zorba-xquery – Memanipulasi data teks (yaitu, string) dalam Extensible Markup Language (XML) menggunakan fungsi string di XQuery, bahasa kueri XML, dan BaseX, mesin database XML dan prosesor XQuery. Tutorial ini mencakup dasar-dasar cara menggunakan fungsi string XQuery dan memanipulasi data teks dengan BaseX.Kami menggunakan kumpulan data terbatas kata-kata bahasa Inggris sebagai data teks untuk dievaluasi dan dimanipulasi, dan saya telah membuat inti GitHub dari input XML dan kode XQuery untuk digunakan dengan tutorial ini.
Memanipulasi Data Teks XML Menggunakan Fungsi String XQuery
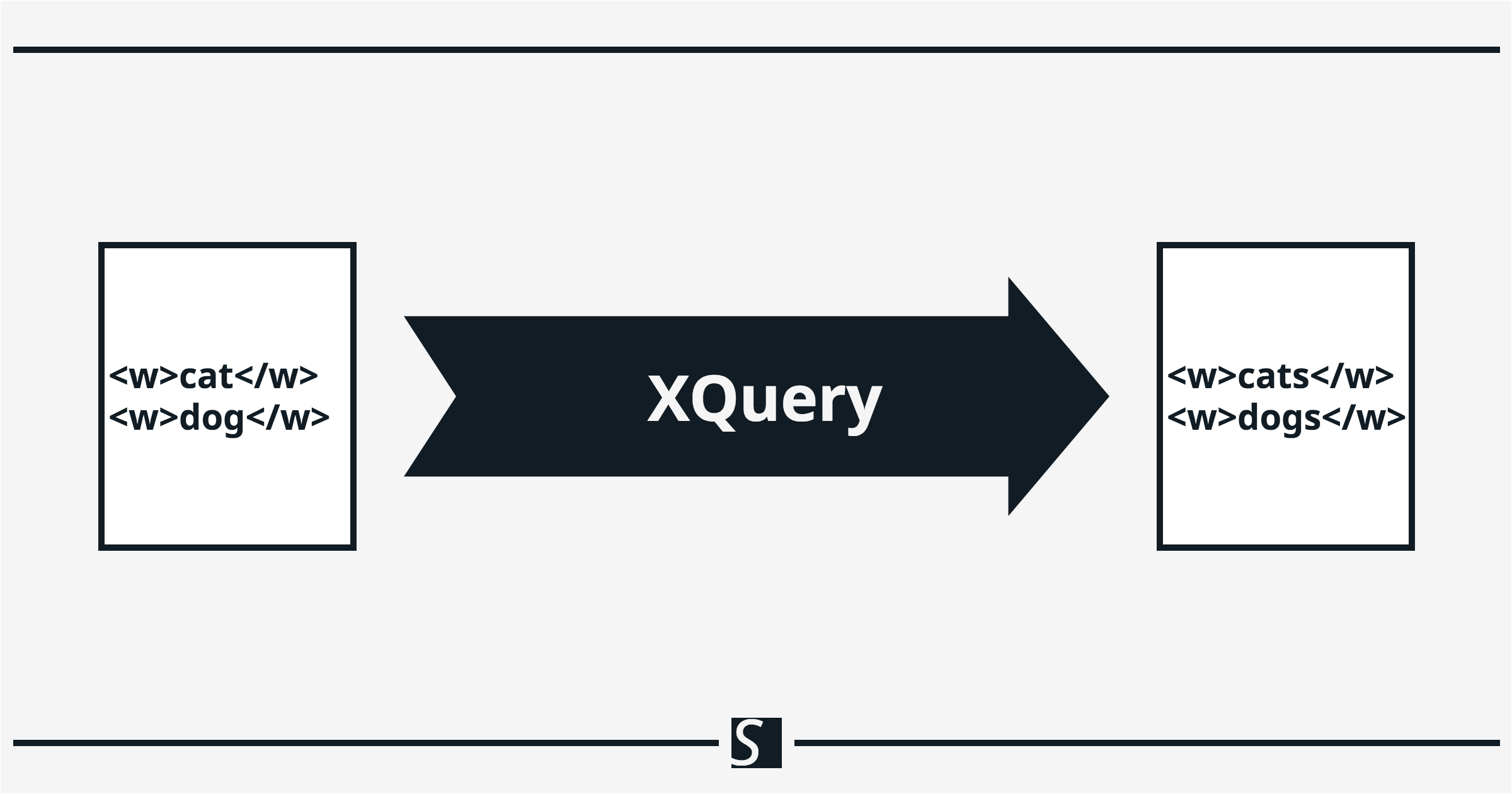
– Membuat dan menggabungkan string dengan XQuery
Memanipulasi Data Teks XML Menggunakan Fungsi String XQuery – Concatenation adalah proses yang menghubungkan dua atau lebih string independen teks bersama-sama untuk membuat satu string besar teks. Kita akan mulai dengan membuat string, dan cara sederhana untuk membuat string adalah dengan klausa let XQuery. Misalnya, kode XQuery biarkan $word := “book” mendeklarasikan variabel $word dan menetapkannya sebagai buku nilai string. Dari sini, kita dapat membuat variabel kedua dengan tanda nilai string dan menggabungkan dua variabel string untuk membuat string baru dengan fungsi string XQuery fn:concat.
Dalam kode XQuery kami di atas, kami menggunakan klausa let untuk mendeklarasikan dan menetapkan nilai string ke variabel $word1, $word2, dan $compound-word. Berbeda dengan nilai $word1 dan $word2, nilai $compound-word adalah hasil dari suatu fungsi. Dalam hal ini, $word1 dan $word2 adalah argumen dari fn:concat, yang kita ikat ke variabel $compound-word. Menjalankan kode XQuery kami di atas di BaseX mengembalikan nilai kata majemuk:
Bookmark
Kode XQuery kami di atas mengembalikan hasil yang diinginkan untuk kata majemuk seperti ‘bookmark’ karena fn:concat() menempatkan karakter awal dari argumen kedua, $word2, segera setelah karakter terakhir dari argumen pertama, $word1. Namun, mengubah nilai $word1 dan $word2 dapat mengembalikan hasil yang tidak diinginkan.
– Memanipulasi data teks XML dengan XQuery
Kita mulai dengan mengikat lokasi file data XML eksternal kita ke $uri. Kami kemudian mengikat dokumen yang terletak di $uri, compound-words.xml, ke $compound-words. Terakhir, kami mengembalikan $compound-words untuk melihat XML kami.Sekarang kami telah berhasil mengambil data teks XML eksternal kami, kami dapat memanipulasinya. Tujuan kami adalah membuat bentuk jamak dari setiap kata majemuk dalam kumpulan data kami, dan kami melakukannya dengan mengulang $kata majemuk dengan klausa for dan menggunakan fn:concat() untuk menggabungkan setiap kata majemuk dengan akhiran jamak, ‘- S’.
Klausa pengembalian dalam kode XQuery kami di atas rumit, berisi klausa for dan klausa pengembalian lainnya. Ini memungkinkan kita untuk mengembalikan elemen XML <compounds>, yang berisi elemen <word> untuk setiap elemen <word> dalam input kita di XPath $compound-words/compounds/word/text(). Selanjutnya, klausa for kita mengikat variabel $compound-word ke konten teks dari setiap elemen <word> di input kita, dan kemudian menggunakan fn:concat() dengan argumen $compound-word dan $plural-suffix untuk membuat teks konten dari setiap elemen <word> dalam output kami.
– Menggunakan ekspresi bersyarat untuk mengevaluasi data teks XML dengan XQuery
Seperti sebelumnya, kode XQuery kami di atas mengembalikan hasil yang tidak diinginkan untuk kata majemuk seperti ‘Gubernur Jenderal’, yang ditemukan di file data XML eksternal kami more-compound-words.xml. Untuk mengembalikan hasil yang diinginkan, kita menggunakan ekspresi kondisional dan fungsi string XQuery fn:contains() untuk menentukan apakah konten teks dari setiap elemen <word>, $compound-word, berisi spasi. Jika $compound-word mengandung spasi maka fn:contains($compound-word, $delimiter) mengembalikan nilai true. Dari sini berdasarkan dataset kami dengan mendeklarasikan variabel $compound-head dan menggunakan fn:substring-before() untuk menetapkan nilai string dari kata paling kiri di setiap compound (yaitu, semua karakter sebelum $delimiter di $compound- kata). Terakhir, kita ganti $compound-head dengan hasil fn:concat($compound-head, $plural-suffix) menggunakan fn:replace().
Baca Juga : Zorba Xquery Yang Digunakan Untuk Alat Bantu Pencarian Data
Sementara beberapa kata majemuk bahasa Inggris mengandung spasi, yang lain seperti ‘ibu mertua’ mengandung tanda hubung. Kata majemuk tambahan ini terdapat dalam file data XML eksternal kami even-more-compound-words.xml. Untuk mengakomodasi dataset yang berisi dua pembatas ini, kami mengikat spasi dan tanda hubung ke $delimiter sebagai urutan string: let $delimiter := (” “, “-“). Dalam urutan baru kami, $delimiter diberi nilai string spasi dan $delimiter diberi nilai string tanda hubung. Selanjutnya, kami menambahkan kondisi kedua ke ekspresi kondisional kami. Seperti sebelumnya, kita menggunakan fn:contains untuk memeriksa apakah $compound-word berisi pembatas, tapi kali ini kita mencari $delimiter dan $delimiter. Selain itu, kita memerlukan kondisi kedua ketika $majemuk-kata mengandung $delimiter karena kita perlu membedakan kata majemuk seperti ‘mother-in-law’ dari ‘in-law’ sebelum kita membubuhkan akhiran jamak, ‘-s’ . Untuk melakukannya, kita menggunakan fungsi string XQuery fn:tokenize dan fn:count. Kode XQuery fn:tokenize membagi string kita $compound-word menjadi urutan string pada batas $delimiter, jadi input ‘mother-in-law’ mengembalikan a urutan:
Kami memutuskan untuk membuat fungsi kami sendiri dan membersihkan output kami, sehingga beberapa revisi terakhir untuk kode XQuery kami tetap ada. Pertama, kami memindahkan kode XQuery kami di atas ke dalam fungsi bernama local:form-plural-compound(), yang menerima argumen $compound-words sebagai node() dan mengembalikan node(). Kedua, kami mengurutkan hasil kami menurut abjad menggunakan klausa pesanan demi di dalam klausa for kami. Kami menggunakan fungsi string XQuery fn: huruf kecil () saat memesan data kami, jika tidak, string yang dimulai dengan huruf kapital akan muncul sebelum string dimulai dengan huruf kecil dan hasil kami tidak akan abjad: diurutkan berdasarkan fn: huruf kecil ($kata majemuk). Ketiga, kita menambahkan atribut singular ke setiap elemen <word> dan menetapkan nilai $compound-word untuk menyimpan data input kita. Terakhir, kita mengikat dokumen yang terletak di $uri ke $dataset dan meneruskannya sebagai argumen ke fungsi baru kita: local:form-plural-compound.
– Memanipulasi Data XML di SQL Server
Ketika pengembang basis data rata-rata diwajibkan untuk memanipulasi XML, baik merobek-robeknya ke dalam format relasional, atau membuatnya dari SQL, hal itu sering dilakukan ‘di lengan panjang’. Sayang sekali, karena penggunaan teknik yang efektif yang melampaui dasar-dasar dapat menghemat banyak kode, dan cenderung berkinerja lebih baik.
Seringkali menjadi perlu untuk membuat, menghancurkan, menggabungkan, atau menyusun kembali data XML, agar sesuai dengan tujuan tertentu. Terkadang persyaratan bisnis menentukan bahwa fragmen XML harus digabungkan, sementara permintaan lain meminta dokumen atau bidang XML untuk dihancurkan dan nilainya diimpor ke dalam tabel. Terkadang, Data XML harus dibuat langsung dari tabel yang ada. SQL Server menyediakan banyak alat terkait XML, tetapi bagaimana kita bisa tahu mana yang harus digunakan, dan kapan? Mari kita periksa beberapa tugas ini yang memerlukan manipulasi XML, menggunakan contoh database AdventureWorks2012 (Versi AdventureWorks lainnya akan berfungsi dengan baik, tetapi mungkin ada variasi dalam skema data dan/atau tabel).
a. Membuat XML
Kita perlu menyertakan bidang BusinessEntityID dan beberapa kolom nama-data dalam struktur XML baru. Perhatikan bahwa ada kolom XML yang ada di tabel bidang Demografi. SQL Server menyediakan opsi XML untuk digunakan dengan klausa FOR, memungkinkan metode yang mudah untuk mengubah data tabel menjadi node XML. FOR XML dapat mengambil argumen yang berbeda mari kita cari tahu mana yang cocok untuk kita. Argumen ELEMENTS menyebabkan setiap nilai dibuat sebagai elemen simpul. Sekarang kita memiliki simpul terpisah untuk setiap nilai, dan simpul akar pembungkus. Dalam contoh pertama, XML yang dihasilkan memiliki data yang sama, tetapi nilainya dirender sebagai atribut.
b. Ruang Nama XML
Sementara ini mengembalikan hasil robekan yang kita inginkan, deklarasi namespace berulang memperluas ukuran kueri kita – karena kita mengembalikan empat nilai node XML, kita harus mendeklarasikan namespace empat kali. Mendeklarasikan namespace diperlukan karena struktur XML Demografi menggunakan XML yang diketik, data XML-nya dikaitkan dengan skema XML. Namun, kita dapat menggunakan klausa WITH XML NAMESPACES untuk mendeklarasikan namespace XML sebagai gantinya ini memungkinkan kita untuk mendeklarasikan namespace hanya sekali untuk seluruh blok kode.
![]()
![]()
![]()
![]()
![]()