat menggunakan output dari komputasi apa pun dalam loop FLOWR sebagai input ke loop berikutnya. Konsep ini bisa sulit dipelajari jika Anda belum pernah menggunakan sistem pemrograman paralel.
Belajar XPath
XQuery juga menyertakan penggunaan XPath untuk memilih berbagai node dari dokumen XML. Perhatikan bahwa dengan database XML asli, ekspresi XPath terpendek seringkali menjadi yang tercepat karena ekspresi pendek menggunakan indeks elemen. Anda mungkin ingin menggunakan alat seperti alat “pembuat” XPath dalam IDE seperti oXygen untuk mempelajari cara membuat ekspresi XPath.
Menggunakan eXide
eXist hadir dengan alat berbasis web untuk melakukan pengembangan XQuery yang disebut eXide. Meskipun alat ini tidak secanggih IDE lengkap seperti oXygen, alat ini ideal untuk kueri kecil jika IDE tidak dapat diakses.
Mempelajari cara memperbarui dokumen XML
eXist hadir dengan serangkaian operasi untuk memperbarui dokumen XML pada disk. Operasi Pembaruan XQuery eXist
Mempelajari cara men-debug XQuery
eXist memiliki beberapa dukungan untuk men-debug XQuery selangkah demi selangkah, tetapi antarmukanya belum matang. Banyak orang memilih untuk men-debug fungsi rekursif kompleks secara langsung dalam XML IDE seperti oXygen yang mendukung debugging langkah demi langkah menggunakan pustaka Saxon XQuery internal. IDE oXygen memungkinkan Anda untuk mengatur breakpoint dan melihat dokumen keluaran dibuat satu elemen pada satu waktu. Proses ini sangat disarankan jika Anda mempelajari topik seperti rekursi. eXist XQuery Debugger
Mempelajari rekursi di XQuery
XML adalah struktur data rekursif yang inheren: pohon berisi sub-pohon, sehingga banyak fungsi XQuery untuk mentransformasi dokumen paling baik dirancang menggunakan rekursi. Satu tempat yang baik untuk mulai mempelajari rekursi adalah fungsi filter simpul identitas di buku wiki XQuery.
Penggunaan IDE Anda secara efektif
Sebagian besar pengembang yang melakukan XQuery lebih dari beberapa jam sehari akhirnya menggunakan IDE XQuery komersial penuh, dengan oXygen yang terintegrasi dengan eXist terbaik. Menyiapkan oXygen agak rumit pertama kali karena Anda perlu memuat lima file jar ke “driver” untuk oXygen. Lihat Menggunakan oksigen. Namun setelah ini selesai dan mesin XQuery default diatur untuk menggunakan eXist, ada banyak fitur produktivitas tinggi yang diaktifkan. Inti dari ini adalah fitur pelengkapan otomatis XQuery. Saat Anda mengetik di dalam XQuery, semua fungsi eXist dan parameternya ditampilkan di IDE. Misalnya jika Anda mengetik “xmldb:” semua fungsi modul XMLDB akan secara otomatis muncul dalam daftar drop-down. Saat Anda melanjutkan mengetik atau memilih fungsi, parameter dan tipe juga ditampilkan. Ini menjadi penghemat waktu yang besar saat Anda menggunakan lebih banyak fungsi XQuery.c
![]()
![]()
![]()
![]()
![]()

Apa Itu XQuery Basis Data
Apa Itu XQuery Basis Data – XQuery database adalah XQuery tindakan atau XQuery pemilihan.
Apa Itu XQuery Basis Data

zorba-xquery – XQuery pemilihan adalah XQuery yang mengambil data dari database.
XQuery tindakan meminta operasi tambahan pada data, seperti penyisipan, pembaruan, penghapusan, atau bentuk manipulasi data lainnya.
Ini tidak berarti bahwa pengguna hanya mengetikkan permintaan acak.
Agar database dapat memahami permintaan, database harus menerima XQuery berdasarkan kode yang telah ditentukan sebelumnya. Kode itu adalah bahasa XQuery.
Apa itu XQuery dalam SQL?
Bahasa XQuery digunakan untuk membuat XQuery dalam database, dan Microsoft Structured Query Language ( SQL ) adalah standarnya. Catatan: SQL dan MySQL tidak sama, karena yang terakhir adalah ekstensi perangkat lunak yang menggunakan SQL. Ekstensi bahasa lain dari bahasa tersebut termasuk Oracle SQL dan NuoDB. Meskipun Microsoft SQL adalah bahasa yang paling populer, ada banyak jenis database dan bahasa lainnya. Ini termasuk database NoSQL dan database grafik , Cassandra Query Language (CQL), Data Mining Extensions (DMX), Neo4j Cypher dan XQuery.
Baca Juga : XQuery Sebagai Bahasa Integrasi Data
Bagaimana cara kerja XQuery?
XQuery dapat menyelesaikan beberapa tugas berbeda. Terutama, XQuery digunakan untuk menemukan data tertentu dengan memfilter kriteria eksplisit. XQuery juga membantu mengotomatiskan tugas pengelolaan data, meringkas data, dan terlibat dalam penghitungan. Contoh XQuery lainnya termasuk menambahkan, tab silang, menghapus, membuat tabel, parameter, total, dan pembaruan. Sementara itu, parameter XQuery menjalankan variasi XQuery tertentu, mendorong pengguna untuk memasukkan nilai bidang, lalu menggunakan nilai tersebut untuk membuat kriteria. XQuery total, di sisi lain, memungkinkan pengguna untuk mengelompokkan dan meringkas data.
Dalam database relasional , yang berisi catatan atau baris informasi, XQuery pernyataan SQL SELECT memungkinkan pengguna untuk memilih data dan mengembalikannya dari database ke aplikasi. XQuery yang dihasilkan disimpan dalam tabel hasil, yang disebut kumpulan hasil. Pengguna dapat memecah pernyataan SELECT ke dalam kategori lain seperti FROM, WHERE dan ORDER BY. XQuery SQL SELECT juga dapat mengelompokkan dan menggabungkan data untuk dianalisis atau diringkas.
Pada dasarnya, XQuery seperti memesan secangkir kopi di kafe. Anda berjalan ke barista dan mengajukan permintaan Anda dengan bertanya, “Boleh saya minta secangkir kopi?” Barista memahami permintaan Anda dan memberi Anda secangkir kopi. XQuery bekerja dengan cara yang sama. Sebuah query memberikan arti pada baris kode yang digunakan dalam setiap bahasa query. Dengan demikian, baik pengguna dan database bertukar informasi karena keduanya “berbicara” dalam bahasa yang sama. Permintaan menurut bahasa bukanlah satu satunya cara untuk meminta informasi dari database. Contoh populer lainnya termasuk pengguna yang melakukan XQuery dengan contoh atau dengan menggunakan parameter yang tersedia.
Apa itu pelipatan XQuery?
Untuk sumber data seperti database relasional dan non relasional seperti Active Directory , OData atau Exchange , mesin mashup “menerjemahkan” dari M Language bahasa transformasi data Power Query (alat mashup dan transformasi data) ke bahasa yang dipahami oleh sumber data yang mendasarinya. Paling sering, bahasa itu adalah SQL. Saat penghitungan dan transformasi kompleks didorong langsung ke sumbernya, Power Query menggunakan mesin database relasional yang kuat yang dikembangkan untuk menangani volume data yang besar secara efisien.
Pelipatan XQuery menjelaskan kemampuan Power Query untuk menghasilkan satu pernyataan XQuery untuk mengambil dan mengubah data sumber. Mesin mashup Power Query mencoba menyelesaikan pelipatan XQuery untuk meningkatkan efisiensi bila memungkinkan. Pengguna juga dapat melakukan ratusan transformasi data yang berbeda menggunakan Power BI , platform intelijen bisnis Microsoft, yang dibangun di Power Query untuk terlibat dalam pelipatan XQuery. Power BI mencakup alat yang mengumpulkan, menganalisis, memvisualisasikan, dan berbagi data.
Permintaan pencarian web
XQuery penelusuran web menjelaskan apa yang dicari pengguna saat mereka mengetik pertanyaan atau kata di mesin telusur seperti Bing, Google, atau Yahoo . XQuery mesin telusur memberikan informasi yang jauh berbeda dari XQuery SQL, karena tidak memerlukan parameter posisi atau kata kunci. Permintaan mesin pencari pada dasarnya adalah permintaan informasi tentang topik tertentu.
Mesin pencari menggunakan algoritme untuk mencari dan menemukan hasil permintaan yang paling akurat. Mereka mengurutkan ini berdasarkan signifikansi dan menurut mesin pencari tertentu rinciannya tidak diungkapkan secara publik.
Jenis permintaan pencarian termasuk navigasi, informasional dan transaksional. Pencarian navigasi dimaksudkan untuk menemukan situs web tertentu, seperti ESPN.com pencarian informasi dirancang untuk mencakup topik yang luas, seperti perbandingan antara perangkat iPhone dan Android baru dan pencarian transaksional berusaha menyelesaikan transaksi, seperti pembelian sweter baru.
Jenis pertanyaan lainnya
Beberapa pertanyaan tidak ada hubungannya dengan hal di atas di antaranya adalah querySelector dalam JavaScript dan kesalahan XQuery di Facebook. QuerySelector JavaScript membantu pengguna menemukan elemen pertama yang cocok dengan pemilih CSS tertentu. Untuk mengembalikan semua elemen yang cocok, pengembang juga menggunakan metode querySelectorAll. Setiap kali pemilih tidak valid, proses memunculkan pengecualian SyntaxError. Jika tidak ada kecocokan, querySelector mengembalikan null. Kesalahan XQuery terjadi di Facebook karena sejumlah alasan. Setiap kali ini terjadi, pengguna mendapatkan pesan seperti ” Kesalahan saat melakukan XQuery .” Ini biasanya diperbaiki dengan me reboot perangkat, menyegarkan halaman, keluar dan masuk kembali atau dengan membersihkan cache dan cookie.
![]()
![]()
![]()
![]()
![]()

XQuery Sebagai Bahasa Integrasi Data
XQuery Sebagai Bahasa Integrasi Data – Kesesuaian bahasa XQuery untuk integrasi data dieksplorasi.
XQuery Sebagai Bahasa Integrasi Data

zorba-xquery – Titik awalnya adalah penilaian kemampuan integrasi dalam lingkungan khusus XML.
Langkah selanjutnya adalah evaluasi sejauh mana seseorang dapat memperluas kemampuan ini ke lingkungan yang heterogen dengan berbagai jenis media dan berbagai protokol akses data.
Ini mengarah pada identifikasi tantangan utama, yang merupakan representasi terstruktur dari format data nonXML menurut item model data XQuery.
Dukungan saat ini untuk representasi tersebut ditinjau, dan basis konseptual diusulkan untuk memodelkan hubungan antara item model data dan contoh format nonXML.
Baca Juga : Kasus Untuk Progam XQuery
Berbicara tentang integrasi data, kami mengandaikan skenario di mana informasi didistribusikan melalui beberapa sumber daya. Ini mungkin memiliki jenis media yang sama misalnya XML, JSON atau CSV atau jenis media yang berbeda.
Mengenai protokol akses, mereka mungkin disediakan oleh platform yang sama misalnya sistem file, sistem database tertentu, atau HTTP GET atau oleh beberapa platform. Setiap bahasa tujuan umum (Java, C#, Python, Perl) memiliki berbagai API untuk mengakses sumber daya yang diekspos pada platform yang berbeda dan menggunakan jenis media yang berbeda.
Oleh karena itu bahasa tujuan umum apa pun dapat digunakan untuk menyelesaikan tugas integrasi data. Jadi mengapa seseorang harus menetapkan ke bahasa tertentu kualitas menjadi “bahasa integrasi data”?
Aspek kuncinya adalah kesederhanaan. Bahasa yang sangat cocok untuk integrasi data memungkinkan solusi yang sangat sederhana untuk operasi tipikal integrasi data. Singkatnya, ini memungkinkan kesederhanaan ketika berhadapan dengan multiplisitas dan heterogenitas. Kami akan menyelidiki sejauh mana XQuery cocok dengan persyaratan ini. Pertanyaannya relevan dengan peran potensial yang mungkin dimainkan XQuery dalam lanskap TI umum. Jawabannya dapat mengubah pandangan dasar bahasa XQuery tujuan utamanya, ruang lingkupnya, dan arah perjalanan selanjutnya. Jika potensi integrasi data besar, dukungan yang diperluas untuk integrasi data harus menjadi tujuan utama saat menentukan versi XQuery mendatang sebagai standar, serta versi baru prosesor XQuery sebagai produk.
XQuery, dilihat dari luar
Banyak orang tertarik pada integrasi data, tetapi dalam konteks ini kami tidak mengetahui adanya perhatian khusus yang diberikan pada XQuery. Perasaan umum tampaknya bahwa XQuery adalah bahasa khusus untuk mengekstraksi konten dari dokumen XML. Ketertarikan pada fungsionalitas seperti itu sangat berkurang oleh fakta bahwa di banyak lingkungan, dokumen XML tidak ditangani secara langsung, karena disembunyikan oleh alat dan teknologi. Misalnya, banyak layanan web (REST dan SOAP) menggunakan dan menghasilkan XML, tetapi pengembang aplikasi klien dan server biasanya menangani objek (misalnya objek JAXB), daripada dokumen pesan itu sendiri. Akibatnya, XQuery memiliki status bahasa khusus yang menawarkan dukungan untuk tugas yang tidak biasa.
Fakta dasar tentang XQuery
Integrasi data berkaitan dengan pemilihan informasi dari berbagai sumber daya dan heterogen, menggabungkan dan mengubahnya menjadi informasi baru, yang dikirim ke komponen perangkat lunak penerima atau disimpan dalam sumber daya multipel dan heterogen. Persyaratan ini harus digunakan sebagai latar belakang saat mempertimbangkan beberapa fakta dasar tentang XQuery.
XQuery sebagai bahasa berorientasi informasi
XQuery adalah bahasa yang berfokus pada ekspresi informasi dalam dua cara sebagai pilihan informasi yang ada, dan sebagai konstruksi informasi baru. Pemilihan dan konstruksi informasi adalah operasi kunci dari integrasi data
XQuery sebagai bahasa yang ramah agregasi
Model data dibangun di atas abstraksi kunci dari urutan item, bukan pada satu item. Akibatnya, banyak operasi dapat diterapkan pada urutan item, bukan hanya pada item individual; khususnya, ekspresi jalur dapat diterapkan ke sejumlah dokumen input “secara bersamaan”. Pemrosesan kumpulan sumber daya yang digabungkan adalah operasi kunci dari integrasi data
Memperluas cakupan akses sumber daya
XQuery 1.0 membatasi akses sumber daya ke sumber daya XML yang diidentifikasi melalui satu URI (dalam praktiknya file, entri database XML, dan dokumen yang dapat diambil melalui HTTP GET dan ftp)
XQuery 3.0 memungkinkan pembacaan sumber teks
XQuery 3.1 memungkinkan penguraian teks JSON menjadi representasi terstruktur
Fungsi ekstensi khusus vendor memperluas cakupan akses sumber daya lebih lanjut (mengurai CSV, membaca konten arsip, akses ke database SQL dan NoSQL, dukungan untuk pesan HTTP POST)
Akses ke berbagai platform data dan jenis media merupakan prasyarat integrasi data
Integrasi data XML
Bagian saat ini berfokus pada skenario di mana semua sumber daya yang relevan adalah dokumen XML. Pengaturan ini menyembunyikan tantangan khusus pemrosesan data nonXML dengan bahasa XMLsentris, serta tantangan umum dalam menangani format data yang heterogen. Tujuan kami adalah untuk menyoroti kemampuan XQuery untuk menangani informasi terstruktur yang didistribusikan melalui beberapa sumber daya. Kemungkinan untuk menjaga kemampuan ini dalam konteks yang lebih umum ketika berurusan dengan data nonXML dan berbagai format akan dieksplorasi setelahnya( bagian yang disebut “Akses sumber daya” dan bagian yang disebut “pengikatan XDM” ). Terlepas dari jenis media yang terlibat, beberapa operasi cenderung penting dalam konteks integrasi data
Eksplorasi sumber daya mengumpulkan informasi tentang sumber daya yang tidak diketahui atau sedikit diketahui
Validasi sumber daya menilai kesesuaian sumber daya dengan harapan
Mencari informasi
Sebelum data dapat diintegrasikan, mereka harus ditemukan dan ditangani secara selektif.
Navigasi massal
Meskipun navigasi sering diterapkan pada dokumen tunggal, navigasi tidak dibatasi untuk penggunaan lokal seperti itu. Langkahlangkah dari suatu jalur tidak harus merupakan langkah sumbu (seperti pada contoh sebelumnya), tetapi dapat berupa ekspresi arbitrer, asalkan hanya menghasilkan node (dalam kasus langkah nonterminal) atau hanya node atau hanya nilai atom (dalam kasus langkah terminal). Secara khusus, sebuah langkah dapat menghasilkan node yang berisi beberapa dokumen. Misalnya, ungkapan
Validasi sumber daya
Integrasi data sering melibatkan validasi sumber daya terhadap harapan. Laporan validasi mungkin menjadi tujuan utama dalam dirinya sendiri, dan pengecualian sumber daya yang tidak valid dari pemrosesan lebih lanjut mungkin diperlukan untuk memastikan integritas data, ketahanan operasional, dan efisiensi.
Validasi skema
Pustaka fungsi standar XQuery belum berisi fungsi apa pun untuk memvalidasi dokumen XML terhadap skema XSD. Sebagai fitur opsional, bahasa XQuery tidak menyertakan validateekspresi, yang mengembalikan salinan dokumen yang divalidasi dengan anotasi tipe yang ditambahkan, atau memunculkan kesalahan jika terjadi kesalahan validasi. Dua poin harus diperhatikan. Pertama, tujuan untuk mengumpulkan informasi tentang validitas berbeda dari tujuan untuk membuat dokumen beranotasi tipe, dan tujuan pertama yang umum, bukan tujuan yang terakhir. Kedua, implementasi darivalidate ekspresi tidak umum di antara prosesor XQuery populer, terutama di antara produk open source. Kami berpikir bahwa fungsi XQuery yang menawarkan validasi XSD diinginkan secara umum, dan sangat diinginkan dalam konteks integrasi data. Untuk saat ini, beberapa prosesor XQuery menawarkan fungsi ekstensi khusus vendor untuk validasi XSD dokumen XML.
Validasi skema massal
Tanda tangan khas dari fungsi ekstensi untuk validasi XSD memiliki dua parameter, satu menyediakan dokumen instans dan satu lagi memasok dokumen skema. Menariknya, tanda tangan semacam itu cukup untuk mengaktifkan validasi massal validasi banyak dokumen instans terhadap kumpulan skema kandidat, menerapkan dokumen skema yang sesuai ke setiap dokumen instans dan mengintegrasikan hasilnya ke dalam satu laporan. Kemudahan mencapai ini mengikuti dari kemampuan navigasi dan keramahanagregasi XQuery :
untuk dokumen contoh tertentu pilih skema yang sesuai dengan mencocokkan namespace dan nama lokal elemen root dokumen dengan namespace target skema dan nama deklarasi elemen tingkat atas
kumpulkan hasil validasi dokumen tunggal dalam ekspresi FLWOR sederhana
mengintegrasikan hasil validasi dokumen tunggal menggunakan ekspresi yang disematkan
![]()
![]()
![]()
![]()
![]()
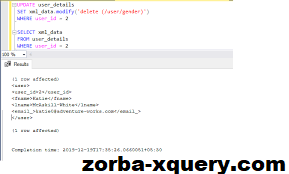
Kasus Untuk Progam XQuery
Kasus Untuk Progam XQuery – Penggunaan XML tersebar luas di seluruh sistem informasi modern di semua sektor industri, pemerintah, dan akademik.
Kasus Untuk Progam XQuery

zorba-xquery – Teknologi inti untuk memproses XML (XML, XSLT , XPath, XML Schema , dan lainnya) semakin matang berkat dukungan dari badan standar seperti W3C dan OASIS , dan dari pemain industri besar seperti IBM, Microsoft, dan Oracle.
XML juga merupakan dasar bagi badan standar industri yang berkembang untuk pertukaran data, dan sedang dalam perjalanan untuk menjadi teknologi arus utama untuk integrasi data. XML tidak hanya mengubah data; itu mengubah pemrosesan informasi secara umum.
Baca Juga : Memahami XQuery Beserta Potensinya
Namun, XML seperti yang kita kenal sekarang bukanlah jawaban keseluruhan. Ini hanyalah cara untuk merepresentasikan data dalam format yang menggambarkan diri sendiri yang mudah diinterpretasikan di berbagai sistem. Tuntutan tantangan integrasi data tingkat lanjut saat ini memerlukan standar XML yang fleksibel untuk agregasi dan transformasi data, yang dapat bekerja dengan mulus dengan sumber data relasional dan warisan , serta teknologi layanan Web baru.
XQuery Membuka Kekuatan XML
Salah satu perkembangan terbaru dalam XML adalah munculnya query XML asli dan bahasa transformasi XML Query, atau XQuery. XQuery sedang dikembangkan oleh W3C dan mendekati status Rekomendasi Kandidat. Bahkan sekarang, XQuery siap menjadi bahasa kueri standar yang digunakan perusahaan untuk mengakses dan memanipulasi penyimpanan data dan konten yang berbeda. Dengan XQuery, logika kueri dan transformasi beroperasi pada tampilan data XML; itu tidak tergantung pada struktur fisik data.
Jika pendekatan kueri dan manipulasi data ini terdengar familier, itu adalah: dalam SQL , kueri menjelaskan secara deklaratif pemetaan antara satu set tabel input, dan tabel output, atau hasil. Penyedia data yang mendasarinya (driver JDBC, klien database, dan sebagainya) mengambil SQL dan mengeksekusinya terhadap database relasional. Untuk berbagai tingkat, aplikasi dengan demikian terlindung dari platform database yang mendasarinya. Kesamaan XQuery dengan paradigma SQL hanya dapat membantu mempercepat penerapannya.
Satu perbedaan penting adalah bahwa dalam SQL, semuanya harus terlihat seperti tabel relasional, tidak peduli bagaimana tabel itu disimpan secara fisik. Di XQuery, Anda dapat memiliki sistem penyimpanan yang sama sekali berbeda dan struktur data yang sangat berbeda, dan, selama data yang mendasarinya dapat diekspos sebagai XML, semuanya masih berfungsi.
XQuery Menyederhanakan Integrasi Data
XQuery dirancang untuk mendukung beberapa sumber informasi XML sebagai input. Fungsi utama program XQuery adalah untuk memilih, memfilter, mengubah, menggabungkan, dan menggabungkan data di berbagai sumber data. Triknya adalah bahwa sumber data ini harus direpresentasikan ke program XQuery sebagai XML. Untungnya, ada juga beberapa produk di pasar, termasuk Stylus Studio, yang menyediakan alat visual untuk membangun adaptor yang mengubah sumber data non-XML (file datar, EDI , database relasional, dan lainnya) ke dalam XML.
Hasil akhirnya adalah bahwa pengembang yang menggunakan teknologi saat ini dapat membangun program XQuery untuk menggabungkan atau menggabungkan data dari berbagai sumber data, dan menghasilkan XML sebagai output. Program XQuery tersebut kemudian dapat digunakan sebagai layanan Web yang dapat diimpor ke program XQuery lain, program yang membuat tampilan komposit dengan menggabungkan sumber data ini dengan sumber data lain dalam skema integrasinya. Ini hanyalah salah satu contoh nilai kode XQuery berbasis standar yang dapat digunakan kembali.
Kemampuan integrasi data bawaan XQuery menjadikannya alat yang ampuh untuk pengembang aplikasi modern. Ambil aplikasi Service-Oriented Architecture (SOA) , misalnya. Integrasi data di dunia SOA yang muncul berarti berurusan dengan data dari berbagai sumber (database relasional, file XML, aplikasi warisan, dan layanan Web, untuk beberapa nama). XML adalah bahasa yang sempurna untuk mengekspresikan semua data ini secara seragam, dan XQuery adalah cara termudah dan paling ampuh untuk memprosesnya.
Untuk menghargai masalah yang diselesaikan XML dan XQuery, pertimbangkan berapa banyak waktu yang dihabiskan pengembang saat ini untuk menangani persyaratan dinamis untuk arus informasi antar dan intra-perusahaan yang harus terintegrasi, terkini, dan benar. Contoh utama dari hal ini dapat dilihat dalam aplikasi manajemen rantai pasokan dan banyak aplikasi lain yang mengintegrasikan data dari berbagai sumber untuk menyajikan informasi pelanggan dan produk terpadu.
Membangun logika integrasi data ini bisa menjadi proses yang mahal, kompleks, dan memakan waktu – beberapa analis percaya bahwa hingga 70% dari upaya pada proyek integrasi sistem tipikal dikhususkan untuk logika integrasi tingkat data ‘pengkodean tangan’. Terlebih lagi, kode ini sangat sensitif terhadap segala jenis perubahan di lingkungan atau bahkan dalam penggunaan aplikasi yang dimaksud. Hasil akhirnya adalah pengembang sering berakhir dengan menulis kode yang dibuang begitu saja. Dan habiskan 70% waktu mereka untuk melakukannya.
XML memecahkan beberapa masalah ini dengan menyediakan lingua franca untuk integrasi data. Untuk tujuan ini, Skema XML ada untuk hampir setiap sektor industri yang dapat dibayangkan untuk memfasilitasi pertukaran data dalam organisasi, serta antara pelanggan , mitra , distributor, dan pemasok.
Bahkan dengan XML, banyak pengembang menggunakan pendekatan pemrograman kode tangan yang menggabungkan Java , DOM, XPath , XSLT dan metode lainnya, semuanya dalam upaya untuk menanyakan dan memanipulasi data XML. Pendekatan tingkat rendah seperti DOM sulit untuk ditulis dan dipelihara karena ekspresi kueri, agregasi, dan logika transformasi yang akan dievaluasi (apa) terikat erat dengan strategi pemrosesan kueri yang mendasarinya (bagaimana) sehingga bahkan perubahan kecil dalam aplikasi persyaratan dapat memerlukan upaya pengkodean ulang yang substansial.
XQuery sangat menyederhanakan kueri dan transformasi XML berdasarkan sintaksnya yang sederhana dan ringkas. Selain itu, pengembang yang menggunakan XQuery bekerja dengan semua data sebagai abstraksi XML dan dapat mengharapkan implementasi XQuery yang mendasarinya untuk menangani pengaksesan sumber data fisik dengan tepat.
XQuery Akan Menyederhanakan Layanan Data SOA
Proposisi nilai kunci SOA adalah ide untuk menciptakan aplikasi komposit yang digabungkan secara longgar untuk menjembatani sistem informasi yang ada dan aplikasi baru. Kepatuhan terhadap prinsip-prinsip SOA juga sering kali membutuhkan kemampuan untuk menggabungkan dan mengubah sumber data lama, relasional, dan XML untuk mengekspos tampilan data gabungan yang baru – biasanya sebagai XML – yang dapat digunakan oleh aplikasi tingkat yang lebih tinggi. Untuk tujuan ini, XQuery mungkin muncul sebagai metode pilihan untuk membangun layanan data SOA tingkat data.
Pengembang yang membangun layanan data ini akan menemukan bahwa XQuery sangat menyederhanakan agregasi data dan logika transformasi. Tugas ini juga akan membutuhkan kemampuan untuk mengabstraksi sumber data relasional dan XML untuk memudahkan tantangan integrasi. Untungnya, XQuery menyediakan landasan bagi vendor untuk menghadirkan alat dan komponen yang melakukan hal ini.
Solusi Vendor untuk Masa Depan XQuery World Muncul
Misalnya, produk yang dapat menyediakan akses data terpadu di seluruh XML dan data relasional, seperti Data Direct XQuery™ dari DataDirect Technologies, akan sangat diminati oleh pengembang yang ditugaskan untuk merakit layanan data berbasis XQuery. Spesifikasi terkait – XQuery API untuk Java, XQJ – akan menyediakan antarmuka standar untuk dengan mudah menyematkan program XQuery ini dalam program Java apa pun, seperti yang dilakukan JDBC untuk SQL.
Tentu saja, kinerja akan menjadi faktor kunci lain dalam adopsi XQuery. Kinerja logika integrasi data dapat tidak dapat diterima dalam banyak kasus karena lalu lintas jaringan yang berlebihan dan konsumsi memori lokal yang diperlukan untuk memproses kueri di sumber data yang berbeda. Ada banyak produk di pasaran saat ini yang menangani masalah ini dengan menawarkan solusi berbasis server yang memisahkan logika integrasi data dari aplikasi. Banyak dari platform ini yang sadar akan XML dan memiliki rencana untuk mendukung XQuery.
Misalnya, Microsoft , IBM, dan Oracle semuanya telah mengintai posisi di dunia XML yang dengan mengubah database masing-masing di APIlevel, platform mereka dapat dengan mudah berfungsi sebagai server file besar dan cepat untuk semua tipe data. Di dunia ini, XQuery adalah API alami untuk mengakses tipe data berbeda yang disimpan di server tersebut, serta untuk mengakses sumber data eksternal seperti sistem file dan repositori WebDAV.
Implementasi XQuery dari vendor integrasi seperti BEA, Ipedo, Actuate, dan OpenLink juga ada di pasaran saat ini. Kabar baiknya adalah banyak vendor secara aktif mengembangkan produk yang bermanfaat dan membantu mempromosikan penggunaan XQuery. Berita buruknya adalah bahwa beberapa vendor ini menggunakan ekstensi XQuery berpemilik dan implementasi yang sangat bertujuan untuk memberikan produk yang berfungsi, dengan hasil yang tidak menguntungkan bahwa layanan XQuery yang ditawarkan oleh vendor ini terikat dalam konteks solusi berbasis platform mereka.
Solusi lain yang datang ke pasar, seperti DataDirect XQuery™, akan menawarkan teknologi akses data yang sesuai dengan XQuery dan XQJ sebagai komponen kinerja tinggi yang dapat disematkan. Menariknya, implementasi XQuery dari DataDirect Technologies akan mengekspos sebagai XML data relasional yang disimpan di salah satu platform database utama. Dengan kata lain, menggunakan data relasional dalam XQuery tidak akan bergantung pada dukungan vendor database terhadap XML. Dan, DataDirect XQuery™ akan memberikan manfaat kinerja yang sulit ditandingi dengan mendorong banyak kueri terdistribusi dan menggabungkan operasi ke platform basis data relasional yang terlibat dalam kueri. Pendekatan cepat dan ringan untuk integrasi data ini akan sangat cocok untuk mengembangkan layanan SOA tingkat data yang kaya.
Kesimpulan
XQuery menjanjikan produktivitas yang belum pernah terjadi sebelumnya untuk pengembang yang memecahkan masalah integrasi data. Memenuhi janji itu oleh W3C dan pemangku kepentingan industri akan menjadi kunci keberhasilan XQuery. Seperti yang dibahas artikel ini, ada banyak argumen untuk keberhasilan XQuery sebagai bahasa pemrograman yang diadopsi secara luas: kemudahan penggunaan, kesamaan dengan SQL, permintaan untuk integrasi data, peningkatan produktivitas pengembang, komunitas vendor aktif, interoperabilitas dengan data lama, dan meluasnya penggunaan XML hanyalah beberapa di antaranya.
![]()
![]()
![]()
![]()
![]()
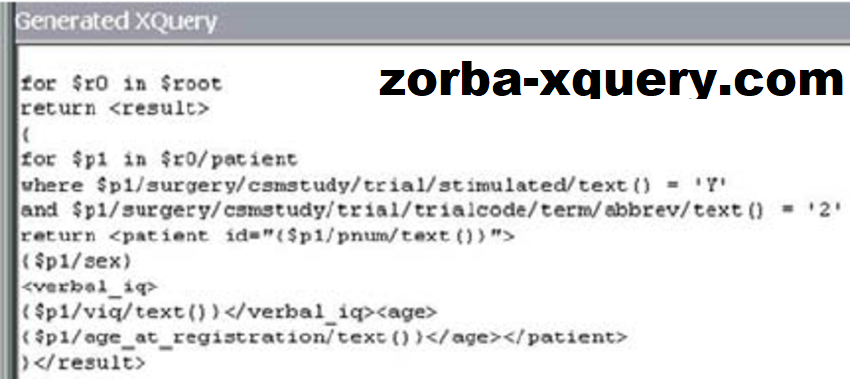
Memahami XQuery Beserta Potensinya
Memahami XQuery Beserta Potensinya – Meskipun sebagian besar pakar setuju bahwa XML akan menjadi standar untuk penyimpanan dan pengambilan data dalam dekade berikutnya, mereka tidak dapat menyetujui bagaimana penerapannya.
Memahami XQuery Beserta Potensinya

zorba-xquery – Banyak yang percaya bahwa sistem database saat ini (seperti Oracle , SQL Server , dan Sybase ) akan memigrasikan mesin mereka untuk menyimpan XML asli, dan bahwa produsen akan membangun kemampuan pengoptimalan, pemrosesan, dan manipulasi ke mesin baru ini.
Yang lain percaya bahwa pembuat basis data akan membiarkan mesin tetap utuh dan hanya menambahkan lapisan XML memungkinkan mesin untuk menggunakan dan memancarkan data yang mendasarinya berdasarkan kueri dari bahasa XML yang ada seperti eXtensible Stylesheet Language Transformations (XSLT).
Baca Juga :Mengajarkan XQuery Pads Humanis Digital
Kedua teori tersebut didasarkan pada asumsi bahwa kita memerlukan bahasa kueri dari basis data yang mendasarinya untuk melakukan kueri yang canggih terhadap file XML. Dalam artikel ini, saya akan menjelaskan mengapa ini adalah asumsi yang salah dan bagaimana spesifikasi draf kelompok kerja XML untuk Bahasa Kueri XML (disebut XQuery) tidak hanya akan berfungsi sebagai bahasa kueri XML, tetapi akan dengan mudah bekerja melawan sumber relasional juga .
Memahami bahasa
Dengan lebih banyak data yang diedarkan sebagai XML, dan lebih banyak sistem yang dirancang untuk memproduksinya, pengembang memerlukan cara untuk menanyakan sumber XML untuk potongan data tertentu dari sumber data. Pendekatan standar pertama untuk mengakses sumber data XML ini disebut XML Path Language (XPath). XPath dirancang untuk memungkinkan navigasi dalam file XML dan kueri sederhana dari satu file.
Karena XPath dirancang untuk menavigasi dan menanyakan satu sumber data XML, menggunakan XPath secara efektif untuk menanyakan beberapa sumber data mengharuskan pengembang untuk melakukan penggabungan dokumen XML yang kompleks menggunakan XSLT atau program khusus. Pendekatan XPath mirip dengan bagaimana beberapa perusahaan membuat gudang data saat ini—data dari berbagai sumber dikumpulkan dan diubah menjadi format yang identik di gudang gudang pusat. Manajer kemudian dapat menggunakan alat repositori itu untuk menanyakan data.
XQuery dirancang untuk memecahkan masalah ini dengan mengizinkan kueri kompleks di tidak hanya beberapa dokumen XML, tetapi juga antara dokumen XML, database relasional, repositori objek, dan dokumen tidak terstruktur lainnya. Ke depan, XPath akan fokus pada kemampuan navigasi (yaitu, menghubungkan antara dokumen atau mengakses bagian tertentu dari dokumen), dan kelompok kerja eXtensible Stylesheet Language (XSL) akan mempelajari cara untuk memasukkan kueri berbasis XQuery dalam standar XSL. Ini akan membuat alat yang ampuh untuk mencari, menggabungkan, dan menyajikan data dari sumber yang berbeda menggunakan bahasa kueri terpadu (XQuery) dan bahasa pemformatan tampilan dan transformasi yang kuat (XSL).
XQuery adalah bahasa query yang sangat kaya. Ini memahami data dan tipe data, memungkinkan kueri nilai kompleks seperti kueri “kurang dari” atau rentang. Ini memiliki primitif yang memungkinkan iterasi melalui sumber data, serta fungsi pengurutan, agregasi, dan pengelompokan. Ini memungkinkan konektivitas antara sumber dan restrukturisasi dokumen berdasarkan kriteria yang ditentukan. Lebih penting lagi, ini mencakup mekanisme standar untuk memperluas bahasa dengan fungsi khusus. Sama seperti database relasional memiliki bahasa kueri dan prosedur tersimpannya sendiri, XQuery menyediakan fungsionalitas yang serupa, kecuali bahwa ia akan bekerja di kedua sumber data XML dan sumber data relasional.
Mengingat kemampuannya untuk melakukan kueri di beberapa dokumen dan format data, XQuery akan memainkan peran kunci dalam skenario berikut:
Mitra bisnis mengirim katalog dalam format XML, dan Anda ingin membuat kueri katalog untuk membandingkan harga produk umum.
Ketika intranet memiliki data yang disimpan dalam database relasional dan juga mengekstrak dari sistem file lain yang berisi data dalam file XML. Tujuannya di sini adalah membangun layanan portal yang mengkategorikan dan menampilkan informasi dari sumber yang berbeda ini.
Anda memiliki informasi produk dalam dokumen Word, harga produk dalam database relasional, dan riwayat insiden produk yang diarsipkan dalam file XML pada sistem internal. Dengan menggunakan XQuery dan XSL, Anda dapat membuat ekstranet pelanggan yang menyajikan tampilan terpadu dari ketiga repositori ini tanpa harus memindahkan data yang mendasarinya. Sistem yang ada berjalan tanpa modifikasi, tetapi Anda memiliki pandangan baru yang kuat tentang data untuk pelanggan Anda.
Apakah terlalu dini untuk menggunakan XQuery?
Penting untuk dipahami bahwa tidak seperti XML, XML Schema Definition (XSD), dan XSLT, XQuery adalah draf dan bukan rekomendasi. Dengan demikian, komunitas vendor baru saja mulai membuat alat untuk memudahkan pembuatan program XQuery. Saat ini, tidak ada alat grafis yang membuat sintaks XQuery yang mendasarinya secara otomatis, jadi satu-satunya jalan adalah membuat dan men-debug kueri menggunakan alat pengeditan teks sederhana seperti Notepad. Ini memunculkan masalah yang lebih luas tentang kapan harus mengadopsi teknologi baru berdasarkan standar W3C (yaitu, apakah Anda harus menunggu rekomendasi, atau mulai menggunakan teknologi pada tahap konsep).
Saat membuat keputusan ini, Anda harus menggunakan kriteria yang sama seperti yang Anda gunakan untuk kode beta. Misalnya, apakah keuntungan bisnis yang akan Anda peroleh lebih besar daripada biaya pengkodean bagian aplikasi lagi ketika rekomendasi menjadi final? Beberapa risiko ini dapat dikurangi jika Anda menggunakan alat vendor, karena vendor dapat terus mendukung versi draf spesifikasi untuk merilis alat mereka sebelum rekomendasi resmi. Penggunaan XML Data Reduced (XDR) oleh Microsoft adalah contoh yang bagus.
Saat W3C mencoba menyelesaikan rekomendasi XSD, ada banyak draft yang bersaing, salah satunya adalah XDR. Ini adalah bagian dari XSD, tetapi ternyata tidak sesuai dengan spesifikasi akhir. BizTalk Microsoft mengandalkan XDR, dan alatnya menghasilkan skema XDR. Daripada menunggu spesifikasi XSD final, Microsoft merilis versi BizTalk yang bergantung pada XDR. Tetapi karena pelanggan menggunakan alat BizTalk untuk membuat aplikasi, Microsoft akan dapat menggantikan XDR dengan implementasi XSD yang sepenuhnya sesuai di masa mendatang—termasuk alat porting untuk meningkatkan aplikasi yang ada. Saya berharap banyak aplikasi akan porting dengan mudah, tetapi beberapa akan memerlukan retooling untuk lebih mendukung XSD.
Layak untuk dipertimbangkan
Jelas bahwa XQuery adalah bahasa yang sangat kuat untuk menganalisis sumber data XML dan non-XML. Meskipun masih dalam masa pertumbuhan, dan belum siap untuk penggunaan produksi secara luas, ia memiliki penyelidikan dan pertimbangan yang memadai sebagai alat potensial dalam gudang manipulasi data perusahaan Anda. Jika standar dan alat vendor berdasarkan standar dapat memenuhi janji XQuery, maka kami mungkin telah benar-benar menemukan Cawan Suci bahasa kueri. Meski begitu, kemungkinan bahasa kueri milik masing-masing vendor akan berteriak “Saya belum mati” selama bertahun-tahun yang akan datang.
![]()
![]()
![]()
![]()
![]()
Mengajarkan XQuery Pads Humanis Digital
Mengajarkan XQuery Pads Humanis Digital – XQuery menyediakan sarana yang sangat baik untuk mengajarkan pemrograman kepada humanis digital karena ia bekerja secara mulus dengan data XML yang ada, memiliki inti yang elegan dan sederhana dengan perpustakaan standar yang terstruktur dengan baik, dan dapat digunakan bersama dengan database XML untuk mengembangkan end to mengakhiri aplikasi web.
Mengajarkan XQuery Pads Humanis Digital

zorba-xquery – Namun, bahan ajar saat ini untuk XQuery tidak memenuhi kebutuhan para humanis digital, yang mengandaikan pengetahuan implisit tentang konsep pemrograman yang sering kurang. Berdasarkan pengalaman mengajar XQuery kepada humanis digital (termasuk profesional alt ac, arsiparis, anggota fakultas, mahasiswa pascasarjana, dan pustakawan) dalam tiga pengaturan berbeda.
Jadi artikel ini adalah tentang mengajarkan XQuery kepada humanis digital, yang menimbulkan pertanyaan, siapa humanis digital yang ada dalam pikiran Anda? Latihan mendefinisikan humaniora digital adalah salah satu yang paling populer dan, pada titik ini, latihan-latihan usang dalam humaniora digital. Anda yakin bahwa Anda bisa meminta beberapa definisi dari peserta Balisage. Beberapa dari Anda di sini membantu mewujudkan bidang “humaniora digital” dari konsep “komputasi humaniora” yang sekarang sebagian besar telah digantikan.
Baca Juga : Ekstensi File Menggunakan XQUERY
Sejauh ini, Anda menyukai definisi dalam “Proposal for a Digital Humanities Center at Princeton University” yang baru-baru ini diterbitkan. Humaniora Digital mengacu pada penggunaan dan penerapan alat dan metode komputasi untuk domain studi humanis, tetapi juga kebalikannya, penerapan pertanyaan humanistik pada ilmu komputer dari sejarah hingga papirologi, dari literatur komparatif hingga geografi sejarah, dan ke desain artefak komputasi yang dipengaruhi seni atau humaniora.
Definisinya luas secara instruktif. Di satu sisi, ini mencakup seluruh rangkaian alat yang digunakan kaum humanis dalam penelitian dan pengajaran mereka. Di sisi lain, ini menunjukkan bahwa humaniora digital melibatkan pengambilan perspektif kritis pada alat-alat ini. Dengan kata lain, humaniora digital tidak hanya tentang menggunakan PowerPoint untuk menampilkan informasi ke kelas tetapi juga memikirkan bagaimana PowerPoint sebagai media membentuk dan mempengaruhi transmisi informasi tersebut.
Mau tidak mau, Para ahli metodologi itu sendiri bekerja di berbagai bidang dan dengan sejumlah besar alat, termasuk penyuntingan teks digital, sistem informasi geografis (GIS), pemrosesan bahasa alami, analisis jaringan, web semantik dan analisis statistik, dan lain-lain. Beberapa. Jelas, tidak ada peneliti tunggal yang kompeten di semua bidang ini. Dengan demikian, humaniora digital telah digambarkan sebagai “tenda besar,” meskipun menurut Patrik Svensson mungkin lebih baik digambarkan sebagai “tempat pertemuan, pusat inovasi, dan zona perdagangan.”
Singkatnya, humaniora digital kurang disiplin daripada tempat pertemuan praktisi dari berbagai disiplin ilmu dengan tingkat keterampilan yang berbeda, mode produksi yang berbeda, dan tingkat wawasan kritis yang berbeda pada pekerjaan mereka. Poin praktisnya adalah bahwa seseorang tidak dapat mengasumsikan apa pun ketika mengajar “humanis digital”. Tidak ada prasyarat untuk menyebut diri sendiri sebagai “humanis digital” di luar, Anda kira, minat umum dalam komputasi dan humaniora. Praktisnya, para humanis digital berasal dari berbagai bagian akademi dan juga dari luar serambinya.
Dalam arti luas, administrator, anggota fakultas, mahasiswa pascasarjana, pustakawan, sarjana alt-ac, dan teknolog informasi semuanya dapat secara kredibel mengklaim sebagai humanis digital. Perspektif mereka tentang humaniora digital akan sangat berbeda sesuai dengan disiplin dan lokasi sosial-ekonomi. Profesor umumnya memasuki humaniora digital dengan agenda penelitian tertentu. Pustakawan, sebaliknya, umumnya tidak memiliki program penelitian mereka sendiri biasanya, mereka mencari cara baru untuk menyediakan dan meningkatkan akses ke koleksi yang mereka kelola.
Mahasiswa pascasarjana dapat mengeksplorasi pilihan atau bekerja sebagai asisten pada proyek fakultas sambil mempertimbangkan alternatif tindakan alternatif untuk karir jalur tenurial standar. Paling-paling, humaniora digital menyediakan “tempat pertemuan” bagi sesama pelancong ini. Seperti yang dikatakan Julia Flanders, umumnya tidak memiliki program penelitian sendiri biasanya, mereka mencari cara baru untuk menyediakan dan meningkatkan akses ke koleksi yang mereka kelola.
Mahasiswa pascasarjana dapat mengeksplorasi pilihan atau bekerja sebagai asisten pada proyek fakultas sambil mempertimbangkan alternatif tindakan alternatif untuk karir jalur tenurial standar. Paling-paling, humaniora digital menyediakan “tempat pertemuan” bagi sesama pelancong ini. Seperti yang dikatakan Julia Flanders, umumnya tidak memiliki program penelitian sendiri biasanya, mereka mencari cara baru untuk menyediakan dan meningkatkan akses ke koleksi yang mereka kelola.
Mahasiswa pascasarjana dapat mengeksplorasi pilihan atau bekerja sebagai asisten pada proyek fakultas sambil mempertimbangkan alternatif tindakan alternatif untuk karir jalur tenurial standar. Paling-paling, humaniora digital menyediakan “tempat pertemuan” bagi sesama pelancong ini. Seperti yang dikatakan Julia Flanders, Mahasiswa pascasarjana dapat mengeksplorasi pilihan atau bekerja sebagai asisten pada proyek fakultas sambil mempertimbangkan alternatif tindakan alternatif untuk karir jalur tenurial standar.
Paling-paling, humaniora digital menyediakan “tempat pertemuan” bagi sesama pelancong ini. Seperti yang dikatakan Julia Flanders, Mahasiswa pascasarjana dapat mengeksplorasi pilihan atau bekerja sebagai asisten pada proyek fakultas sambil mempertimbangkan alternatif tindakan alternatif untuk karir jalur tenurial standar. Paling-paling, humaniora digital menyediakan “tempat pertemuan” bagi sesama pelancong ini. Seperti yang dikatakan Julia Flanders,
Untuk alasan ini, Anda pikir salah satu efek paling menarik dari humaniora digital pada peran pekerjaan akademis adalah tekanan yang diberikannya pada apa yang kita anggap sebagai domain pekerjaan kita sendiri. Dalam kolaborasi humaniora digital tipikal, fakultas tradisional mengeksplorasi bentuk-bentuk pekerjaan yang biasanya terlihat “teknis” atau bahkan kasar (seperti pengkodean teks, pembuatan metadata, atau transkripsi); programmer berkontribusi pada keputusan editorial dan mahasiswa menulis bersama artikel dengan cendekiawan senior dalam semacam karnaval Bakhtinian dari penggunaan profesional yang terbalik.
Mengajar humanis digital, kemudian, terbukti menantang karena instruktur harus merancang kurikulum yang tidak membuat pengandaian yang kuat dari segala bentuk pengetahuan domain. Kurikulum terbaik memungkinkan kolaborasi yang muncul di antara praktisi, mendapat manfaat dari dan mungkin juga mengandalkan keberadaan kekuatan pelengkap di antara siswa. Namun instruktur harus berhati-hati untuk tidak mengandaikan setiap titik pandang sentral.
Tak perlu lagi, sebuah kurikulum akan terbukti terlalu longgar atau terlalu menuntut, terlalu teoretis atau terlalu teknis, terlalu condong ke satu jenis aplikasi atau lainnya. Dalam kasus seperti itu, mengajar tergantung pada niat baik para peserta, yang saling membantu dengan konsep belajar dari domain lain. Kurangnya praanggapan dalam “humaniora digital” membawa kita ke masalah utama, yaitu, apakah pengkodean diperlukan untuk humaniora digital.
Ada perdebatan dalam komunitas humaniora digital antara mereka yang berpikir bahwa semua humanis digital harus belajar coding dan mereka yang berpendapat bahwa belajar memprogram tidak perlu dan bahkan mungkin berbahaya bagi produktivitas ilmiah. [2]Slogan “Lebih banyak hack, kurang yack!” kadang-kadang dilontarkan, menunjukkan bahwa humaniora digital terutama tentang membangun sesuatu daripada membicarakannya. Namun, seperti yang diingatkan Bethany Nowviskie kepada kita, arti asli dari “ocehan” dalam frasa lucu itu tidak ditujukan untuk melawan analisis teoretis akademis, tetapi pada pekerjaan komite yang boros yang sering kali mencakup proyek-proyek digital di akademi Nowviskie 2014.
Institut XQuery berangkat untuk menyeberangi perbedaan yang diklaim antara pembangun dan penanya dalam humaniora digital dengan sesedikit mungkin gembar-gembor. Intuisi pemandu Anda adalah bahwa ada komplementaritas antara pengkodean dan penyandian–dengan belajar mengkueri markup Anda, Anda menjadi pembuat enkode yang lebih mahir. Jadi, mempelajari sedikit pemrograman akan terbukti bermanfaat bagi mereka yang mengerjakan proyek markup digital. Tentu saja, membangun komplementaritas ini lebih mudah dengan beberapa bahasa pemrograman daripada yang lain, yang membawa Anda ke XQuery.
Membuat Kasus untuk XQuery
Anda juga dapat menyatakan di muka bahwa Anda menganggap XQuery sebagai bahasa yang fantastis untuk humanis digital. Jika Anda terlibat dalam menandai dokumen dalam XML, maka belajar XQuery akan membayar dividen jangka panjang. Anda memiliki argumen untuk sedikit keberanian ini. Alasan Anda mengangkat XQuery sebagai bahasa pemrograman yang menarik bagi para humanis digital pada dasarnya adalah tiga
- XQuery sesuai dengan domain untuk humanis digital.
- XQuery memungkinkan pengembangan aplikasi full stack.
- XQuery kompak, singkat, dan relatif mudah dipelajari.
![]()
![]()
![]()
![]()
![]()
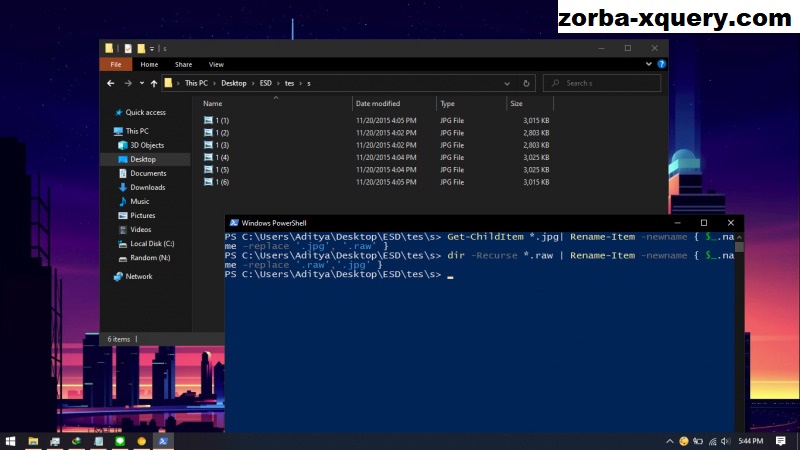
Ekstensi File Menggunakan XQUERY
Ekstensi File Menggunakan XQUERY – XQUERY adalah ekstensi file yang umumnya dikaitkan dengan file Format Kode Sumber XQuery. Spesifikasi Format Kode Sumber XQuery dibuat oleh Kelompok Kerja Query XML W3C.
Ekstensi File Menggunakan XQUERY

zorba-xquery – File XQUERY didukung oleh aplikasi perangkat lunak yang tersedia untuk perangkat yang menjalankan Mac OS, Windows. Format file XQUERY, bersama dengan 1204 format file lainnya, termasuk dalam kategori File Pengembang . Program paling populer untuk menangani file XQUERY adalah XMLSpy , tetapi pengguna dapat memilih di antara 3 program berbeda yang mendukung format file ini.
Program yang mendukung ekstensi file XQUERY
Daftar berikut berisi program yang dikelompokkan menurut sistem operasi yang mendukung file XQUERY. File dengan akhiran XQUERY dapat disalin ke perangkat seluler atau platform sistem apa pun, tetapi mungkin tidak dapat dibuka dengan benar di sistem target.
Bagaimana cara membuka file dengan ekstensi XQUERY?
Ada beberapa penyebab mengapa Anda memiliki masalah dengan membuka file XQUERY pada sistem yang diberikan. Sisi baiknya, masalah yang paling banyak ditemui terkait dengan file Format Kode Sumber XQuery tidak rumit.
Baca Juga : Tur Terpandu Untuk Tutorial XQuery
Dalam kebanyakan kasus mereka dapat ditangani dengan cepat dan efektif tanpa bantuan dari seorang spesialis. Berikut ini adalah daftar panduan yang akan membantu Anda mengidentifikasi dan memecahkan masalah terkait file.
Langkah 1. Dapatkan XMLSpy
Penyebab utama dan paling sering menghalangi pengguna membuka file XQUERY adalah bahwa tidak ada program yang dapat menangani file XQUERY yang diinstal pada sistem pengguna. Solusi yang paling jelas adalah mengunduh dan menginstal XMLSpy atau satu ke program yang terdaftar TextMate , Microsoft XML Notepad , Stylus Studio . Di bagian atas halaman daftar yang berisi semua program yang dikelompokkan berdasarkan sistem operasi yang didukung dapat ditemukan. Metode teraman untuk mengunduh XMLSpy yang diinstal adalah dengan membuka situs web pengembang dan mengunduh perangkat lunak menggunakan tautan yang disediakan.
Langkah 2. Perbarui XMLSpy ke versi terbaru
Jika masalah dengan membuka file XQUERY masih terjadi bahkan setelah menginstal XMLSpy , ada kemungkinan Anda memiliki versi perangkat lunak yang kedaluwarsa. Periksa situs web pengembang apakah tersedia versi XMLSpy yang lebih baru. Pengembang perangkat lunak dapat menerapkan dukungan untuk format file yang lebih modern dalam versi terbaru produk mereka. Jika Anda menginstal XMLSpy versi lama, mungkin tidak mendukung format XQUERY. Versi terbaru XMLSpy harus mendukung semua format file yang kompatibel dengan versi perangkat lunak yang lebih lama.
Langkah 3. Tetapkan XMLSpy ke file XQUERY
Setelah menginstal XMLSpy (versi terbaru) pastikan itu disetel sebagai aplikasi default untuk membuka file XQUERY. Proses mengasosiasikan format file dengan aplikasi default mungkin berbeda secara detail tergantung pada platform, tetapi prosedur dasarnya sangat mirip.
Langkah 4. Pastikan file XQUERY lengkap dan bebas dari kesalahan
Jika masalah masih terjadi setelah mengikuti langkah 1-3, periksa apakah file XQUERY valid. Kemungkinan file tersebut rusak dan karenanya tidak dapat diakses.
1. Periksa file XQUERY apakah ada virus atau malware
Jika terjadi bahwa XQUERY terinfeksi virus, ini mungkin penyebab yang mencegah Anda mengaksesnya. Pindai file XQUERY serta komputer Anda dari malware atau virus. File XQUERY terinfeksi malware? Ikuti langkah-langkah yang disarankan oleh perangkat lunak antivirus Anda.
2. Periksa apakah file tersebut corrupt atau rusak
Jika file XQUERY dikirimkan kepada Anda oleh orang lain, minta orang ini untuk mengirim ulang file tersebut kepada Anda. Akan Memiliki suatu kondisi bahwa file tersebut Tidak dapat dibuka karena tidak disalin dengan benar ke disk dan tidak lengkap. Saat mengunduh file dengan ekstensi XQUERY dari internet, mungkin terjadi kesalahan yang mengakibatkan file tidak lengkap. Coba unduh file lagi.
3. Pastikan Anda memiliki hak akses yang sesuai
Terkadang untuk mengakses file, pengguna harus memiliki hak administratif. Beralih ke akun yang memiliki hak istimewa yang diperlukan dan coba buka file Format Kode Sumber XQuery lagi.
4. Periksa apakah sistem Anda dapat menangani XMLSpy
Jika sistem dalam beban berat, mungkin tidak dapat menangani program yang Anda gunakan untuk membuka file dengan ekstensi XQUERY. Dalam hal ini tutup aplikasi lain.
5. Pastikan sistem operasi dan driver Anda mutakhir
Versi terbaru dari program dan driver dapat membantu Anda memecahkan masalah dengan file Format Kode Sumber XQuery dan memastikan keamanan perangkat dan sistem operasi Anda. Mungkin file XQUERY bekerja dengan baik dengan perangkat lunak yang diperbarui yang mengatasi beberapa bug sistem.
Apa itu file XQUERY?
Ekstensi file XQUERY dapat dikaitkan dengan beberapa jenis file. Namun, paling sering, file dengan ekstensi seperti itu dikaitkan dengan format Format Kode Sumber XQuery. File XQUERY didukung oleh Mac OS, sistem operasi Windows. File XQUERY adalah salah satu file File Pengembang , sama seperti 1205 dari file lain yang ditemukan di database informasi file kami. Pencipta Format Kode Sumber XQuery adalah Kelompok Kerja Query XML W3C. Program yang dapat membuka file XQUERY adalah misalnya TextMate. Software ini dirilis oleh MacroMates Ltd. Namun, Anda juga dapat menggunakan aplikasi lain, misalnya Microsoft XML Notepad, XMLSpy, Stylus Studio.
Pengantar Transformasi XQuery
XQuery membantu dalam query data XML dari dokumen XML. XQuery menggunakan dan memperluas XPath untuk membantu menavigasi dan mengekstrak elemen dan atribut dari dokumen XML. Service Bus menggunakan XQuery untuk mengimplementasikan logika bisnisnya. Bus Layanan memanfaatkan sumber daya XQuery untuk berbagai aktivitas, seperti transformasi, pemilihan data, evaluasi kondisi, dan manipulasi data. Bus Layanan sepenuhnya mendukung XQuery 1.0. Ini termasuk fitur opsional seperti modul. XQuery 2004 yang lebih lama juga didukung.
Peta transformasi XQuery menggambarkan pemetaan antara dua tipe data. Peta XQuery menggambarkan pemetaan antara dokumen XML dengan skema yang berbeda. Menggunakan XQuery, Service Bus dapat memproses dokumen XML dan mengubah data dokumen dari satu skema XML ke skema XML lainnya, memungkinkan pertukaran data antar aplikasi yang menggunakan skema berbeda. Anda dapat melakukan manipulasi dan transformasi data yang kompleks menggunakan XQuery. Misalnya, Anda dapat memetakan skema pesanan pembelian masuk ke skema faktur keluar.
Anda menggunakan ekspresi XQuery untuk membuat konten data untuk variabel konteks pesan (atau bagian dari variabel konteks pesan) selama eksekusi alur pesan. Anda dapat menggunakan Test Console secara langsung di XQuery Expression Editor untuk menguji definisi ekspresi. Demikian pula, Anda menggunakan kondisi XQuery untuk mengevaluasi kondisi Boolean dalam alur pesan. Anda dapat menggunakan Konsol Pengujian secara langsung di Editor Kondisi XQuery untuk menguji definisi kondisi.
Editor dan Pemeta JDeveloper
Pemeta XQuery di JDeveloper adalah alat grafis yang memungkinkan Anda menentukan pemetaan antara elemen akar skema, bagian pesan WSDL, atau pesan WSDL. Elemen akar skema dapat berasal dari file skema XSD atau file WSDL, tetapi hanya pesan WSDL yang berisi satu bagian pesan yang dapat dipetakan secara langsung. Setelah Anda membuat pemetaan XSLT di JDeveloper, Anda dapat mengunggah .xslfile yang dihasilkan oleh pembuat peta ke sumber daya XSLT di Konsol Bus Layanan Oracle.
![]()
![]()
![]()
![]()
![]()
Tur Terpandu Untuk Tutorial XQuery
Tur Terpandu Untuk Tutorial XQuery – XQuery didefinisikan dalam model data formal, bukan dalam teks XML.
Tur Terpandu Untuk Tutorial XQuery

zorba-xquery – Setiap masukan ke kueri adalah turunan dari model data, dan keluaran dari setiap kueri adalah turunan dari model data.
Dalam model data XQuery, setiap dokumen direpresentasikan sebagai pohon simpul. Jenis node yang mungkin terjadi adalah: document, element , atribut, teks, name space , instruksi pemrosesan, dan komentar. Setiap node memiliki identitas node unik yang membedakannya dari node lain bahkan dari node lain yang identik.
Selain node, model data memungkinkan nilai atom , yang merupakan nilai tunggal yang sesuai dengan tipe sederhana yang didefinisikan dalam Rekomendasi W3C, “Skema XML, Bagian 2” SCHEMA, seperti string, Boolean, desimal, bilangan bulat, float dan ganda, dan tanggal.
Jenis sederhana ini dapat terjadi di dokumen apa pun yang terkait dengan Skema XML W3C. Seperti yang akan kita lihat nanti, kita juga dapat merepresentasikan beberapa tipe sederhana secara langsung sebagai literal dalam bahasa XQuery, termasuk string, integer, double, dan desimal.
Baca Juga : Pengembangan Aplikasi Web Dengan XQuery
Sebuah barang adalah simpul tunggal atau nilai atom. Serangkaian item dikenal sebagai urutan. Di XQuery, setiap nilai adalah urutan, dan tidak ada perbedaan antara satu item dan urutan yang panjangnya satu. Urutan hanya dapat berisi node atau nilai atom; mereka tidak dapat berisi urutan lain.
Node pertama dalam dokumen apa pun adalah node dokumen, yang berisi seluruh dokumen. Node dokumen tidak sesuai dengan apa pun yang terlihat di dokumen; itu mewakili dokumen itu sendiri. Node elemen, node komentar, dan node instruksi pemrosesan terjadi dalam urutan di mana mereka ditemukan dalam XML (setelah perluasan entitas).
Node elemen terjadi sebelum anakanak mereka node elemen, node teks, node komentar, dan instruksi pemrosesan yang dikandungnya. Atribut tidak dianggap anakanak dari suatu elemen, tetapi mereka memiliki posisi yang ditentukan dalam urutan dokumen: Mereka muncul setelah elemen di mana mereka ditemukan, sebelum anakanak dari elemen. Urutan relatif dari node atribut bergantung pada implementasi. Dalam urutan dokumen, setiap node terjadi tepat satu kali, jadi menyortir node dalam urutan dokumen menghilangkan duplikat.
Menemukan Node dengan Ekspresi Jalur di XQuery
Di XQuery, ekspresi jalur digunakan untuk menemukan node dalam data XML. Ekspresi jalur XQuery diturunkan dari XPath 1.0 dan identik dengan ekspresi jalur XPath 2.0. Fungsionalitas ekspresi jalur terkait erat dengan model data yang mendasarinya. Kami mulai dengan beberapa contoh yang menyampaikan intuisi di balik ekspresi jalur, kemudian menentukan bagaimana mereka beroperasi dalam kaitannya dengan model data.
Operator yang paling umum digunakan dalam ekspresi jalur menemukan node dengan mengidentifikasi lokasinya dalam hierarki pohon. Ekspresi jalur terdiri dari serangkaian satu atau lebih langkah, dipisahkan oleh garis miring, /, atau garis miring ganda, //. Setiap langkah dievaluasi ke urutan node. Misalnya, perhatikan ekspresi berikut:
doc(“books.xml”)/bib/book
Ekspresi ini membuka books.xml menggunakan fungsi doc() dan mengembalikan simpul dokumennya, menggunakan /bib untuk memilih elemen bib di bagian atas dokumen, dan menggunakan /book untuk memilih elemen buku di dalam elemen bib. Ekspresi jalur ini berisi tiga langkah. Buku yang sama dapat ditemukan dengan kueri berikut, yang menggunakan garis miring ganda, //, untuk memilih semua elemen buku yang terdapat dalam dokumen, terlepas dari tingkat di mana mereka ditemukan:
Jalur tersebut dimulai dengan simpul akar dokumen, tetapi bagaimana simpul ini diidentifikasi ditentukan oleh implementasi. Untuk setiap / dalam ekspresi jalur, XQuery mengevaluasi ekspresi di sisi kiri dan mengembalikan simpul yang dihasilkan dalam urutan dokumen; jika hasilnya berisi sesuatu yang bukan simpul, kesalahan jenis akan muncul.
Setelah itu, XQuery mengevaluasi ekspresi di sisi kanan / sekali untuk setiap node kiri, menggabungkan hasil untuk menghasilkan urutan node dalam urutan dokumen; jika hasilnya berisi sesuatu yang bukan simpul, kesalahan jenis akan muncul. Ketika ekspresi kanan dievaluasi, node kiri yang sedang dievaluasi dikenal sebagai node konteks.
Ekspresi langkah yang mungkin terjadi di sisi kanan a / adalah sebagai berikut:
NameTest , yang memilih node elemen atau atribut berdasarkan namanya. String sederhana ditafsirkan sebagai nama elemen; kita telah melihat bib NameTest , yang mengevaluasi ke elemen bib yang merupakan anak dari simpul konteks. Jika nama diawali dengan karakter @ (diucapkan “at”), maka NameTest mengevaluasi atribut node konteks yang memiliki nama tertentu. Misalnya, doc(“books.xml”)/bib/book/@year mengembalikan atribut tahun dari setiap buku. NameTest mendukung namespace dan wildcard, yang akan dibahas nanti di bagian ini.
KindTest , yang memilih instruksi pemrosesan, komentar, simpul teks, atau simpul apa pun berdasarkan jenis simpulnya . KindTest yang digunakan untuk memilih jenis simpul tertentu terlihat seperti fungsi dengan nama yang sama dengan jenis simpul: instruksipemrosesan(), komentar(), teks(), dan simpul().
Ekspresi yang menggunakan “sumbu” eksplisit bersama dengan NameTest atau KindTest untuk memilih node dengan hubungan struktural tertentu ke node konteks. Jika buku NameTest memilih elemen buku, maka anak::buku memilih elemen buku yang merupakan anak dari simpul konteks; keturunan::buku memilih elemen buku yang merupakan turunan dari simpul konteks; atribut::buku memilih atribut buku dari simpul konteks; self::book memilih simpul konteks jika itu adalah elemen buku, keturunanataudiri::buku memilih simpul konteks atau turunannya jika itu adalah elemen buku, dan induk::buku memilih induk dari simpul konteks jika itu adalah elemen buku. Sumbu eksplisit tidak sering digunakan di XQuery.
Sebuah PrimaryExpression , yang mungkin literal, panggilan fungsi, nama variabel, atau ekspresi kurung. Ini dibahas di bagian selanjutnya dari tutorial ini.
Bekerja dari kiri ke kanan, XQuery pertamatama mengevaluasi fungsi input, doc(“books.xml”), mengembalikan simpul dokumen, yang menjadi simpul konteks untuk mengevaluasi ekspresi di sisi kanan garis miring pertama. Ekspresi tangan kanan ini adalah bib, sebuah NameTest yang mengembalikan semua elemen bernama bib yang merupakan anak dari node konteks. Hanya ada satu elemen bib, dan itu menjadi simpul konteks untuk mengevaluasi buku ekspresi, yang pertamatama memilih semua elemen buku yang merupakan anakanak dari simpul konteks dan kemudian menyaringnya untuk mengembalikan hanya elemen buku pertama.
Menggabungkan dan Merestrukturisasi Node di XQuery
Kueri di XQuery sering menggabungkan informasi dari satu atau lebih sumber dan menyusunnya kembali untuk membuat hasil baru. Bagian ini berfokus pada ekspresi dan fungsi yang paling umum digunakan untuk menggabungkan dan merestrukturisasi data XML.
Ekspresi FLWOR
Ekspresi FLWOR, diucapkan “ekspresi bunga,” adalah salah satu ekspresi paling kuat dan umum di XQuery. Mereka mirip dengan pernyataan SELECTFROMWHERE dalam SQL. Namun, ekspresi FLWOR tidak didefinisikan dalam tabel, baris, dan kolom; sebagai gantinya, ekspresi FLWOR mengikat variabel ke nilai dalam klausa for dan let, dan menggunakan ikatan variabel ini untuk membuat hasil baru. Kombinasi dari ikatan variabel yang dibuat oleh klausa for dan let dari ekspresi FLWOR disebut tuple.
![]()
![]()
![]()
![]()
![]()

Pengembangan Aplikasi Web Dengan XQuery
Pengembangan Aplikasi Web Dengan XQuery – XQuery dikenal luas sebagai bahasa query untuk XML. Dalam domain pengembangan aplikasi webdi mana tumpukan teknologi klasik adalah database relasional yang dapat diakses melalui SQL yang dipasangkan dengan salah satu dari beberapa bahasa pemrograman populer (Java, bahasa .NET, Perl, PHP, Python, Ruby, dll.)ada jauh kurangnya kesadaran bahwa XQuery sebenarnya adalah bahasa pemrograman fungsional yang lengkap.
Pengembangan Aplikasi Web Dengan XQuery

zorba-xquery – Bahkan yang kurang dikenali adalah fakta bahwa XQuery, dengan jumlah terbatas dari ekstensi yang disediakan implementasi, dapat berfungsi dalam konteks pengembangan web baik sebagai bahasa kueri basis data dan bahasa pemrograman sisi server.
Saat menjelaskan XQuery kepada pengembang web atau manajer proyek yang terbiasa dengan tumpukan teknologi klasik, tergoda untuk mendefinisikan XQuery dengan cara yang dapat dengan mudah dipahami oleh seseorang dalam konteks itu: XQuery adalah untuk database XML seperti SQL untuk database relasional. Analogi yang lumrah ini pada awalnya tampak cukup berbahaya, tetapi sebenarnya menyesatkan dan kontra-produktif jika tidak segera dikualifikasikan dan diperluas. Mendefinisikan XQuery sebagai bahasa kueri untuk XML adalah kebenaran tetapi tidak keseluruhan kebenaran.
Baca Juga : Contoh Catatan Untuk Algoritme Perluasan Query
Bila Anda memiliki data dalam bentuk XML yang perlu dikirimkan dalam beberapa cara di web, menggunakan XQuery sebagai bahasa pemrograman sisi server memiliki keuntungan praktis yang signifikan. Setelah menjelaskan secara singkat keuntungan tersebut, makalah ini akan memaparkan teknik untuk mengembangkan aplikasi web di XQueryteknik yang dapat mengurangi kompleksitas dan membantu pengembang menghasilkan kode portabel yang terorganisir dengan baik, dapat diuji, yang akan relatif mudah untuk dibangun dan dipelihara dari waktu ke waktu.
Keuntungan XQuery untuk pengiriman web konten XML
XQuery secara khusus dirancang untuk bekerja erat dengan data XML secara asli. Tidak perlu menyediakan pemetaan antara data dan bahasa pemrograman, seperti “pemetaan objek-relasional” yang secara inheren diperlukan ketika bekerja dalam bahasa pemrograman berorientasi objek dalam hubungannya dengan database relasional. Padahal, kebutuhan akan pemetaan semacam itu tidak terbatas pada data relasional; sejenis pemetaan analogsebut saja “pemetaan dokumen-objek”sama-sama diperlukan saat menggunakan bahasa berorientasi objek untuk bekerja dengan data dalam bentuk XML.
Apakah relasional atau berbasis XML, model data masih harus diterjemahkan atau dipetakan ke fasilitas dan kemampuan bahasa pemrograman. Yang satu tidak dirancang secara inheren untuk bekerja dengan yang lain, dan faktanya data dan bahasa bertabrakan dalam “benturan paradigma” , menghasilkan apa yang disebut “ketidakcocokan impedansi” . Kesenjangan antara data dan bahasa ini harus dijembatani, menambahkan lapisan kompleksitas ke tumpukan teknologi aplikasi web. Dengan XQuery, tidak ada kesenjangan bahasa data dan oleh karena itu tidak ada jembatan.
Jika Anda tidak membutuhkan jembatan, maka Anda tidak memerlukan kerangka kerja pengembangan web (Ruby on Rails, CakePHP, Django, dll.) untuk menyediakannya. Meskipun kerangka kerja semacam itu biasanya menyediakan layanan selain pemetaan relasional objek (perancah, templating, dll, semua hal dipertimbangkan, menghindari kerangka kerja ini sebenarnya memberikan keuntungan nyata dengan sepenuhnya menghindari lapisan kompleksitas yang dapat kerangka kerja hanya menyembunyikan, tidak menghilangkan . Kerangka kerja semacam itu tidak hanya mengunci pengembang ke dalam asumsi dan persyaratan yang didukung kerangka kerja, tetapi juga selalu berkembang seiring waktu, terkadang dengan cepat.
Cepat atau lambat menjadi perlu untuk mengupgrade kerangka itu sendiri, baik karena ada alasan kuat (seperti fitur baru atau perbaikan bug yang diperlukan) atau karena ada kebutuhan mutlak (seperti ketidakcocokan antara kerangka dan perubahan lingkungan, seperti versi yang lebih baru dari server database, bahasa pemrograman atau sistem operasi). Kompleksitas teknologi yang melekat dan beberapa bagian yang bergerak dari kerangka kerja pengembangan web tertentu pada akhirnya dapat menempatkan pengembang ke dalam catatan rilis, peningkatan, fitur yang tidak digunakan lagi, dan ketidakcocokanyang semuanya menambah waktu yang dihabiskan hanya untuk pemeliharaan daripada pemfaktoran ulang yang disengaja atau pengembangan fungsionalitas baru atau yang ditingkatkan.
Sebaliknya, spesifikasi inti terkait XMLtermasuk XQuery dan spesifikasi yang menyertai dan mendukungnyatelah terbukti sangat stabil. Evolusi mereka telah ditandai tidak hanya oleh pembaruan yang jarang tetapi juga oleh kompatibilitas ke belakang tingkat tinggi. dan inkompatibilitassemuanya menambah waktu yang dihabiskan hanya untuk pemeliharaan daripada pemfaktoran ulang yang disengaja atau pengembangan fungsionalitas baru atau yang ditingkatkan.
Sebaliknya, spesifikasi inti terkait XMLtermasuk XQuery dan spesifikasi yang menyertai dan mendukungnyatelah terbukti sangat stabil. Evolusi mereka telah ditandai tidak hanya oleh pembaruan yang jarang tetapi juga oleh kompatibilitas ke belakang tingkat tinggi. dan inkompatibilitassemuanya menambah waktu yang dihabiskan hanya untuk pemeliharaan daripada pemfaktoran ulang yang disengaja atau pengembangan fungsionalitas baru atau yang ditingkatkan.
Sebaliknya, spesifikasi inti terkait XMLtermasuk XQuery dan spesifikasi yang menyertai dan mendukungnyatelah terbukti sangat stabil. Evolusi mereka telah ditandai tidak hanya oleh pembaruan yang jarang tetapi juga oleh kompatibilitas ke belakang tingkat tinggi. spesifikasi inti terkait XMLtermasuk XQuery dan spesifikasi yang menyertai dan mendukungnyatelah terbukti sangat stabil.
Evolusi mereka telah ditandai tidak hanya oleh pembaruan yang jarang tetapi juga oleh kompatibilitas ke belakang tingkat tinggi. spesifikasi inti terkait XMLtermasuk XQuery dan spesifikasi yang menyertai dan mendukungnyatelah terbukti sangat stabil. Evolusi mereka telah ditandai tidak hanya oleh pembaruan yang jarang tetapi juga oleh kompatibilitas ke belakang tingkat tinggi.
Teknik untuk pengembangan aplikasi web dengan XQuery
Memanfaatkan MVC
Terlepas dari kelemahan kerangka kerja pengembangan web yang baru saja dijelaskan, ada satu fitur umum yang sama relevannya untuk pengembangan web XQuery seperti halnya bahasa lainnya: pemanfaatan MVC (model, tampilan, pengontrol). Ada banyak sumber daya yang tersedia dengan berbagai kedalaman, dari buku hingga posting blog, yang menggambarkan MVC, termasuk dan terutama dalam domain pengembangan aplikasi web, di mana penggunaan MVC telah menjadi sangat populer sejak munculnya Ruby on Rails. Masalahnya adalah bahwa sebagai sebuah konsep, MVC bersifat umum dan cukup fleksibel untuk memungkinkan banyak kemungkinan variasi ketika konsep tersebut dipraktikkan.
Berbagai metodologi telah berkembang biak, meninggalkan seluruh gagasan tentang MVC tampak agak misterius bagi yang belum tahudan bagi yang sudah diinisiasi, dalam hal ini. (Seperti pepatah, tanyakan kepada lima pengembang web bagaimana mereka menggunakan MVC dan Anda akan mendapatkan enam jawaban yang berbeda.) MVC biasanya disebut “arsitektur”, tetapi istilah itu sudah terlalu terbebani dan karenanya tidak mencerahkan. Namun, banyak dari kebingungan ini tidak perlu, Jika untuk saat ini kita mengesampingkan variasi dan elaborasi MVC, beberapa prinsip inti tetap ada. Model memahami bagaimana data direpresentasikan (dimodelkan) dan menangani interaksi database. Tampilan membangun presentasi data kepada pengguna. Pengendali menerima masukan dan merespons sesuai dengan itu, memanfaatkan model dan tampilan untuk melakukannya.
Model
Model bertanggung jawab untuk berinteraksi dengan database; tidak ada komponen lain yang boleh membuat, membaca, memperbarui, atau menghapus data (pikirkan “tidak ada CRUD di luar model”). Dalam pengertian ini ia bertindak sebagai semacam API (atau seperti objek yang dienkapsulasi, dalam istilah berorientasi objek), yang dipanggil oleh modul lain tanpa perlu mengetahui apa pun tentang database atau cara berinteraksi dengannya. Idealnya pemisahan masalah ini diberlakukan hingga seseorang dapat menukar server basis data yang mendasarinya dengan yang berbeda tanpa menyentuh kode apa pun di pengontrol atau tampilan.
Melihat
Peran tampilan adalah untuk menyediakan presentasi, baik untuk keterbacaan manusia atau mesin. Misalnya, pola yang sangat umum (digunakan oleh semua jenis aplikasi web dari Amazon hingga Zappos) adalah untuk menyediakan pencarian, yang mengarah ke hasil pencarian, yang mengarah ke halaman tingkat item yang menampilkan semua informasi yang relevan untuk item tertentu. Dalam pendekatan ini, halaman beranda yang berisi formulir pencarian, halaman hasil pencarian, dan halaman tingkat item adalah tampilan terpisah, masing-masing diimplementasikan sebagai modul pustaka XQuery sendiri (semuanya dapat dikelompokkan dalam satuviewsdirektori). Dalam aplikasi web yang dirancang untuk ditampilkan di browser, sebagian besar tampilan akan mengembalikan dokumen HTML, sedangkan layanan web mungkin mengembalikan data sebagai JSON atau XML, yang tetap merupakan tampilan.
![]()
![]()
![]()
![]()
![]()

Contoh Catatan Untuk Algoritme Perluasan Query
Contoh Catatan Untuk Algoritme Perluasan Query – Teknik penambangan data dan algoritme yang terinspirasi dari alam saat ini merupakan salah satu teknik komputasi lunak yang paling sering digunakan untuk penemuan pengetahuan, pengoptimalan, dan kecerdasan komputasi.
Contoh Catatan Untuk Algoritme Perluasan Query

zorba-xquery – Dalam artikel ini, kami mengusulkan penerapan teknik penambangan data dan algoritme yang terinspirasi oleh alam untuk mengatasi masalah menghasilkan query yang diperluas secara optimal dalam pengambilan informasi web.
Kami pertamatama menggunakan teknik data mining untuk mengelompokkan kandidat istilah ekspansi serupa ke dalam cluster. Selanjutnya, kami menggunakan algoritme yang terinspirasi oleh alam untuk mengekstrak kandidat istilah ekspansi dari cluster dan menghasilkan query yang diperluas yang sesuai. Berikut beberapa contoh catatan untuk algoritme perluasan query :
Baca Juga : XQuery, Bahasa Query Masa Depan
Ekspansi Query Berbasis Algoritma yang Terinspirasi Kelelawar untuk Pengambilan Informasi Web Medis.
Dengan meningkatnya jumlah data medis yang tersedia di Web, mencari informasi kesehatan telah menjadi salah satu topik yang paling banyak dicari di Internet. Pasien dan orangorang dari berbagai latar belakang sekarang menggunakan mesin pencari Web untuk memperoleh informasi medis, termasuk informasi tentang penyakit tertentu, perawatan medis atau nasihat profesional. Meskipun demikian, karena kurangnya pengetahuan medis, banyak orang awam mengalami kesulitan dalam membentuk pertanyaan yang tepat untuk mengartikulasikan pertanyaan mereka, yang menganggap permintaan pencarian mereka tidak tepat karena penggunaan kata kunci yang tidak jelas.
Penggunaan pertanyaan yang ambigu dan tidak jelas iniuntuk menggambarkan kebutuhan pasien telah mengakibatkan kegagalan mesin pencari Web untuk mengambil informasi yang akurat dan relevan. Salah satu metode yang paling alami dan menjanjikan untuk mengatasi kelemahan ini adalah Query Expansion . Dalam makalah ini, pendekatan orisinal berdasarkan Algoritma Kelelawar diusulkan untuk meningkatkan efektivitas pengambilan dari perluasan Query di bidang medis. Berbeda dengan literatur yang ada, pendekatan yang diusulkan menggunakan Algoritma Kelelawar untuk menemukan Query yang diperluas terbaik di antara sekumpulan kandidat Query yang diperluas , sambil mempertahankan kompleksitas komputasi yang rendah. Selain itu, pendekatan baru ini memungkinkan penentuan panjang yang diperluaspertanyaan secara empiris. Hasil numerik pada MEDLINE, database informasi medis online, menunjukkan bahwa pendekatan yang diusulkan lebih efektif dan efisien dibandingkan dengan baseline.
Paradigma Ekspansi Query Kata Kunci Berdasarkan Rekomendasi dan Interpretasi dalam Basis Data Relasional
Tersedia Teks Lengkap Karena ambiguitas dan ketidaktepatan Query kata kunci dalam database relasional, penelitian tentang perluasan Query kata kunci telah menarik perhatian luas. Metode perluasan Query yang ada mengekspos niat Query pengguna sampai batas tertentu, tetapi kebanyakan dari metode tersebut tidak dapat menyeimbangkan presisi dan ingatan. Untuk mengatasi masalah ini, pendekatan ekspansi Query dua langkah baru diusulkan berdasarkan rekomendasi Query dan interpretasi Query . Pertama, algoritma rekomendasi probabilistik dikemukakan dengan membangun matriks kesamaan istilah dan model Viterbi. Kedua, dengan menggunakan algoritma translasi rangkap tiga dan algoritma konstruksi subgraf Query , kata kunci Query diterjemahkan ke subgraf Query dengan informasi struktural dan semantik. Akhirnya, hasil eksperimen pada kumpulan data dunia nyata menunjukkan efektivitas dan rasionalitas metode yang diusulkan.
Apakah perluasan Query membatasi pembelajaran kita? Perbandingan ekspansi berbasis sosial dengan ekspansi berbasis konten untuk pertanyaan medis di internet.
Mencari informasi medis secara online adalah kegiatan umum. Meskipun telah terbukti bahwa membentuk Query yang baik itu sulit, alat saran Query Google , sejenis perluasan Query , bertujuan untuk memfasilitasi pembentukan Query . Namun, tidak diketahui bagaimana perluasan ini , yang didasarkan pada apa yang dicari orang lain, memengaruhi pengumpulan informasi komunitas online. Untuk mengukur dampak ekspansi query berbasis sosial , penelitian ini membandingkannya dengan ekspansi berbasis konten , yaitu apa yang sebenarnya ada dalam teks.
Kami menggunakan 138.906 pertanyaan medis dari Koleksi Sesi Pengguna AOL dan memperluasnya menggunakan metode Pelengkapan Otomatis Google (berbasis sosial) dan konten Google Web Corpus (berbasis konten). Kami mengevaluasi kekhususan dan ambiguitas istilah perluasan untuk Query trigram . Kami juga melihat dampak pada hasil aktual menggunakan keragaman domain dan jarak edit perluasan . Hasil penelitian menunjukkan bahwa metode berbasis sosial memberikan istilah ekspansi yang lebih tepat serta istilah yang kurang ambigu. Query yang diperluas tidak berbeda secara signifikan dalam keragaman saat diperluas menggunakan metode berbasis sosial (ratarata 6,72 domain berbeda yang ditampilkan dalam sepuluh hasil pertama) vs. metode berbasis konten (ratarata 6,73 domain berbeda).
Meningkatkan pengambilan informasi biomedis dengan kombinasi linier dari berbagai teknik perluasan Query .
Pengambilan literatur biomedis menjadi semakin kompleks, dan ada kebutuhan mendasar untuk sistem temu kembali informasi yang canggih. Program Information Retrieval (IR) menjelajahi materi tidak terstruktur seperti dokumen teks dalam cadangan data besar yang biasanya disimpan di komputer. IR terkait dengan representasi, penyimpanan, dan organisasi item informasi, serta akses. Dalam IR salah satu masalah utama adalah menentukan dokumen mana yang relevan dan mana yang tidak sesuai dengan kebutuhan pengguna. Di bawah rezim saat ini, pengguna tidak dapat membuat Query dengan tepatdengan cara yang akurat untuk mengambil bagian data tertentu dari cadangan data yang besar. Sistem pencarian informasi dasar menghasilkan hasil pencarian berkualitas rendah.
Dalam sistem yang kami usulkan untuk makalah ini, kami menyajikan teknik baru untuk menyempurnakan pencarian Pencarian Informasi untuk lebih mewakili kebutuhan informasi pengguna untuk meningkatkan kinerja pencarian informasi dengan menggunakan teknik ekspansi Query yang berbeda dan menerapkan kombinasi linier di antara mereka, di mana kombinasi linear antara dua hasil ekspansi pada satu waktu. Perluasan Query memperluas Query penelusuran , misalnya, dengan mencari sinonim dan memberi bobot ulang pada istilah aslinya. Mereka memberikan hasil penelusuran khusus yang jauh lebih terfokus daripada Query penelusuran dasar . Kinerja pengambilan diukur dengan beberapa varian MAP (Mean Average Precision) dan menurut hasil eksperimen kami, kombinasi hasil terbaik dari perluasan Query meningkatkan dokumen yang diambil dan mengungguli baseline kami sebesar 21,06%, bahkan mengungguli penelitian sebelumnya oleh 7,12 %. Kami mengusulkan beberapa teknik perluasan Query dan kombinasinya (secara linier) untuk membuat Query pengguna lebih mudah dikenali oleh mesin telusur dan untuk menghasilkan hasil penelusuran berkualitas lebih tinggi.
RCQGA: Optimasi Query Rantai RDF Menggunakan Algoritma Genetika
Penerapan teknologi Web Semantik dalam lingkungan Electronic Commerce menyiratkan kebutuhan akan alat pendukung yang baik. Mesin Query cepat diperlukan untuk Query data dalam jumlah besar yang efisien, biasanya direpresentasikan menggunakan RDF. Kami fokus pada pengoptimalan kelas khusus Query SPARQL , yang disebut Query rantai RDF . Untuk tujuan ini, kami merancang algoritme genetika yang disebut RCQGA yang menentukan urutan penggabungan yang perlu dilakukan untuk evaluasi Query rantai RDF yang efisien . Pendekatan ini dibandingkan dengan algoritma optimasi dua fase , yang sebelumnya diusulkan dalam literatur. Semakin kompleks kueriadalah, semakin RCQGA mengungguli tolok ukur dalam kualitas solusi, waktu eksekusi yang dibutuhkan, dan konsistensi kualitas solusi. Ketika algoritme dibatasi oleh batas waktu, kinerja keseluruhan RCQGA dibandingkan dengan tolok ukur akan semakin meningkat.
Studi empiris tentang SAJQ ( Algoritma Pengurutan untuk Gabung Query )
Full Text Available Sebagian besar query yang diterapkan pada sistem manajemen database (DBMS sangat bergantung pada kinerja algoritma sorting yang digunakan . Selain memiliki algoritma sorting yang efisien , sebagai fitur utama, stabilitas algoritma tersebut merupakan fitur utama yang diperlukan dalam melakukan Query DBMS Dalam makalah ini, kami mempelajari Algoritma Penyortiran baru untuk Gabung Query (SAJQ yang memiliki keunggulan efisien dan stabil. Algoritma yang diusulkan mengambil keuntungan dari penggunaan algoritma mwaymergedalam meningkatkan kompleksitas waktunya.
SAJQ melakukan operasi pengurutan dalam kompleksitas waktu O(nlogm, di mana n adalah panjang array input dan m adalah jumlah subarray yang digunakan dalam pengurutan. Array input yang tidak diurutkan dengan panjang n diatur ke dalam m subarray yang diurutkan Algoritma mwaymerge menggabungkan m subarray yang diurutkan ke dalam array yang diurutkan keluaran akhir. Algoritma yang diusulkan menjaga stabilitas kunci tetap utuh.
Bukti analitis telah dilakukan untuk membuktikan bahwa, dalam kasus terburuk, yang diusulkan algoritma memiliki kompleksitas O(nlogm. Juga, serangkaian percobaan telah dilakukan untuk menyelidiki kinerja algoritma yang diusulkan . Hasil eksperimen menunjukkan bahwa algoritma yang diusulkanmengungguli algoritme Pengurutan Stabil lainnya yang dirancang untuk Query berbasis gabungan .
![]()
![]()
![]()
![]()
![]()

XQuery, Bahasa Query Masa Depan
XQuery, Bahasa Query Masa Depan – XQuery kemungkinan akan menjadi bahasa yang dominan untuk kueri data dari sebagian besar sumber data.Meskipun dirancang untuk kueri data XML, Anda bisa menggunakan XQuery untuk mengikat data dari beberapa sumber data.
XQuery, Bahasa Query Masa Depan

zorba-xquery – Dalam hal itu jauh lebih kuat daripada SQL, yang perlahan tapi pasti akan diganti sebagai bahasa query utama.Anda mungkin berpikir saya membuat pernyataan yang cukup berani di sini mengingat dominasi SQL saat ini dengan banyak dialeknya, dan fakta bahwa XQuery belum menjadi Rekomendasi Konsorsium W3 (W3C).
Baca Juga : Edukasi tentang pemeliharaan dan perawatan komputer
Namun, sudah ada beberapa implementasi berdasarkan draft kerja, termasuk salah satunya oleh Microsoft yang disertakan dalam .NET Framework. Implementasi ini menunjukkan kekuatan XQuery yang luar biasa. Tapi apa sebenarnya XQuery itu?
XML Query, singkatnya XQuery, adalah bahasa query baru yang saat ini sedang dikembangkan oleh W3C. Ini dirancang untuk menanyakan dokumen XML menggunakan sintaks seperti SQL. Kemampuan XQuery jauh melampaui SQL, karena XML (dan dengan demikian XQuery) tidak terikat pada struktur tabel dan relasi yang kaku. XML dapat mewakili sejumlah besar model data. Selanjutnya kueri XQuery dapat mengembalikan data dari beberapa dokumen di lokasi yang berbeda. XSLT memiliki kemampuan serupa, tetapi banyak orang TI akan menganggap XQuery lebih mudah dipahami, terutama administrator basis data yang akrab dengan SQL.
Anda dapat menggunakan XQuery untuk mengekstrak dokumen XML dari representasi fisik atau virtual data XML. Contoh yang terakhir adalah SQLXML (disediakan dalam Microsoft SQL Server 2000), yang memungkinkan Anda mengekstrak data dari database SQL Server yang diformat sebagai XML menggunakan protokol HTTP. Sistem apa pun yang mengekspos XML melalui HTTP adalah sumber data potensial untuk XQuery. Perancang XQuery berharap bahwa XQuery dapat bertindak sebagai bahasa kueri terpadu untuk penyimpanan data apa pun, termasuk file XML, database XML, dan penyimpanan data non-XML. Dengan proliferasi sistem dan data yang digabungkan secara longgar yang berasal dari belahan dunia lain, kinerja kueri multi-dokumen akan menjadi masalah, terutama jika Anda hanya memerlukan sejumlah kecil data dari dokumen besar. Versi XQuery yang akan datang dapat mengatasi masalah ini dengan mendistribusikan kueri melalui sistem yang ditanyakan.
Meskipun XQuery masih merupakan draf yang berfungsi, ia sudah memiliki dukungan luas. Ada beberapa aplikasi yang menyediakan kemampuan untuk melakukan kueri menggunakan XQuery. Microsoft telah mengisyaratkan bahwa rilis berikutnya dari SQL Server (nama kode Yukon) akan memberikan dukungan untuk XQuery juga, dan IBM dan Oracle kemungkinan akan menawarkan beberapa jenis dukungan XQuery setelah XQuery mencapai status Rekomendasi W3C .
Dasar-dasar XQuery
XQuery menggunakan empat kata kunci utama untuk membuat ekspresi kueri: FOR, LET, WHERE, dan RETURN. Kata kunci ini biasanya digunakan bersama untuk mengkueri data dan membuat hasil. Orang-orang yang akrab dengan XQuery yang membangun ekspresi menggunakan kata kunci ini menyebut ini sebagai ekspresi FLWR (atau ekspresi FLoWeR). Dalam istilah teknis, ekspresi ini adalah konstruktor elemen? Anda menggunakannya untuk membangun (urutan) elemen. Mari kita mulai dengan ekspresi sederhana untuk menunjukkan cara kerjanya.
XQuery di .NET
Mengeksekusi kueri terdiri dari dua langkah: memuat dokumen, dan mengeksekusi kueri di atas dokumen yang dimuat. Dokumen yang Anda muat disimpan dalam objek XQueryNavigatorCollection. Anda dapat memuat file secara langsung ke dalam koleksi, atau memuat XQueryDocument menggunakan objek XmlReader, dan dari sana menggunakan metode CreateNavigator(untuk membuat objek XQueryNavigator yang Anda simpan dalam koleksi. Hasilnya adalah kumpulan dokumen yang dioptimalkan untuk XQuery. Saat Anda menjalankan kueri, Anda mengumpankan koleksi ke objek XQueryExpression yang mengeksekusi kueri. Keuntungan dari pendekatan ini adalah kemampuan untuk bekerja dengan dokumen fisik dan virtual karena dokumen dimuat ke dalam koleksi menggunakan alias. Untuk merujuk ke dokumen dalam kueri, Anda merujuk ke alias. Jika ini tidak memungkinkan, Anda hanya dapat mengerjakan dokumen fisik, karena, misalnya, tidak ada cara untuk menangani data dalam database.
Mengapa Bahasa Kueri Lain untuk XML?
Jika Anda sudah familiar dengan teknologi XML, Anda tahu bahwa XSLT sudah menyajikan bahasa yang bisa Anda gunakan untuk query dan mengubah data XML. Jadi mengapa menggunakan bahasa lain, dan bahasa yang bukan XML itu sendiri? Sebenarnya tidak ada satu jawaban untuk pertanyaan ini, tetapi satu alasan utama adalah bahwa XSLT membutuhkan cara berpikir yang asing bagi banyak orang. XSLT bekerja berdasarkan pola dan pencocokan. Meskipun sangat kuat, ini berarti Anda tidak benar-benar menanyakan data tertentu, tetapi sebenarnya “berharap” data akan masuk dalam pola Anda. Menulis kueri kurang lebih berlawanan, karena Anda menentukan data mana yang ingin Anda miliki, lalu mengoperasikannya. Ini juga cara kerja SQL, dan dapat dimengerti oleh siapa saja yang bekerja dengan database. XQuery memiliki banyak kesamaan dengan SQL,
Mengapa kita Membutuhkan XQuery?
Penggunaan XQuery dapat dipahami dengan baik oleh pernyataan yang disebutkan di bawah ini yang diterbitkan di bawah W3C oleh J.Robie ketika XQuery diperkenalkan. “Misi dari proyek XML Query adalah untuk menyediakan fasilitas query yang fleksibel untuk mengekstrak data dari dokumen nyata dan virtual di World Wide Web, oleh karena itu akhirnya menyediakan interaksi yang dibutuhkan antara dunia Web dan dunia database. Pada akhirnya, kumpulan file XML akan diakses seperti database”.
Penggunaan utama XQuery adalah untuk mengekstrak data dari database XML. Itu juga mampu mengekstraksi data dari database relasional yang menyimpan data XML. XML mengikuti struktur hierarki yang berisi node di dalam node. Node ini ditangani oleh bahasa query XML. Ini juga digunakan untuk mengubah data dengan cepat. Itu berarti kami dapat memperbarui data saat transmisi itu sendiri. Fungsionalitas ini, ketika ditambahkan dengan bahasa kueri, menyediakan kekuatan yang cukup untuk XQuery untuk menangani sebagian besar data XML melalui web.
Bagaimana XQuery Bekerja?
Kita perlu memiliki prosesor yang membantu kita dalam merender penggunaan XQuery. Kita dapat menggunakan Saxon-HE (banyak digunakan). Karena ini adalah perangkat lunak sumber terbuka, kami dapat mengunduhnya dari internet bersama dengan buku panduan untuk instalasi. Kita perlu mengatur classpath seperti yang kita lakukan untuk instalasi JAVA. Ini mendukung versi terbaru XPath, XQuery, dan XSLT (Extensible Stylesheet Language Transformations). Kita dapat memiliki database untuk query atau memiliki file XML untuk mengekstrak data dari.
Ia bekerja di sekitar konsep FLWOR. FLWOR adalah singkatan dari From, let, where, order by, result. 5 kata ini membentuk keseluruhan kueri. Kita dapat menulis secara sederhana ke logika kompleks menggunakan 5 kata kunci ini di XQuery. Kami memilih sumber data dari kata kunci “dari”. “Let” digunakan untuk mendeklarasikan dan menginisialisasi variabel yang akan digunakan saat kita membuat loop kontrol. “Order by” digunakan untuk mengatur data dalam urutan menaik atau menurun. “Where” digunakan untuk membatasi ruang lingkup dengan mendeklarasikan kondisi spesifik dari penarikan data. Ini berfungsi seperti kata kunci “dari” dalam SQL. “Kembali” akan menandai akhir kueri dan kata kunci ini akan mentransfer kontrol keluar dari kueri bersama dengan output.
![]()
![]()
![]()
![]()
![]()

Edukasi tentang pemeliharaan dan perawatan komputer
Edukasi tentang pemeliharaan dan perawatan komputer – Apakah Anda memerlukan perawatan perbaikan komputer? Tentu saja ya! Kadang-kadang, sebagai contoh, remah-remah, debu, dan partikel lain yang jatuh di antara komputer dan bagian-bagiannya dapat menumpuk seiring waktu dan membahayakan PC Anda.
Edukasi tentang pemeliharaan dan perawatan komputer

zorba-xquery – Itu sebabnya kami mengendurkan tombol dengan menyemprotkan udara bertekanan ke keyboard. Dan kemudian dihapus dengan penyedot debu bertekanan rendah.
Baca Juga : Panduan Lengkap Tentang XQuery untuk Pemula, Pembelajar Menengah & Lanjutan
Bahan pembersih plastik yang diaplikasikan pada permukaan kunci dengan kain digunakan untuk menghilangkan akumulasi minyak. Serta kotoran dari kontak berulang dengan ujung jari pengguna.Jika ini tidak cukup untuk keyboard yang sangat kotor, tombol akan dihapus secara fisik. Memungkinkan pembersihan individu yang lebih terfokus, atau untuk akses yang lebih baik ke area di bawahnya.
Permukaan atas mouse dilap dengan pembersih plastik untuk menghilangkan kotoran yang menumpuk akibat kontak dengan tangan. Dan seperti pada keyboard, permukaan bawah juga dibersihkan untuk memastikan dapat meluncur dengan bebas.
Dan jika itu adalah mouse mekanis , trackball akan dikeluarkan. Tidak hanya untuk membersihkan bola itu sendiri tetapi juga untuk mengikis kotoran dari pelari yang merasakan pergerakan bola. Dan bisa menjadi gelisah atau macet jika terhalang oleh kotoran. Akhirnya, bagian permukaan dibersihkan dengan disinfektan.
Apa itu Pemeliharaan Perbaikan Komputer?
Pada dasarnya, pemeliharaan perbaikan komputer adalah proses mengidentifikasi, mengatasi masalah, dan menyelesaikan masalah komputasi. Selain itu, ini juga mencakup kegiatan lain untuk mengelola masalah pada perangkat keras komputer, perangkat lunak, atau bahkan ethernet yang rusak .Penting untuk disadari, solusi layanan pemeliharaan perbaikan pada komputer merupakan suatu bidang yang banyak meliputi prosedur, alat dan tekniknya . Digunakan, khususnya, untuk pemeliharaan perbaikan komputer yang terkait dengan masalah komputasi umum.
Dengan kata lain, pemeliharaan perbaikan komputer juga dikenal sebagai perbaikan PC. Dan, oleh karena itu, ini adalah praktik menjaga komputer dalam kondisi kerja yang baik dari perbaikan.Semua orang yang memiliki komputer tahu saat panik ketika hard drive mogok. Dan bagi para pebisnis, hal itu biasanya terjadi ketika mereka sedang menghadapi tenggat waktu. Misalnya, komputer yang berisi akumulasi debu dan kotoran mungkin tidak berfungsi dengan baik.Sederhananya, karena debu dan kotoran akan menumpuk akibat pendinginan udara. Dan filter apa pun yang digunakan untuk mengurangi ini memerlukan layanan dan/atau perubahan reguler.
Tip umum untuk perawatan perbaikan komputer
Pada akhirnya, setelah pemecahan masalah, bagian perangkat keras ditambahkan atau diganti jika kesalahan terdeteksi.Ini biasanya memerlukan peralatan dan aksesori khusus untuk membongkar dan memasang kembali komputer. pada perbaikan komputer ada masalah yang sering terjadi karena pembaruan sistem ataupun konfigurasinya .
Kesalahan aplikasi yang diinstal, virus, dan masalah perangkat lunak lainnya juga diidentifikasi. Demikian pula, perbaikan komputer untuk masalah jaringan/Internet memungkinkan komputer untuk sepenuhnya memanfaatkan layanan jaringan dan yang tersedia. Padahal, A+ adalah sertifikasi vendor-netral untuk memperbaiki dan memelihara komputer.Di bawah ini Anda akan melihat tip umum untuk pemeliharaan perbaikan komputer yang berhasil. Dan pertama, Anda harus mulai dengan cara memperbaiki kesalahan sederhana yang mungkin dimiliki komputer Anda;
1. Blue screen
Kesalahan umum pertama yang biasanya dimiliki komputer adalah kesalahan layar biru. Dan untuk hal ini, orang harus:
Pahami Blue screen
Waktu yang lebih sulit akan datang ketika PC Anda menolak memuat data apa pun. Data ini akan mendapatkan akses ke PC Anda melalui celah di sistem operasi atau di perangkat lunak aplikasi.Untuk memperbaiki PC Anda dan menghilangkan program-program ini, Anda harus memindai komputer Anda dengan program anti-virus yang tepat.
Periksa kesalahan registri
Registry Windows menyimpan informasi mengenai pengaturan perangkat keras dan perangkat lunak pada komputer Anda. Jika program jahat merusak Registry, itu dapat menyebabkan kesalahan layar biru.Masalah ini dapat diperbaiki secara manual, dengan mengedit Registry secara langsung, atau dengan perangkat lunak pihak ketiga. Terutama, yang dapat memeriksa dan memperbaiki Registry yang rusak. Selalu buat cadangan Registry sebelum mencoba mengeditnya.
Pembekuan Komputer
Komputer Anda mungkin membeku karena masalah perangkat lunak atau perangkat keras. Dengan demikian, Anda harus mencari tahu alasan yang tepat untuk mengetahui cara terbaik untuk memperbaiki kesalahan. Anda harus memperhatikan apakah masalah dimulai atau tidak saat Anda menyambungkan periferal perangkat keras apa pun, seperti pemindai atau printer.
Setelah itu, mungkin karena konflik driver. Jika yang terakhir terjadi setelah Anda merakit hard drive baru, mungkin karena daya yang tidak tepat atau suhu yang terlalu tinggi. Jadi, Anda harus mengikuti langkah-langkah yang saya sebutkan di sini untuk menangani masalah ini:
Setel ulang komputer untuk sementara waktu
Jika Anda meninggalkan komputer sepanjang waktu, Anda dapat memperbaiki kesalahan dengan mencabutnya, lalu menunggu minimal 30 detik, dan memasangnya kembali.Hanya dengan mematikan daya komputer ke motherboard, perangkat keras di komputer Anda akan dapat mengatur ulang dan menghapus memori.
Tentukan suhu komputer Anda
Penting bagi Anda untuk melihat ke dalam untuk suhu PC. Anda harus memperhatikan diri Anda sendiri bahwa setiap kali Anda perlu membuka lemari komputer Anda, Anda harus mematikan PC dan mencabutnya. Jika rambut Anda panjang, Anda harus mengikatnya ke belakang.Kemudian lagi, Anda harus melepas perhiasan yang mungkin menghalangi. Padahal, Anda juga harus menghindari mengenakan pakaian yang dapat menghasilkan banyak statis yang dapat menyebabkan intermiten dan merusak perangkat keras, sehingga lebih sulit untuk mengatasi kesalahan.
Periksa kabinet komputer & sasis logam
Jika benar-benar panas, pasti akan ada masalah termal. Anda harus memeriksa kipas depan dan belakang dengan hati-hati dan meniup debunya. Anda juga harus membersihkan kipas secara teratur. Sebelum Anda membersihkan komputer, Anda harus ingat untuk mematikannya.Faktanya, jika Anda memiliki lebih dari hard drive di komputer, Anda harus menghindari menginstalnya.
Terutama tepat setelah saling bergesekan di dalam sasis karena hal ini dapat membuat mereka lebih mudah mengalami kegagalan pada panas.Poin penting lainnya, sebelum menutup kasing, Anda harus ingat untuk memeriksa semua kabel untuk memastikan semuanya masih terpasang. Jika Anda perlu mengatur ulang stik memori atau kartu video, Anda tidak boleh memberikan tekanan berat pada motherboard karena ini akan menjadi rusak.
Pesanan beton / periksa disk
Akses Pemulihan Sistem Saat Mulai> Program> Aksesori> Alat Sistem> SistemHard disk Anda adalah gudang informasi, jadi ketika digunakan untuk waktu yang lama mungkin akan berantakan dan tidak merata; ini memperlambat kinerja komputer Anda. Oleh karena itu, gunakan utilitas Windows Anda CHKDSK untuk memindai dan menghapus bad sector secara teratur.Ini adalah cara pencegahan terbaik untuk menjaga kesehatan komputer.
Periksa drive disk perangkat Anda
Sering kali saat melakukan Pembaruan Windows, sistem Anda mungkin mengunduh dan menginstal driver yang salah, yang dapat menyebabkan komputer membeku. Anda dapat memeriksa status driver dari Device Manager. Cabut perangkat USB Anda, jika terhubung.Nyalakan komputer Anda dan lihat apakah itu berfungsi. Jika ya, bagus; jika tidak, Anda dapat memulihkan komputer Anda ke konfigurasi sebelumnya. Pemulihan Sistem akan mengembalikan sistem Anda ke set driver sebelumnya.
![]()
![]()
![]()
![]()
![]()