Arsitektur Komponen Prosesor Zorba Xquery – Artikel ini menjelaskan sejumlah proyek terkait XQuery. Tujuannya adalah untuk menunjukkan bahwa XQuery adalah alat yang berguna untuk banyak skenario aplikasi yang berbeda. Secara khusus, artikel ini mencoba untuk mengoreksi mitos umum bahwa XQuery hanyalah bahasa kueri dan SQL adalah bahasa kueri yang lebih baik.

Sebaliknya, XQuery adalah bahasa pemrograman yang lengkap untuk aplikasi dan layanan Web. Lebih lanjut, tulisan ini mencoba mengoreksi mitos kedua bahwa XQuery lambat. artikel ini memberikan gambaran umum tentang teknik implementasi dan pengoptimalan XQuery yang canggih dan membahas satu prosesor XQuery open-source tertentu, Zorba, secara lebih rinci.
Di antara yang lainnya, artikel ini menyajikan zorba-xquery Benchmark Service yang membantu praktisi dan vendor prosesor XQuery untuk menemukan masalah kinerja pada prosesor XQuery.
Komponen Prosesor Zorba Xquery
XQuery berusia lebih dari sepuluh tahun. Asalnya kembali ke lokakarya theQL 1998 yang diadakan di Boston. Meskipun W3C baru-baru ini merilis rekomendasi XQuery 1.0, draf kerja publik pertama diterbitkan pada tahun 2001. Awalnya, XQuery dirancang sebagai bahasa aquery untuk XMLdata. Tujuannya adalah untuk memberikan kekuatan ekspresif dari bahasa kueri seperti SQL dan, sebagai tambahan, untuk mendukung operasi khusus XML seperti navigasi dalam data hierarki.
Sejak awal, fitur penting dari XQuery adalah kemampuan untuk memproses data tanpa tipe. Selain itu, XQuery telah dirancang untuk mendukung pemrosesan data dengan cepat atau data yang disimpan di sistem file; tidak perlu data disimpan dalam database.
Pada tahap awal, zorba-xquery cukup populer baik di industri maupun akademisi. Pada awal dekade ini, XML dan, sebagai konsekuensinya, XQuery, menjadi topik hangat di konferensi data utama (SIGMOD dan VLDB). Selain itu, semua vendor database utama mengintegrasikan XQuery ke dalam produk database mereka dan membuat XQuery, seperti SQL, salah satu cara yang mungkin untuk mengekstrak data dari database. Berdasarkan umpan balik pengguna, Oracle memiliki setidaknya 7000 pelanggan yang menggunakan fitur ini.
Bisa dibilang, XQuery paling sukses di middle-tier. Di middle-tier, XQuery dapat melayani beberapa tujuan. Salah satu contoh yang menonjol adalah transformasi dan perutean pesan XML. Contoh lain adalah integrasi informasi perusahaan. Contoh ketiga melibatkan manipulasi dan pemrosesan data konfigurasi yang direpresentasikan dalam XML. Jelas, arsitektur prosesor XQuery yang dirancang untuk tingkat menengah dapat sangat bervariasi dari arsitektur prosesor XQuery yang secara khusus dirancang untuk database.
Tren baru-baru ini yang berpotensi mengubah adopsi XQuery adalah bahwa XQuery sedang diperluas dengan sejumlah fitur tambahan. Fitur-fitur ini melampaui transformasi pesan dan pemrosesan XMLquery yang awalnya dirancang untuk XQuery. Terutama, Fasilitas Pembaruan XQuery dan Teks Lengkap XQuery (untuk pengambilan informasi XML) telah dirancang dan telah mencapai status rekomendasi oleh W3C. Selain itu, Fasilitas Skrip XQuery dan fitur tambahan seperti pemrosesan jendela untuk streaming data sedang dalam pengembangan. Dengan semua ekstensi ini, XQuery lebih dari sekadar bahasa kueri; itu telah menjadi alat yang sangat kuat untuk pengembangan segala jenis aplikasi pemrosesan data.
Tujuan dari artikel ini adalah untuk meninjau kembali keuntungan dari XQuery dan mengklarifikasi beberapa mitos tentang XQuery yang dibuat pada hari-hari awal XQuery ketika, memang, XQuery hanyalah sebuah bahasa query. Lebih lanjut, artikel ini memberikan gambaran tentang teknik-teknik XQueryimplementation dan menyajikan sejumlah aktivitas terkait XQuery yang dilakukan oleh sekelompok orang di berbagai tempat (akademisi dan industri) yang pernah disebut (dalam istilah bersahabat) “ekstremis XML” oleh Jim Abu-abu. Aktivitas ini termasuk penerapan dua mesin XQuery open source, Zorba dan MXQuery.
Sisa dari artikel ini disusun sebagai berikut. Bagian 2 meninjau kembali pro dan kontra XQuery. Bagian 3 memberikan gambaran umum tentang teknik implementasi XQuery. Bagian 4 menyajikan desain prosesor XQuery tertentu, Zorba. Bagian 5 mencantumkan beberapa proyek yang dilakukan dengan Zorba. Bagian 6 berisi kesimpulan dan jalan untuk pekerjaan di masa depan.
Apa Itu Xquery ?

Bagian ini meninjau kembali XML dan XQuery dan mengapa kami yakin bahwa keduanya adalah alat yang berguna. Keakraban dasar dengan XML dan XQuery diasumsikan. Untuk pengenalan XQuery, pembaca yang tertarik dirujuk ke spesifikasi XQuery atau beberapa tutorial.
Mengapa XML ?
Terus terang, XML berguna karena mengurangi biaya dengan meningkatkan fleksibilitas pengelolaan data dalam berbagai cara. Secara teknis, XML adalah sintaks universal untuk membuat data bersambung. Ini universal karena dua alasan. Pertama, XML tidak bergantung pada platform; yaitu, XMLworks di semua perangkat keras dan sistem operasi. Kedua, XML didasarkan pada UNICODE sehingga mendukung semua bahasa dan taruhan alpha. Jenis fleksibilitas pertama yang disediakan XML adalah untuk memisahkan data skema.
Dengan cara ini, data dapat ada terlebih dahulu dan skema dapat ditambahkan kemudian dengan cara bayar sesuai pemakaian. Selain itu, properti ini membantu memproses data dari aplikasi lama dan data yang diarsipkan. Misalnya, XML memungkinkan untuk menghasilkan data dengan satu aplikasi sesuai dengan skema tertentu dari aplikasi itu dan untuk memproses data dengan aplikasi lain, sehingga menggunakan skema yang berbeda. Properti ini telah membuat XML menjadi format data yang menarik untuk data komunikasi (mis. , pesan atau pertukaran data).
Fleksibilitas jenis kedua muncul karena XML mampu merepresentasikan spektrum data yang besar, dari data yang sama sekali tidak terstruktur, semi-terstruktur, hingga yang sepenuhnya terstruktur. Selain itu, XML mampu merepresentasikan data, meta-data, bahkan kode yang beroperasi pada data dan meta-data tersebut. Fleksibilitas semacam ini, misalnya, menjadikanXML format data pilihan untuk data konfigurasi.
Semua keunggulan ini telah menyebabkan adopsi XML secara luas; jelas, XML akan tetap ada. Namun, XML juga mendapat kritik keras dan banyak pengembang aplikasi menghindari penggunaan XML kapan pun mereka bisa. Pertama, XML dianggap lambat, besar, dan kikuk. Artinya, data XML biasanya jauh lebih besar daripada data setara yang dikirim ulang dalam format berpemilik.
Selain itu, prosesor XML biasanya memiliki kinerja yang lebih buruk daripada prosesor yang secara khusus dirancang untuk format tertentu (berpemilik). Solusi yang mungkin untuk masalah ini adalah rekomendasi XML biner yang muncul dari W3C yang menyediakan representasi data XML yang telah diurai dan dikompresi secara universal.
Kritik kedua terhadap XML adalah karena XML dianggap menjadi rumit. Kritik ini kebanyakan ditujukan terhadap XML Schema yang memang memiliki banyak fitur yang jarang digunakan. Dalam praktiknya, penyelesaian terhadap kompleksitas ini adalah dengan menggunakan hanya fitur XML dan Skema XML yang benar-benar dibutuhkan.
Jelas, XML bukan satu-satunya sintaks untuk membuat serial data. Secara tradisional, pertukaran data antar aplikasi bisnis telah dilakukan dengan bantuan EDIFACT. EDIFACT cepat, tetapi sayangnya, ini tidak memiliki fleksibilitas XML sehingga hanya dapat diterapkan untuk sekumpulan aplikasi tertentu. Baru-baru ini, JSON telah direvisi sebagai cara untuk mempengaruhi pertukaran data di Internet.
JSON sangat populer untuk mash-up Web. Ternyata JSON setara dengan XML dengan pro dan kontra yang serupa. Faktanya, untuk tujuan artikel ini yang berfokus pada XQuery, XML dan JSON aman digunakan secara bergantian sebagai dua format data berbeda yang keduanya dapat diproses oleh XQuery.
Baca Juga : Mengenal Zorba versi 3.0 – Kratos
Jelas, XQuery memiliki banyak persaingan. Untuk aplikasi kelas apa pun, XQuery bersaing dengan sejumlah bahasa pemrograman lainnya. Misalnya, Ruby dan PHP sangat populer untuk mengembangkan aplikasi Web (sederhana) dengan cepat. Java dan .Net masih menjadi standar emas untuk aplikasi Web skala perusahaan. Sebuah survei yang membandingkan XQuery dengan bahasa pemrograman lain dan paradigma pemrograman diberikan dalam.
Mengapa XQuery ?
Adapun XML, tujuan XQuery adalah untuk mengurangi biaya. Apa XML untuk representasi data, XQuery untuk pemrosesan data dan pengembangan aplikasi intensif data. Sekali lagi, keajaiban dalam peningkatan fleksibilitas.
Jenis fleksibilitas pertama yang disediakan oleh XQuery adalah XQuery beroperasi pada semua jenis data. Secara alami, XQuery dapat memproses dataXML. Namun, seperti yang dinyatakan di bagian sebelumnya, XQuery juga mampu memproses JSON, EDIFACT, CSV, atau data yang disimpan dalam database relasional. Model pemrosesan XQuery menentukan bahwa ekspresi XQuery beroperasi pada instance model data XDM dan instance ini dapat dihasilkan dari semua jenis data dan dari semua jenis sumber data
Kedua, XQuery mewarisi semua fleksibilitas yang disediakan oleh XML. Secara khusus, XQuery dapat memproses data tanpa tipe sehingga XQuery mendukung paradigma “data first – schema later” (atau bayar sesuai penggunaan). Selain itu, XQuery adalah pilihan alami untuk memproses data yang diarsipkan, komunikasi, dan data konfigurasi yang direpresentasikan dalam XML. Lebih lanjut, XQuery mampu beroperasi pada seluruh spektrum data yang tidak terstruktur hingga terstruktur.
Untuk data tidak terstruktur, ekstensi XQueryFull-Text bisa sangat berguna. Perlu diperhatikan bahwa program XQuery dapat diserialkan menjadi XML sendiri dengan menggunakan rekomendasi XQueryX dan sebagian besar prosesor XQuery (termasuk Zorba yang dijelaskan secara rinci dalam artikel ini) mendukung fungsi yang menggunakan program XQuery sebagai parameter untuk dieksekusi.
XQuery menyediakan jenis fleksibilitas arsitektural khusus dalam pengertian bahwa XQuery dijalankan pada semua tingkatan aplikasi. Seperti yang disebutkan dalam pendahuluan, XQuery berjalan di lapisan database seperti yang telah diterapkan oleh semua vendor database utama (misalnya, IBM, Microsoft, danOracle) sebagai bagian dari produk database mereka.
Selanjutnya, XQueryruns di tingkat menengah; misalnya, sebagai bagian dari layanan perusahaan BEA atau dalam produk XQuery terpisah seperti Saxon, MXQuery, atauZorba. Akhirnya, seperti yang ditunjukkan di Bagian 5, XQuery juga berjalan di klien sebagai bagian dari plugin browser Web. Fleksibilitas ini memungkinkan untuk memindahkan kode di antara tingkatan aplikasi, sehingga mengurangi biaya operasional. Penyedia data, misalnya, dapat memilih untuk memindahkan komputasi ke klien untuk mengurangi beban di server mereka.
Mitos tentang XQuery adalah bahwa itu tidak cukup kuat untuk membangun seluruh aplikasi di XQuery dan, sebagai akibatnya, XQuery perlu disematkan ke dalam bahasa host seperti Java atau C #. Mitos ini berasal dari saat XQuery hanyalah bahasa kueri dan mitos ini didukung oleh namanya, XQuery. Melaporkan pengalaman yang diperoleh dengan mengimplementasikan aplikasi Web enter-prize sepenuhnya di XQuery. Salah satu keuntungan XQuery yang sangat berharga adalah bahwa XQuery membuatnya lebih mudah untuk menyesuaikan aplikasi Web perusahaan.
Kode aplikasi yang sama dapat diterapkan ke data dalam skema yang berbeda dengan menggunakan model data XQuerysflexible dan pendekatan XML “skema-nanti”. Misalnya, jika satu varian aplikasi menambahkan bidang ke objek bisnis tertentu, maka semua kode yang ada masih berlaku untuk objek bisnis yang diperluas (serta yang asli). Hasilnya, database XQuery dan XQuery secara alami multi-tenant dan tidak memerlukan pengangkatan beban berat seperti yang diperlukan untuk mengimplementasikan multi-tenancy dalam sistem database relasional.
Keuntungan kedua dalam mengimplementasikan seluruh aplikasi di XQuery secara tunggal adalah bahwa kode untuk, katakanlah, penanganan kesalahan dan pemeriksaan batasan integritas tidak perlu diduplikasi lintas tingkatan.
Seperti XML, XQuery dianggap oleh banyak orang sebagai lambat dan rumit. Salah satu tujuan penulis artikel ini adalah untuk mengatasi masalah ini dengan membangun prosesor XQuery berkinerja tinggi dan dengan memberikan praktik terbaik dan contoh yang menunjukkan kekuatan dan kegunaan XQuery sebagai alat pemrograman.
Apa itu XQuery ?
Seperti yang disebutkan dalam pendahuluan, XQuery adalah keluarga rekomendasi W3C. Ini memperluas XPath dan dirancang bersama denganXSLT 2.0. Sebagai rumus, XQuery dapat dikarakterisasi sebagai berikut:
XQuery = Query + Update + Fulltext +Scripting + Streaming + Libraries
Sekali lagi, tulisan ini tidak akan memberikan tutorial tentang XQuery, tetapi ada baiknya membandingkan XQuery dengan bahasa pemrograman lain. Bahasa data seperti SQL biasanya mencakup aspek “Query”, “Update”, dan berpotensi “Fulltext” dan “Streaming”. Bahasa pemrograman tujuan umum seperti Java atau C # mencakup aspek “Script-ing” dan “Libraries”. XQuery melakukan semuanya. Meskipun XQuery bukan bahasa pemrograman berorientasi objek1, XQuery sangat cocok untuk pemrograman terstruktur berskala besar dengan modul, seperti yang dibahas di bagian sebelumnya dan ditampilkan.
Kelas inJava sesuai dengan modul di XQuery. Berdasarkan pengalaman kami, programmer Java mempelajari XQuery dengan sangat cepat dan mencapai tingkat produktivitas yang sama (dan lebih tinggi) untuk aplikasi Web perusahaan dengan XQuery. Selanjutnya, seperti yang akan dibahas di Bagian 4, prosesor XQuery modern hadir dengan pustaka yang canggih dan XQuery memungkinkan pengguna untuk membuat dan menerbitkan pustaka mereka sendiri untuk digunakan kembali.
Satu kelalaian yang terlihat dalam keluarga XQuery adalah bahasa definisi data (DDL) yang memungkinkan spesifikasi batasan integritas, deklarasi skema, dan definisi desain database fisik dengan indeks. SQL, jelas, menyediakan DDL seperti itu dan DDL semacam itu juga diperlukan untuk aplikasi XQuery. Seperti yang ditunjukkan di Bagian 4, salah satu tujuan proyek Zorba adalah untuk merancang dan mendukung DDL semacam itu untuk aplikasi XQuery
Singkatnya, dapat disimpulkan bahwa XQuery mencoba menggabungkan fitur-fitur bahasa pemrograman yang ada seperti SQL, Java, atau bahkan PHP. Dengan cara ini, XQuery memungkinkan untuk mengimplementasikan aplikasi yang canggih dalam satu tingkat dan dengan teknologi seragam tunggal, sehingga menghindari ketidakcocokan impedansi dan meningkatkan fleksibilitas dan kemampuan penyesuaian. Seperti SQL, XQuery mendukung pembaruan dan kueri deklaratif; XQuery dapat menentukan kueri dan pembaruan massal yang paling baik dijalankan di dalam database.
Selain itu, XQuery mendukung pemrosesan aliran dan kueri kontinu dengan windows. Dengan demikian, XQuery dapat mendukung aplikasi yang melibatkan pemrosesan peristiwa kompleks atau pemrosesan data dari jaringan sensor. Ekstensi teks lengkapnya menjadikan XQueryjuga kandidat yang baik untuk memproses umpan data RSS dan Atom atau bentuk lain dari data tidak terstruktur dan semi-terstruktur. Lebih lanjut, XQuery memperluas XPath dan dirancang bersama dengan XSLT 2.0 in or-der untuk mendukung transformasi pesan dan perutean di perangkat tengah.
Di tingkat menengah, XQuery juga merupakan kandidat yang baik untuk integrasi informasi seperti yang ditunjukkan oleh beberapa produk EII berbasis XQuery. XQuery juga merupakan kandidat yang baik untuk mengimplementasikan aplikasi enterpriseWeb dan logika aplikasi yang canggih dengan strongtyping dan library. Dalam hal ini, XQuery bersaing dengan Java dan .Net. Selain itu, XQuery dapat digunakan sebagai bahasa skrip XQuery adalah bahasa pemrograman fungsional. Itu tidak mendukung pewarisan dan bundling metode dan data dalam kelas
Dengan data yang tidak diketik dan mungkin tidak terstruktur. XQuery juga merupakan opsi yang layak untuk mengimplementasikan mash-up dan layanan RESTful. Akhirnya, XQuery mendukung pemrograman berbasis peristiwa dari antarmuka pengguna grafis; di sini, XQuery bersaing dengan JavaScript sebagai bahasa pemrograman untuk browser Web.
Teknik Pengolahan Xquery
Arsitektur Prosesor XQuery
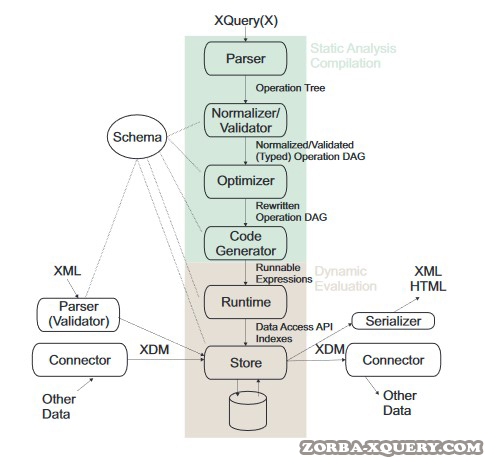
Spesifikasi XQuery menentukan model pemrosesan untuk mengevaluasi program XQuery. Model pemrosesan ini menetapkan operasi dan interaksi tertentu, tetapi tidak menentukan cara menerapkannya. Gambar 1 memberikan arsitektur generik yang diadopsi oleh sebagian besar pemroses XQuery. Arsitektur ini juga terkait dengan arsitektur yang digunakan oleh sebagian besar pemroses kueri dari sistem database relasional dan kompiler / sistem runtime dari bahasa pemrograman tujuan umum.
Perbedaan yang paling mencolok dari arsitektur database tradisional adalah penggunaan eksplisit pengurai XML atau lainnya konektor untuk memproses data dari sumber data eksternal dan menghasilkan hasil kueri yang dapat digunakan oleh aplikasi lain. Secara internal, semua data diproses sebagai contoh model data XDM. Instance AnXDM adalah urutan urutan (atau daftar) dari item di mana anitem adalah nilai atom (misalnya, integer atau string) atau node (misalnya, elemen XML atau atribut XML).
Biasanya, setiap data XML, objek JSON, atau tabel relasional dapat direpresentasikan sebagai instance XDM yang menjadikan XQuery kandidat untuk memproses salah satu jenis data ini. Jika prosesor XQuery dikaitkan dengan database, maka database tersebut akan menyimpan datanya sebagai instance XDM. Seperti dijelaskan di bawah, komponen “Store” dari proses XQuery menyediakan cara yang seragam bagi prosesor XQuery untuk mengakses semua data.
Berikut ini secara singkat merangkum komponen terpenting dari sebuah prosesor XQuery :
- Parser : Parser mengambil representasi tekstual dari program anXQuery dan menghasilkan “pohon operator” sebagai representasi internal program. Karena XQuery adalah bahasa pemrograman fungsional, setiap node operator merepresentasikan “ekspresi” dari program XQuery. Membangun parser XQuery cukup menantang karena bahasanya tidak memiliki kata kunci; fitur ini adalah bagian dari warisan XPath dari XQuery.
- Normalizer + Validator: Komponen ini memeriksa referensi ruang ton, jenis, variabel dan fungsi. Dengan menyelesaikan referensi variabel, ini secara efektif mengubah pohon operator menjadi grafik asiklik terarah. Selanjutnya, operator implisit seperti cast ditambahkan ke pohon operator menurut semantik formal XQuery . Jika pengetikan statis didukung (yang merupakan fitur opsional XQuery), informasi jenis disisipkan dan diperiksa ekspresinya.
- Pengoptimal : Seperti dalam bahasa pemrograman lainnya, tujuan pengoptimal adalah untuk mengubah pohon operator menjadi pohon operator yang setara dengan perkiraan waktu berjalan atau konsumsi sumber daya yang lebih rendah. Ada banyak sekali pendekatan dan teknik yang berbeda untuk meningkatkan kinerja program XQuery, termasuk hampir semua teknik yang diketahui dari database relasional (misalnya, pemilihan jalur akses dan pengurutan gabungan). Seperti dalam sistem database tradisional, optimasi query pada waktu kompilasi dapat didasarkan pada heuristik atau estimasi biaya.
- Pembuat Kode: Sekali lagi, seperti dalam sistem lain, kode yang dihasilkan dapat diinterpretasikan (menggunakan sistem runtime) atau dikompilasi langsung ke perangkat keras target tertentu. Kedua pendekatan tersebut dapat ditemukan di prosesor XQuery yang canggih.
- Runtime: Seperti dalam sistem database tradisional (relasional), sistem runtime prosesor XQuery biasanya diatur menggunakan model iterator. Artinya, setiap ekspresi dasar bahasa XQuery diimplementasikan sebagai it-erator dengan antarmuka yang terbuka, berikutnya, dan dekat. Sekali lagi, seperti dalam sistem database relasional tradisional, mungkin ada implementasi alternatif untuk jenis ekspresi yang sama (misalnya, algoritma gabungan yang berbeda) dan pemilihan implementasi yang paling menguntungkan dibuat oleh pengoptimal dan pembuat kode.
- Penyimpanan: Store memelihara koleksi semua instans XDM dan menyediakan antarmuka yang seragam untuk mengakses item (misalnya, node) dari instans XDM ini. Seperti yang ditunjukkan pada Gambar 1, theStore juga mengintegrasikan data dari sumber data eksternal (push and pull). Untuk melakukannya, Store berisi resolver URI dan mengambil dokumen dan koleksi yang diidentifikasi oleh URI mereka dari Internet atau database lokalnya. Store juga merupakan komponen yang menyinkronkan akses bersamaan ke data jika prosesor XQuery digunakan dalam mode multi-threaded atau beberapa instance prosesor XQuery bekerja pada data yang sama secara bersamaan. Bergantung pada skenario penggunaan (database, transformasi ad-hoc, streaming) dan fungsionalitas yang diperlukan, persyaratan penyimpanan dan pengoptimalan di Store dapat sangat bervariasi.
- Skema: Berbeda dengan database relasional, manajemen skema adalah fitur opsional dari implementasi XQuery. Namun demikian, semua skema dukungan implementasi XQuery yang serius karena informasi skema diperlukan untuk banyak aplikasi (khususnya, aplikasi perusahaan) dan dapat berguna untuk pengoptimalan.